最近一直在学习神经网络,一方面是课题需要,另一方面是因为机器学习已经逐渐成为社会的潮流,各行各业都可以见到神经网络的应用,不学习一下都觉得自己落伍了。趁着这段时间没办法开学,好好学习了一些神经网络的基础内容,也试着把神经网络运用到自己的课题中来,今天在试验SSD目标检测网络的时候,发现要制作自己的训练集首先需要有训练的图片,可是一张一张找实在麻烦,找到了,逐个保存,最好还要改成统一的名称。百度找图找了几张,放弃了。。。几百张下去可能眼睛瞎了。
如果可以有一个程序自动找到我要的图片类型,还可以顺便修改统一名称保存到一个目录就好了。。。
又开始了百度:如何爬取网页里的图片? 毕竟对网页代码不熟悉,只能求助于百度了(面向百度编程呀。。。)
大概原理分析:
1、首先打开chorm浏览器,进入百度搜索 “自己要搜的图片”,按下F12,进入开发者模式,就会看到如下所示,右边就是网页代码(看不懂没关系,我也不懂)
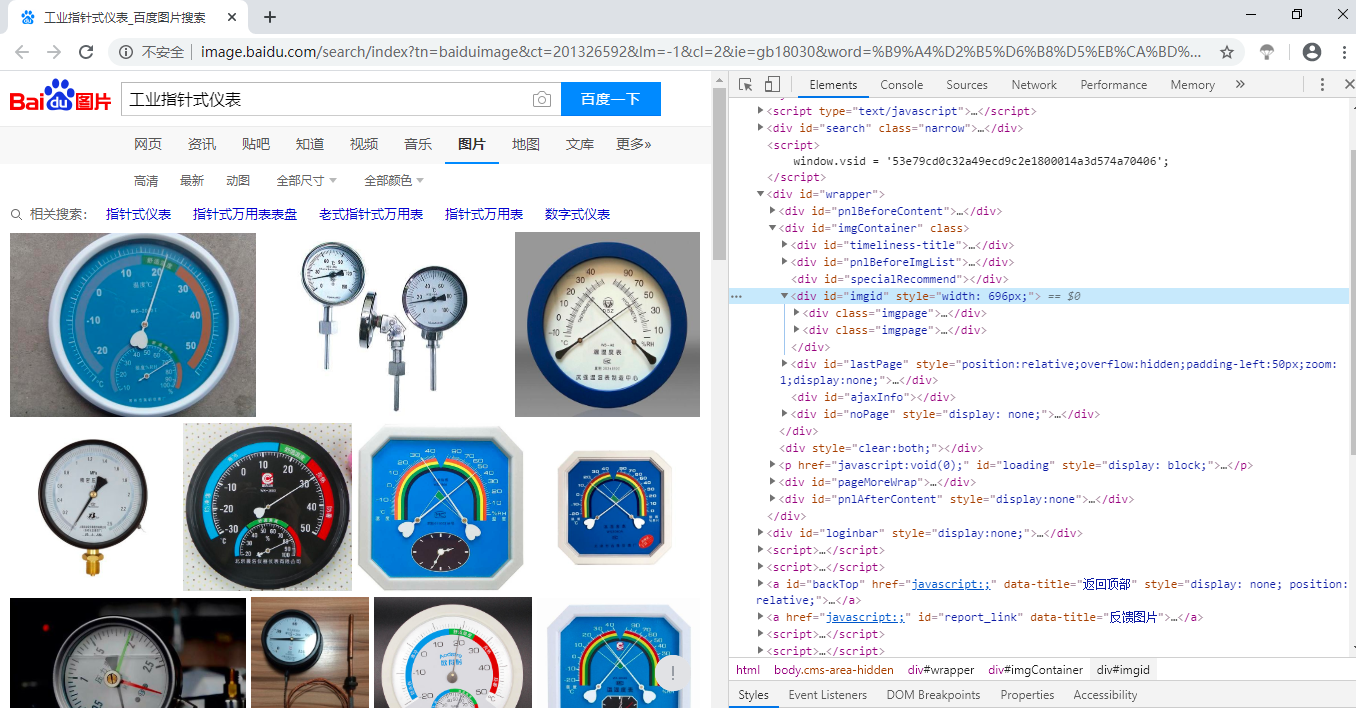
2、点击右侧的Network,鼠标滚轮在左边图片区域往下滑两下(图片是动态加载出来的,不滑两下Network下看不到东西)
点击XHR,在Name区域选择一个acjson?.......双击,就会出现右下角的小框,选择Headers,鼠标往下滑,找到Querry String Paramters。
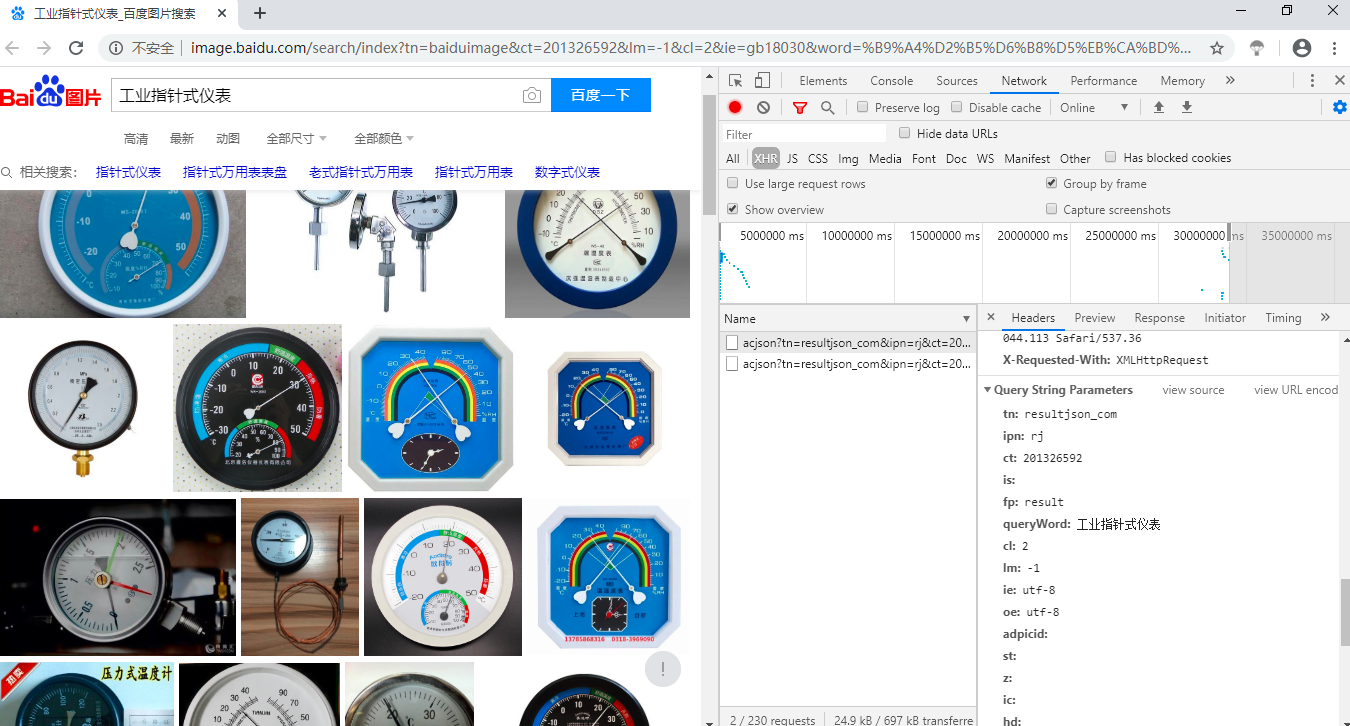
Querry String Paramters表示什么呢,主要是发现这里有一个参数querryWord:工业指针式仪表 --------是的这就是我的查询关键字

其中的 word 指的是搜索关键字, pn 指的是第几页图片, rn 值得是每页有30张图片,那程序的目的就是对百度图片网址+这一系列参数进行解析
百度图片搜索的url为 https://image.baidu.com/search/acjson
将Querry String Paramters里面的搜索关键字设置为可改变的参数。如上图所示,设置为keyword
得到网址解析后的数据后就可以对其中的图片进行下载保存了参考https://www.jianshu.com/p/46287bd8559b
利用request.get()对网页进行请求访问,再调用json()方法进行解析,实现对图片的爬取保存,总体代码如下:
要记得在python中安装requests module :pip install requests 即可
import requests import os def getManyPages(keyword, pages): params = [] for i in range(30, 30 * pages + 30, 30): params.append({ 'tn': 'resultjson_com', 'ipn': 'rj', 'ct': 201326592, 'is': '', 'fp': 'result', 'queryWord': keyword, 'cl': 2, 'lm': -1, 'ie': 'utf-8', 'oe': 'utf-8', 'adpicid': '', 'st': -1, 'z': '', 'ic': 0, 'word': keyword, 's': '', 'se': '', 'tab': '', 'width': '', 'height': '', 'face': 0, 'istype': 2, 'qc': '', 'nc': 1, 'fr': '', 'pn': i, 'rn': 30, 'gsm': '1e', '1488942260214': '' }) url = 'https://image.baidu.com/search/acjson' urls = [] for i in params: urls.append(requests.get(url, params=i).json().get('data')) return urls def getImg(dataList, localPath): if not os.path.exists(localPath): # 新建文件夹 os.mkdir(localPath) x = 0 for list in dataList: for i in list: if i.get('thumbURL') != None: print('正在下载中:%s' % i.get('thumbURL')) ir = requests.get(i.get('thumbURL')) open(localPath + '%d.jpg' % x, 'wb').write(ir.content) x += 1 else: print('该图片链接不存在') if __name__ == '__main__': dataList = getManyPages('工业指针式仪表', 2) # 参数1:关键字,参数2:要下载的页数 getImg(dataList, 'data/yibiao/') # 参数2:指定保存的路径
运行结果:

保存到本地文件夹的图片:
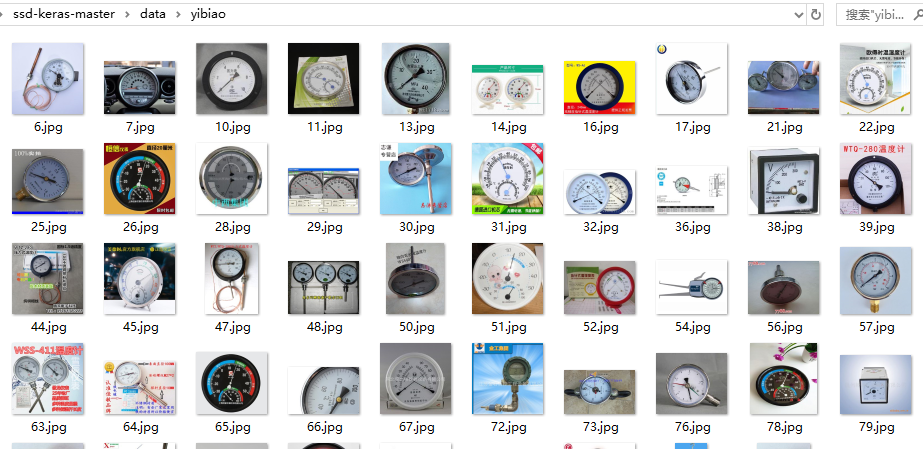
爬取到图片后人工对图片进行适当的筛选,删掉部分不符和要求的图片,就可以利用Labelimg进行图片的标注了
首先确定安装有labelimg 安装方式也简单: 打开python终端运行 pip install labelImg 即可
安装后在python终端下输入labelimg运行即可,因为我使用的是anaconda3的python开发环境,因此打开的是anaconda prompt
运行后就会出现运行界面
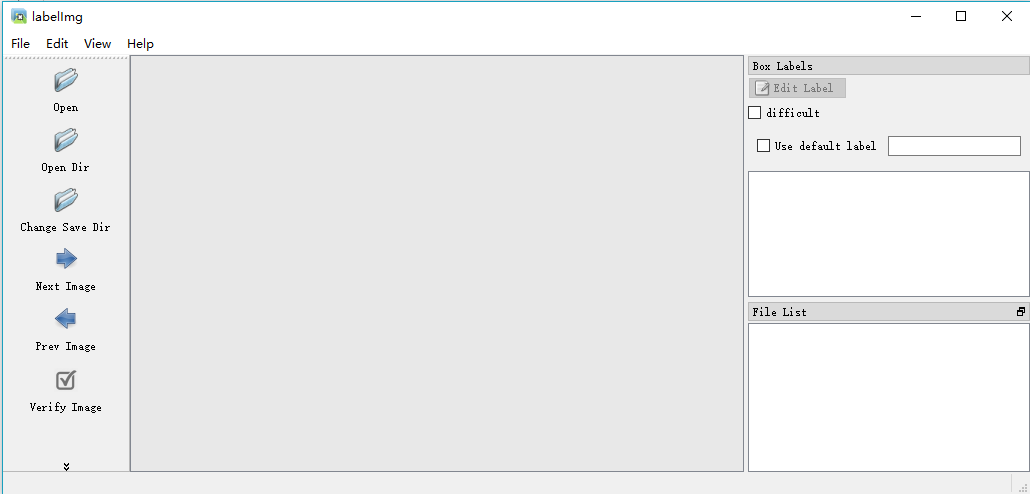
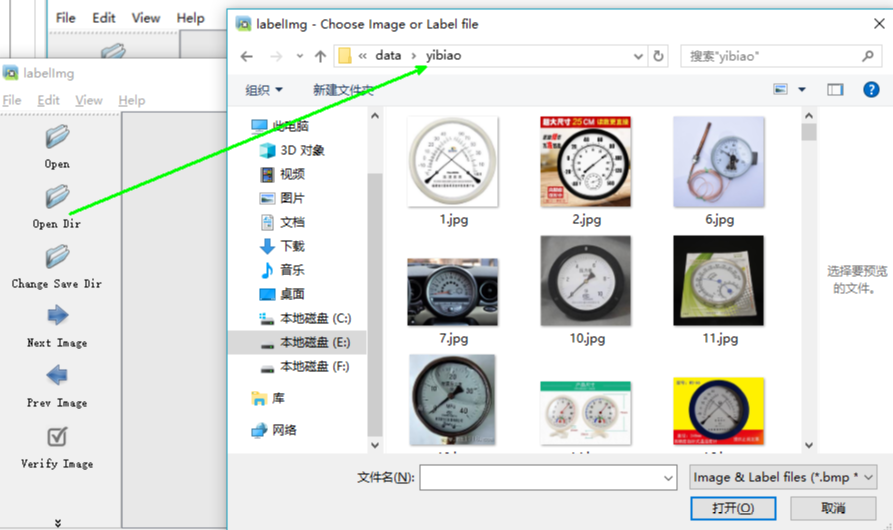
点击open dir 选择到自己下载的图片的路径
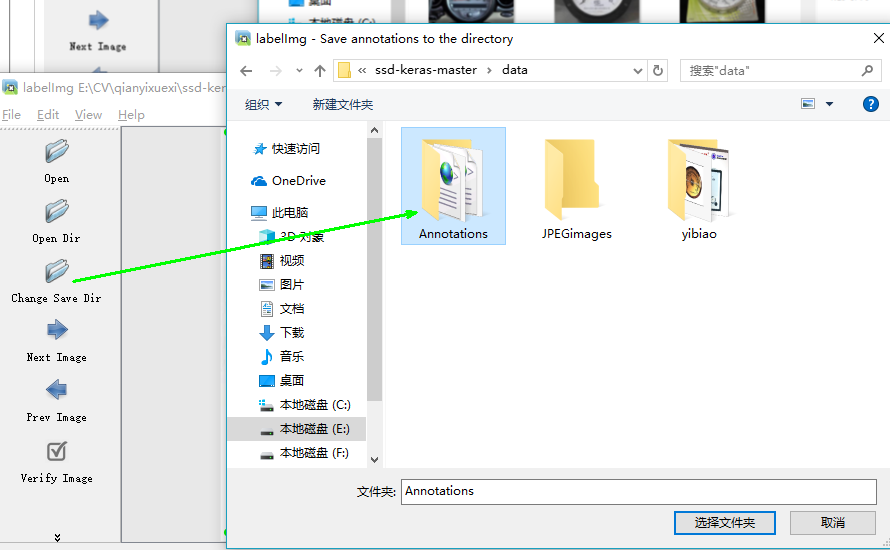
选择Changes Save Dir :新建一个Annotations文件夹专门用来存放标签数据
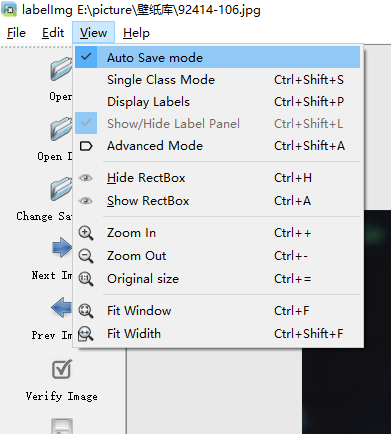
点击creat/nRectBox 或者直接快捷键w 可以标注图片,框选目标最小区域,保存为对应的类别如cat,保存xmlz标注文件(在Annotations里面),点击切换到下一张继续标注。希望快一点的可以设置view下的自动保存,用快捷键 A和D实现上一张、下一张的切换。

标注是没有办法偷懒的,只能一张一张进行标注,几个小时标注是很正常的哈,如果一张图片里有多个目标物,就多次创建标注框即可
保存的标注文件:
打开一个看一看:
yibiao是类别名称
有文件路径,文件名,图片的尺寸大小,目标框的边框点坐标bndBox等信息
<annotation> <folder>yibiao</folder> <filename>1.jpg</filename> <path>E:CVqianyixuexissd-keras-masterdatayibiao1.jpg</path> <source> <database>Unknown</database> </source> <size> <width>286</width> <height>285</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>class1</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>5</xmin> <ymin>3</ymin> <xmax>283</xmax> <ymax>279</ymax> </bndbox> </object> </annotation>