1.String(字符串)
1.1 概述
- 字符串 string 是 Redis 最简单的数据结构。Redis 所有的数据结构都是以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。
- String 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字.
1.2 实现方式
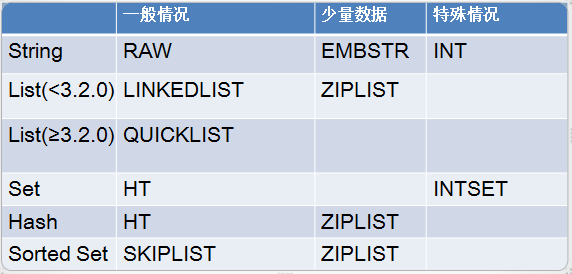
String在redis内部存储默认就是一个字符串(SDS),被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2. List(列表)
2.1 概述
- Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
- 一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
- 当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收.
2.2 实现方式
Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。
如果再深入一点,你会发现 Redis 底层存储的还不是一个简单的 linkedlist,而是称之为快速链表 quicklist 的一个结构。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next 。
所以 Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
2.3 常用场景
- 消息队列
3. Hash
3.1 概述
- Redis hash 是一个 string 类型的 field 和 value 的映射表,hash特别适合用于存储对象。
- Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
3.2 实现方式
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同 Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
4. Set
4.1 概述
- Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
- Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
4.2 实现方式
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。
5. Sorted Set
5.1 概述
- Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
- 不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
- 有序集合的成员是唯一的,但分数(score)却可以重复。
- 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
5.2 实现方式
zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结构。
zset主要包含两个数据结构。
一个是 dict(字典),key是成员,value是分值,用于支持 O(1) 复杂度的按成员取分值操作;
一个是 skiplist(跳跃表),按分值排序成员,用于支持平均复杂度为O(log N)的按分值定位成员的操作,以及范围操作;
6 发布订阅
- Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
- Redis 客户端可以订阅任意数量的频道。
- 订阅频道时可以订阅指定名称的频道, 当需要新增时需手动添加订阅
- 订阅指定模式的频道, 当新发布了符合此模式的频道时, 会自动订阅该频道
7. 基本数据结构的编码方式