本文首发于 vivo互联网技术 微信公众号
链接:https://mp.weixin.qq.com/s/S7MhlsZveBHRSQhq5aTIJA
作者:何志创
一般大家对数据库事务的了解可能停留在事务的ACID特性以及事务4种不同的隔离级别层面上,而对于事务 4 种不同隔离级别如何实现了解相对较少。
本文以 MySQL 数据库 InnoDB 引擎为例,为大家分析 InnoDB数据库引擎对默认的隔离级别可重复读(RR)的具体实现。
整文知识点介绍:事务4种隔离级别、不同隔离级别解决的问题、MVCC、锁的类型、加锁案例分析;阅读完整文相信大家对事务隔离级别的具体实现有了一定的认识。
一、事务的隔离级别
1、4 种隔离级别
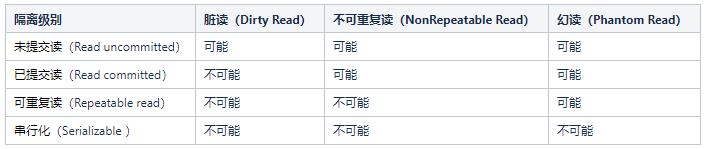
(1)未提交读(Read uncommitted):一个事务读取到其他事务未提交的数据,是级别最低的隔离机制;
(2)提交读(Read committed):一个事务读取到其他事务提交后的数据;
(3)可重复读(Repeatable read):一个事务对同一份数据读取到的相同,不在乎其他事务对数据的修改;
(4)序列化(Serializable) :事务串行化执行,隔离级别最高,牺牲了系统的并发性。
2、不同隔离级别解决的问题
若不考虑事务的隔离级别,则事务的并发会造成以下问题:
(1)脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据。
(2)不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
(3)幻读:同一事务中对同一范围的数据进行读取,结果却多出了数据或者少了数据,这就叫幻读。(如同一事务对id<10的范围进行2次查询,第一次出现id=8、9的两条数据,第二次出现id=7、8、9的3条数据)。
不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
不同的隔离级别针对上述3个问题的解决能力,如下表:
二、MVCC
上文提到 InnoDB 默认的隔离级别是可重复读(RR),InnoDB是通过MVCC(多版本并发控制)来实现可重复读的,下面为大家介绍MVCC。
1、概念
在InnoDB中,给每行增加两个隐藏字段来实现MVCC,一个用来记录数据行的创建时间,另一个用来记录行的过期时间(删除时间)。在实际操作中,存储的并不是时间,而是事务的版本号,每开启一个新事务,事务的版本号就会递增。
于是乎,默认的隔离级别(REPEATABLE READ)下,增删查改变成了这样:
(1)SELECT
-
读取创建版本小于或等于当前事务版本号,并且删除版本为空或大于当前事务版本号的记录。这样可以保证在读取之前记录是存在的。
(2)INSERT
-
将当前事务的版本号保存至行的创建版本号。
(3)UPDATE
-
新插入一行,并以当前事务的版本号作为新行的创建版本号,同时将原记录行的删除版本号设置为当前事务版本号。
(4)DELETE
-
将当前事务的版本号保存至行的删除版本号。
2、快照读和当前读
(1)快照读:读取的是快照版本,也就是历史版本;
(2)当前读:读取的是最新版本。
普通的SELECT就是快照读,而UPDATE、DELETE、INSERT、SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE是当前读。
(3)结论:如果隔离级别是REPEATABLE READ,那么在同一个事务中的所有普通select读读到的都是事务第一个读到的快照,如此实现了可重复读;而对于当前读(UPDATE、DELETE、INSERT、SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE),InnoDB 通过加锁来实现可重复读,且InnoDB 加锁同时解决了幻读问题。
三、锁的类型
InnoDB 引入以下三种锁类型:
-
Record Locks(记录锁):在索引记录上加锁,即行锁,锁住当前行。
-
Gap Locks(间隙锁):在索引记录之间加锁,或者在第一个索引记录之前加锁,或者在最后一个索引记录之后加锁。
-
Next-Key Locks:在索引记录上加锁,并且在索引记录之前的间隙加锁。它相当于是Record Locks与Gap Locks的一个结合。
假设一个索引包含以下几个值:10,11,13,20。那么这个索引的next-key锁将会覆盖以下区间:(-oo, 10]、(10, 11]、(11, 13]、(13, 20]、(20, +oo)。
MySQL InnoDB 通过间隙锁解决了幻读问题。以下通过实际的案例分析来介绍InnoDB 是如果解决幻读问题的。
四、案例分析
在对SQL进行加锁分析前,需要明确表的结构和索引类型。在不知道索引的情况下直接给出一条SQL来分析如果加锁是没有任何意义的。
以下以用户表(t_user)为例(id为主键,name为唯一索引,age为一般索引,address无索引)分析不同索引条件的加锁表现。
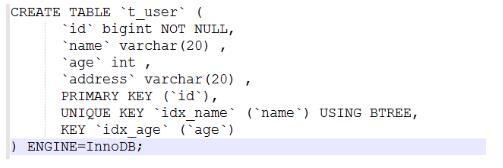
1、主键索引
例:delete from t_user where id=120;
条件为主键,此时锁住聚簇索引中对应的行记录:即Record Locks锁住id=120的行记录。
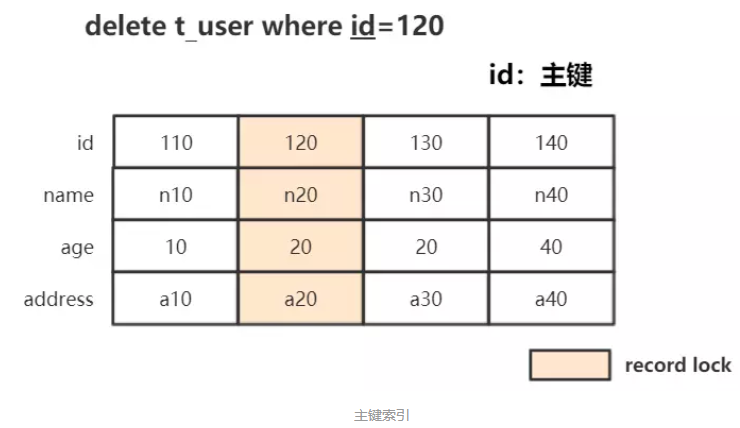
此种情况下,其他事务除了不能删除、更新此条记录外,其他插入其他行、更新其他行都行。
SQL验证:

2、唯一索引
例:delete from t_user where name='n20';
条件为唯一索引,锁住索引记录,同时锁住聚簇索引中的对应行记录:
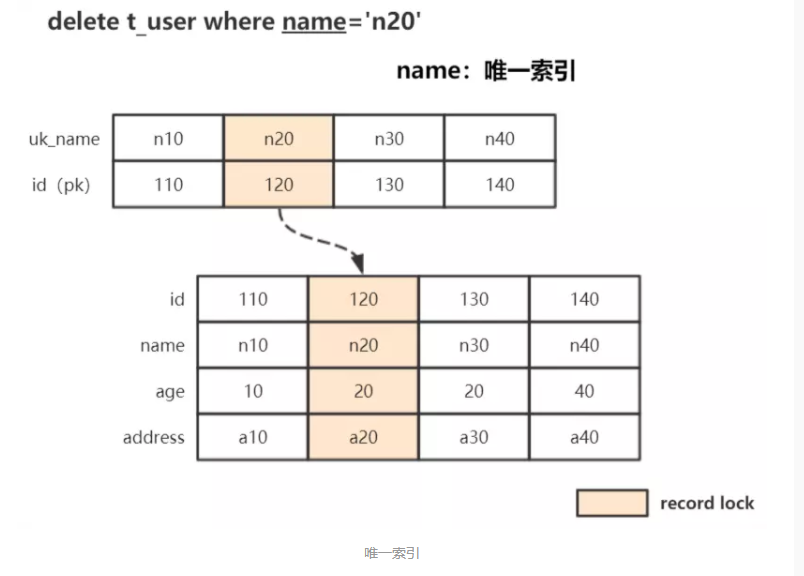
SQL验证:

3、一般索引
例:delete from t_user where age=20;
与主键和唯一索引不同的是,一般索引的记录是允许重复的;换句话说,如果我们单纯地给索引加记录锁时,其他事务依然可以插入,也就有可能出现幻读问题了。
所以除了给对应索引记录加上记录锁之外,还要给Gap加上锁。
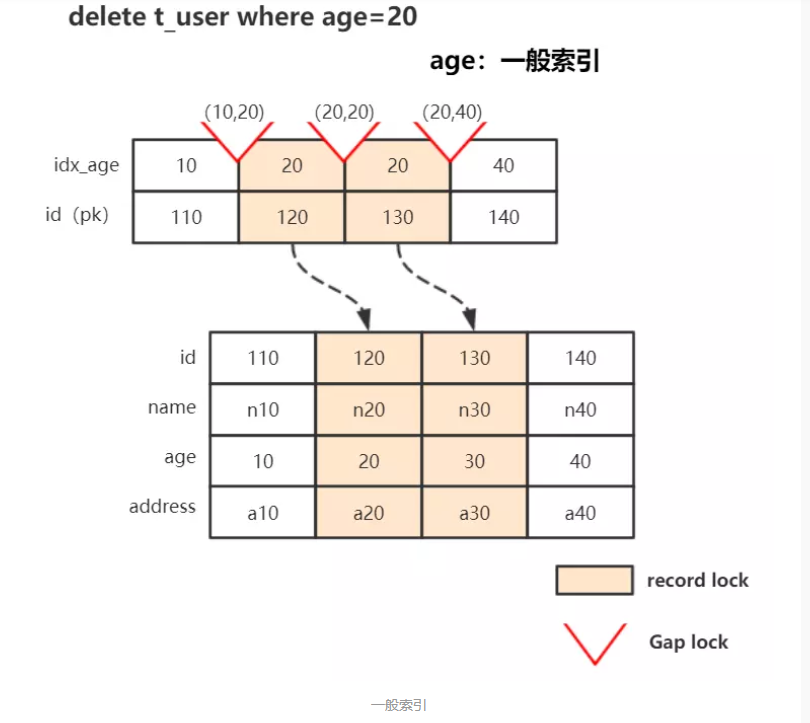
从上面知识点我们可以预估这个操作一共需要的锁:
-
age索引记录锁(Record Lock) :
20_120, 20_130(以下均用age_id这种形式表示索引值)
-
age索引间隙锁(Gap X-Lock):
(10, 20)、(20, 20)、(20, 40)
-
聚簇索引上的记录锁(Record X-Lock):
id=120/130对应的行记录
SQL验证:
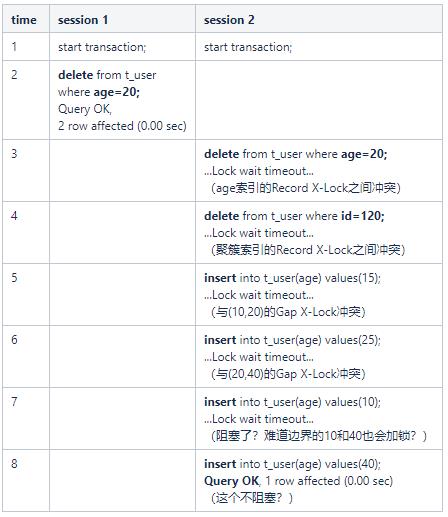
根据实际情况,3-6均符合我们预期,然而7和8则超出了我们预期的锁范围。为什么会超出我们预期呢?此次我们进行分析一下:
从7、8插入语句来看,由于id为自增主键,会自动递增,语句7插入值预计为:10_141;
语句8插入值预计为:40_141,为什么只有后者能插入呢?
其实我们可以将B+树中的间隙理解得更加精准一点:
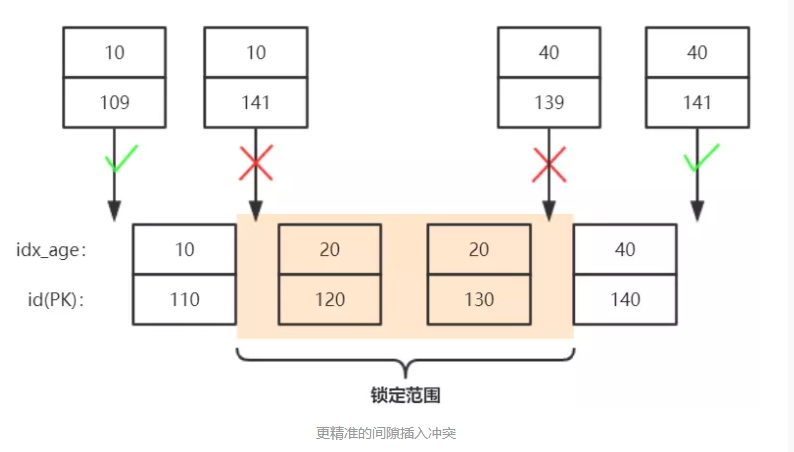
age=20的三个间隙应该为:(10_110, 20_120)、(20_120, 20_130)、(20_130, 40_140);
从上图可以看出语句7插入值10_141 无法插入,因为间隙被锁住了;而语句8插入 40_141值因为在间隙之外了,无锁冲突,允许插入。
所以最终的加锁情况应该这样表示:
-
age索引记录锁(Record Lock) :20_120, 20_130
-
age索引间隙锁(Gap X-Lock):(10_110, 20_120)、(20_120, 20_130)、(20_130, 40_140)
-
聚簇索引上的记录锁(Record X-Lock):id=120/130对应的行记录
4、无索引
delete from t_user where address='a20',因为无法精准定位,InnoDB选择将聚簇索引中的所有行以及间隙都锁起来,功能上已经等于锁表了:
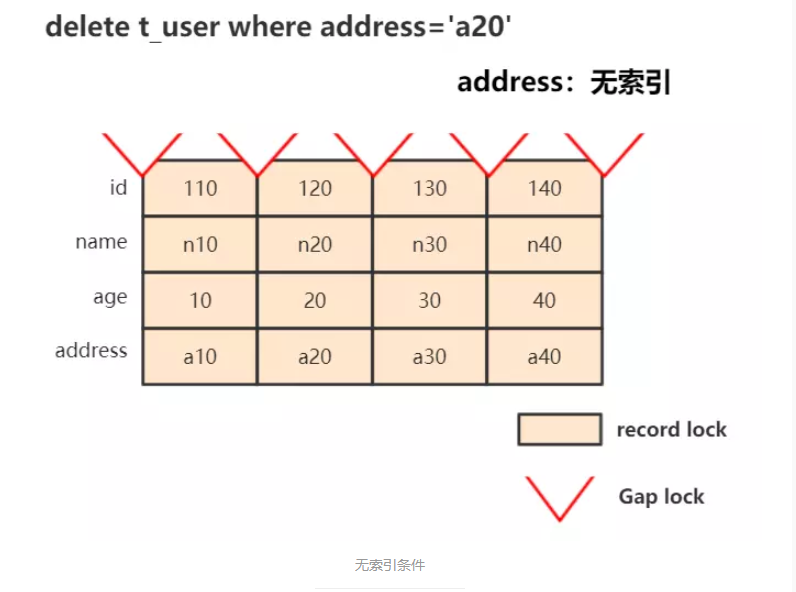
SQL验证:

5、结论
InnoDB 在RC(READ COMMITTED)隔离级别中,只会在对应的索引/行记录上加Record Lock,而不会加Gap锁,原因也很简单,因为该隔离级别是允许存在幻读问题的。
在RR级别下的加锁方式称之为Next-Key Locks,其实就是上述Record Locks和Gap Locks的结合。比如Gap Lock为(10,20) ,record lock为20,结合的Next-Key lock 为:(10, 20]。
分析Next-Key Locks其实就是要分析Record Locks和Gap Locks。MySQL InnoDB的可重复读并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁读使用到的机制就是next-key locks。
如果使用普通的读,会得到一致性的结果,如果使用了加锁的读,就会读到“最新的”“提交”读的结果。本身,可重复读和提交读是矛盾的。在同一个事务里,如果保证了可重复读,
就会看不到其他事务的提交,违背了提交读;如果保证了提交读,就会导致前后两次读到的结果不一致,违背了可重复读。可以这么讲,InnoDB提供了这样的机制,在默认的可重复读的隔离级别里,可以使用加锁读去查询最新的数据。
更多内容敬请关注 vivo 互联网技术 微信公众号

注:转载文章请先与微信号:labs2020 联系。