1.HashMap介绍
HashMap为Map接口的一个实现类,实现了所有Map的操作。HashMap除了允许key和value保存null值和非线程安全外,其他实现几乎和HashTable一致。
HashMap使用散列存储的方式保存kay-value键值对,因此其不支持数据保存的顺序。如果想要使用有序容器可以使用LinkedHashMap。
在性能上当HashMap中保存的key的哈希算法能够均匀的分布在每个bucket中的是时候,HashMap在基本的get和set操作的的时间复杂度都是O(n)。
在遍历HashMap的时候,其遍历节点的个数为bucket的个数+HashMap中保存的节点个数。因此当遍历操作比较频繁的时候需要注意HashMap的初始化容量不应该太大。 这一点其实比较好理解:当保存的节点个数一致的时候,bucket越少,遍历次数越少。
另外HashMap在resize的时候会有很大的性能消耗,因此当需要在保存HashMap中保存大量数据的时候,传入适当的默认容量以避免resize可以很大的提高性能。 具体的resize操作请参考下面对此方法的分析
HashMap是非线程安全的类,当作为共享可变资源使用的时候会出现线程安全问题。需要使用线程安全容器:
Map m = new ConcurrentHashMap();或者
Map m = Collections.synchronizedMap(new HashMap());
具体的HashMap会出现的线程安全问题分析请参考9中的分析。
2.数据结构介绍
HashMap使用数组+链表+树形结构的数据结构。其结构图如下所示。
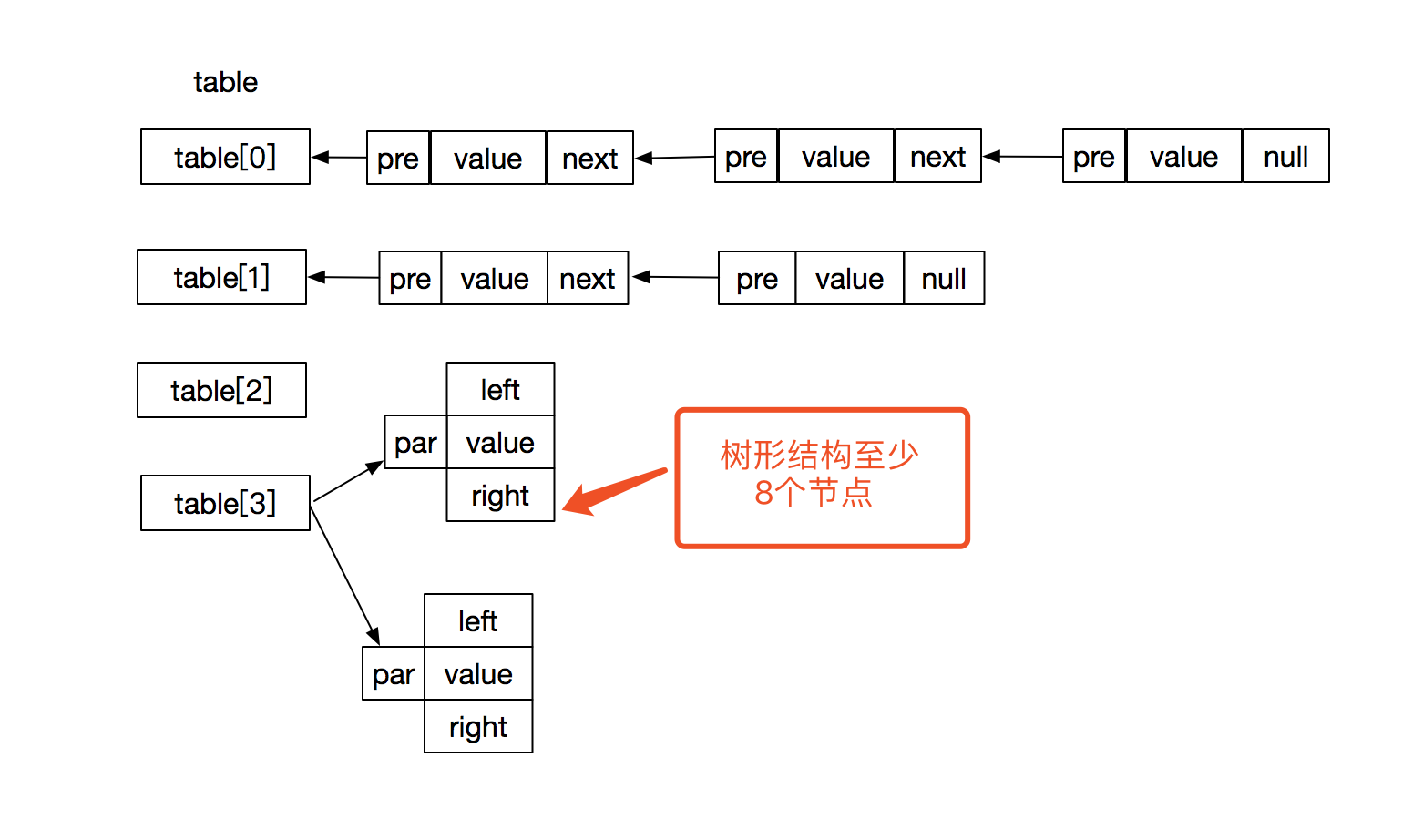
3.HashMap源码分析(基于JDK1.8)
3.1关键属性分析
transient Node<K,V>[] table; //Node类型的数组,记我们常说的bucket数组,其中每个元素为链表或者树形结构
transient int size;//HashMap中保存的数据个数
int threshold;//HashMap需要resize操作的阈值
final float loadFactor;//负载因子,用于计算threshold。计算公式为:threshold = loadFactor * capacity
其中还有一些默认值得属性,有默认容量2^4,默认负载因子0.75等.用于构造函数没有指定数值情况下的默认值。
3.2构造函数分析
HashMap提供了三个不同的构造函数,主要区别为是否传入初始化容量和负载因子。分别文以下三个。
//此构造函数创建一个空的HashMap,其中负载因子为默认值0.75
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//传入默认的容量大小,创造一个指定容量大小和默认负载因子为0.75的HashMap
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//创建一个指定容量和指定负载因为HashMap,以下代码删除了入参检查
public HashMap(int initialCapacity, float loadFactor) {
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
注意:此处的initialCapacity为数组table的大小,即bucket的个数。
其中在指定初始化容量的时候,会根据传入的参数来确定HashMap的容量大小。
初始化this.threshold的值为入参initialCapacity距离最近的一个2的n次方的值。取值方法如下:
case initialCapacity = 0:
this.threshold = 1;
case initialCapacity为非0且不为2的n次方:
this.threshold = 大于initialCapacity中第一个2的n次方的数。
case initialCapacity = 2^n:
this.threshold = initialCapacity
具体的计算方法为tableSizeFor(int cap)函数。计算方法是将入参的最高位下面的所有位都设置为1,然后加1
下面以入参为134217729为例分析计算过程。
首先将int转换为二进制如下:
cap = 0000 1000 0000 0000 0000 0000 0000 0001
static final int tableSizeFor(int cap) {
int n = cap - 1; //n =0000 1000 0000 0000 0000 0000 0000 0000 此操作为了处理cap=2的n次方的情况,如果不减1,计算的结果位2的n+1方,添加次操作当cap = 2^n的时候计算结果为2^n
//以下操作将n的最高位到最低位之间的各位全部设置为1
// n = 0000 1000 0000 0000 0000 0000 0000 0000
|0000 01000 0000 0000 0000 0000 0000 000
= 0000 1100 0000 0000 0000 0000 0000 0000
//最高两位设置为1
n |= n >>> 1;
// n = 0000 1100 0000 0000 0000 0000 0000 0000
| 0000 0011 0000 0000 0000 0000 0000 0000
= 0000 1111 0000 0000 0000 0000 0000 0000
//最高四位设置为1
n |= n >>> 2;
//n = 0000 1111 0000 0000 0000 0000 0000 0000
| 0000 0000 1111 0000 0000 0000 0000 0000
= 0000 1111 1111 0000 0000 0000 0000 0000
//最高8为设置为1
n |= n >>> 4;
//n = 0000 1111 1111 0000 0000 0000 0000 0000
| 0000 0000 0000 1111 1111 0000 0000 0000
= 0000 1111 1111 1111 1111 0000 0000 0000
//最高16为设置为1
n |= n >>> 8;
//n = 0000 1111 1111 1111 1111 0000 0000 0000
| 0000 0000 0000 0000 0000 1111 1111 1111
= 0000 1111 1111 1111 1111 1111 1111 1111
//不足32位,最高28位设置位1
n |= n >>> 16;
//n = n + 1 = 0000 1111 1111 1111 1111 1111 1111 1111 + 1 = 0001 0000 0000 0000 0000 0000 0000 0000
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
另外此处赋值为this.threshold,是因为构造函数的时候并不会创建table,只有实际插入数据的时候才会创建。目的应该是为了节省内存空间吧。
在第一次插入数据的时候,会将table的capacity设置为threshold,同时将threshold更新为loadFactor * capacity
3.3关键函数源码分析
3.3.1 第一次插入数据的操作
HashMap在插入数据的时候传入key-value键值对。使用hash寻址确定保存数据的bucket。当第一次插入数据的时候会进行HashMap中容器的初始化。具体操作如下:
Node<K,V>[] tab;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
其中resize函数的源码如下,主要操作为根据cap和loadFactory创建初始化table
Node<K, V>[] oldTab = table;
int oldThr = threshold; //oldThr 根据传入的初始化cap决定 2的n次方
int newCap, newThr = 0;
if (oldThr > 0) // 当构造函数中传入了capacity的时候
newCap = oldThr; //newCap = threshold 2的n次方,即构造函数的时候的初始化容量
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
float ft = (float)newCap * loadFactor; // 2的n次方 * loadFactory
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
threshold = newThr; //新的threshold== newCap * loadFactory
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //长度为2的n次方的数组
table = newTab;
在初始化table之后,将数据插入到指定位置,其中bucket的确定方法为:
i = (n - 1) & hash // 此处n-1必定为 0000 1111 1111....的格式,取&操作之后的值一定在数组的容量范围内。
其中hash的取值方式为:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
具体操作如下,创建Node并将node放到table的第i个元素中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = new Node(hash, key, value, null);
3.3.2 非第一次插入数据的操作源码分析
当HashMap中已有数据的时候,再次插入数据,会多出来在链表或者树中寻址的操作,和当size到达阈值时候的resize操作。多出来的步骤如下:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = new Node(hash, key, value, null);
else {
Node<K,V> e; K k;
// hash相等,且key地址相等或者equals为true的时候直接替换
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
// 当bucket的此节点为树结构的时候,在树中插入一个节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//便利此bucket节点,插入到链表尾部
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//当链表节点树大于TREEIFY_THRESHOLD的时候,转换为树形结构
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
另外,在resize操作中也和第一次插入数据的操作不同,当HashMap不为空的时候resize操作需要将之前的数据节点复制到新的table中。操作如下:
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //只有一个节点
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) // 如果是树形结构,拆开
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
3.4Cloneable和Serializable分析
在HashMap的定义中实现了Cloneable接口,Cloneable是一个标识接口,主要用来标识 Object.clone()的合法性,在没有实现此接口的实例中调用 Object.clone()方法会抛出CloneNotSupportedException异常。可以看到HashMap中重写了clone方法。
HashMap实现Serializable接口主要用于支持序列化。同样的Serializable也是一个标识接口,本身没有定义任何方法和属性。另外HashMap自定义了
private void writeObject(java.io.ObjectOutputStream s) throws IOException
private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException
两个方法实现了自定义序列化操作。
注意:支持序列化的类必须有无参构造函数。这点不难理解,反序列化的过程中需要通过反射创建对象。
4.HashMap的遍历
以下讨论两种遍历方式,测试代码如下:
方法一:
通过map.keySet()获取key的集合,然后通过遍历key的集合来遍历map
方法二:
通过map.entrySet()方法获取map中节点集合,然后遍历此集合遍历map
测试代码如下:
public static void main(String[] args) throws Exception {
Map<String, Object> map = new HashMap<>();
map.put("name", "test");
map.put("age", "25");
map.put("address", "HZ");
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(map.get(key));
}
Set<Map.Entry<String, Object>> set = map.entrySet();
for (Map.Entry<String, Object> entry : set) {
System.out.println("key is : " + entry.getKey() + ". value is " + entry.getValue());
}
}
输出如下:
HZ
test
25
key is : address. value is HZ
key is : name. value is test
key is : age. value is 25
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3c3z5rvu0g00g