一、hadoop是什么?
(1)Hadoop是一个开源的框架,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
(2)Hadoop就是一个分布式计算的解决方案。
二、hadoop的应用场景有哪些?
- 大数据量存储:分布式存储
- 日志处理: Hadoop擅长这个
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐
- 大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高。
- 数据支持并且最适用于一次写入,多次读取的场景。对于已经形成的数据的更新不支持。
- 数据不进行本地缓存(文件很大,且顺序读没有局部性)
- 任何一台服务器都有可能失效,需要通过大量的数据副本使得性能不会受到大的影响。
- 用户细分特征建模
- 个性化广告推荐
- 智能仪器推荐
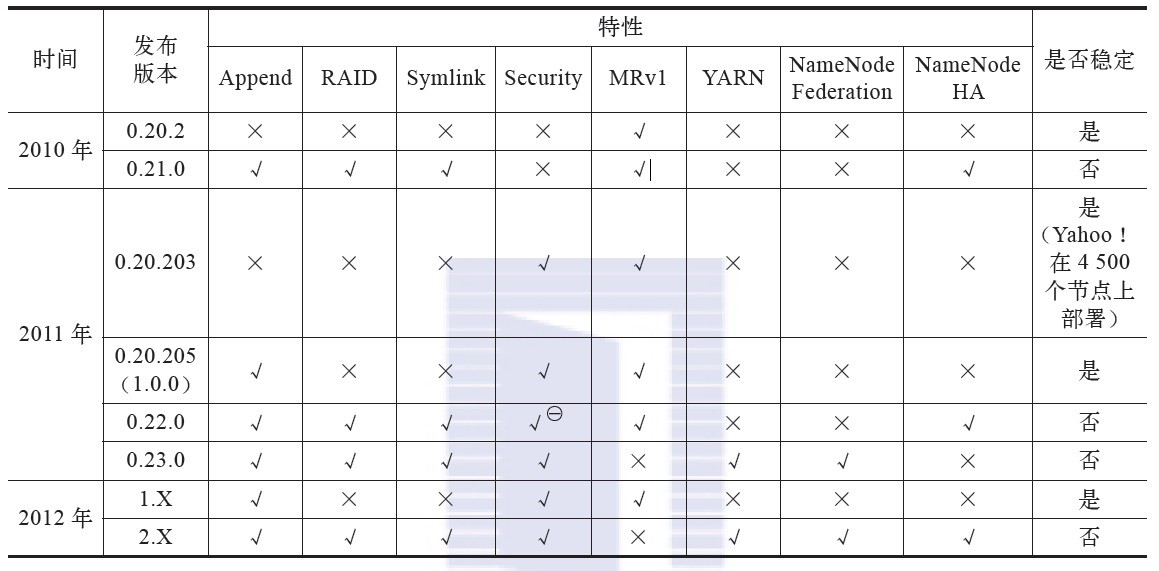
三、Hadoop各版本特性
四、Hadoop存储模型
Hadoop采用hbase做数据库,但由于hbase没有类sql查询方式,所以操作和计算数据非常不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库。
五、Hadoop的优缺点
Hadoop 在处理非结构数据和半结构数据上具备优势,尤其适合海量数据批处理等应用需求。