模块
在Python中, 一个.py文件就称为一个模块。
使用模块的好处:
1. 最大的好处就是大大提高了代码的可维护性
2. 编写代码不必从零开始。一个模块编写完毕,就可以被其他地方引用。在写其他程序时,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
3. 使用模块还可以避免函数名与变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,在编写模块时,不必考虑名字会与其他模块冲突。但是,要注意尽量不要与内置函数名字冲突。
所以,模块一共有三种:
1. Python标准库
2. 第三方模块
3. 应用程序自定义模块
模块的导入
1. 使用import语句
# 两种不同的导入方式 # 多个模块分多行导入 import module1 import module2 ... # 多个模块可以写在一行里导入 import module1, module2, module3, .....
当使用import语句的时候,Python解释器怎样找到对应的文件呢?
就是解释器有自己的搜索路径,存在sys.path里。
因此,若当前目录下存在要与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
2. from... import....语句
from module import name1[, name2[,nameN]]
这个声明不会把整个modulename模块导入到当前的命名空间中,只会将它里面的name1 或者name2单个引入到执行这个声明的模块的全局符号表。
3. from ... import * 语句
from module import *
该语句提供了一个简单的方法来导入一个模块中的所有项目。
然而,这种方式并不推荐使用,因为可能存在引入的模块里某个变量名与自己定义的变量名相同,而导致执行错误。
4. 被导入模块与当前文件不在同一个目录
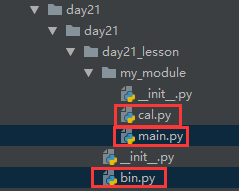
import sys print(sys.path) # 放的路径,就是执行文件所在路径 cal文件里有个add功能 # 需求:传入个参数,可以执行add功能 # 跨文件引入的方式 # 1. 首先:要在main里引入cal

# 2. 其次:要在bin里引入main
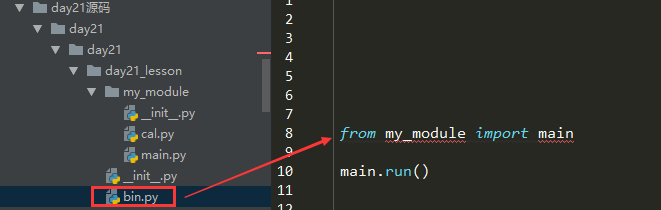
备注:
bin文件:一般是程序的入口
main文件:与逻辑相关的程序都放在main文件里
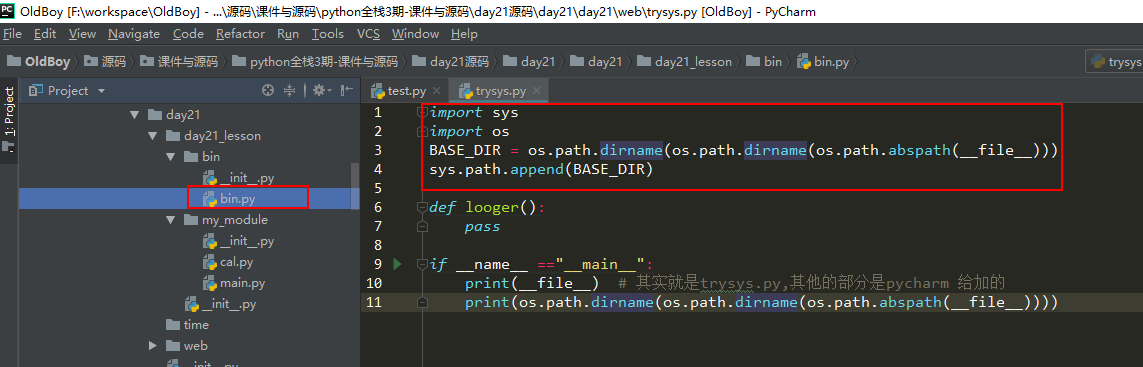
但是,通常情况下,bin都是写在包下面的,不会暴露在最外面。
记住下面的路径的写法,然后你的文件不管在哪个机器上使用都可以正常执行了。
看Day21 和 Day22(03-python-全栈三期-day22 BASEDIR的介绍 )
import sys import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR)
总的原理就是通过当前文件,一步步的往外找,找到你需要的文件目录,然后加入path 解析: 1. 首先要知道 __file__,就代表的是当前文件,此例子里就是bin.py文件 2. os.path.abspath(__file__):是__file__ 这个当前文件的绝对路径,找到bin目录 3. os.path.dirname(os.path.abspath(__file__)):就是通过2获取它的绝对路径的上一级绝对路径,到day21_lesson目录了 4. os.path.dirname(os.path.dirname(os.path.abspath(__file__))):再往上一层找,找到day21目录了 5. sys.path.append(BASE_DIR):把4找到的绝对路径加入到path里,之后,模块导入的时候,就会在day21目录下面找了 但是,也要知道,sys.path.append()也只是临时加入路径,不是永久加入的哦
5. 导入模块做的两件事
无论是上面1,2,3哪种导入方式,导入模块运行的本质都没有变,都做了2件事: 1. 首先通过sys.path找到被导入的模块(.py文件) 2. 然后执行全部被导入的模块。 区别是: import module 会将module这个变量名加载到名字空间 from module import name 只会将 name这个变量名加载进
模块的动态导入
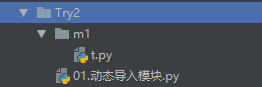
上面介绍了模块的正常导入,但是如果给的是一个字符串,那怎么导入呢?目录结构如下:
需求是:要将m1下的t.py导入到01.动态导入模块.py文件里
# 1. 正常的导入及调用执行 from m1 import t t.test1()
# 2. 现在有个新问题,要求你不能按照上面的方式到导入,给的是个字符串 'm1.t' # 通过字符串方式导入模块 module_t = __import__('m1.t') print(module_t) # <module 'm1' (namespace)> # 为什么导入的模块是m1,而不是t呢?而我们要导入的就是t模块啊? ''' 这种导入方式,不管你下面套多少层,返回的都是最顶层的模块 ''' # 调用:都需要通过最顶层的模块以.的方式,一层一层的往下找,直到调用你需要引用的模块 module_t.t.test1()
# 3. 利用importlib模块导入字符串形式的模块 import importlib m = importlib.import_module("m1.t") print(m) # <module 'm1.t' from 'F:\workspace\Try2\m1\t.py'> # 以这种方式导入,直接就定位到你想要调用的t模块了 # 调用 m.test1()
总结:
__import__(‘m1.t') 与 import.importLib(’m1.t') 导入的都是 字符串'm1.t'模块,为啥定位的模块不一样呢?也就是两者的区别?
1. __import__(‘m1.t') :是python内部的调用方式,它只能定位到最顶层的模块,调用的时候需要以点的方式,一级级往下找,直到找到你需要的模块
2.importLib('m1.5'):是面向用户的模块导入方式,它能直接定位到你需要导入的模块,所以,如果传入的是字符串形式的模块名,推荐用这种方式导入。
包
可以将不同类型、功能的文件放到不同的包里,方便管理
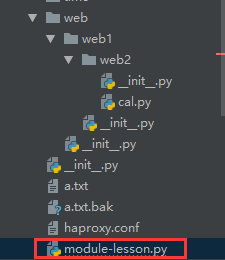
引用包
# 引用包有两种方式,包与包之间通过.号连接 在图中 module-lesson.py里执行cal.py文件 # 第一种:导入模块 from web.web1.web2 import cal cal.add(3,4) # 第二种:把模块和包写在一起,导入方法 from web.web1.22.cal import add add(3,5)
__name__:
# 1. 在执行文件里(当前正在被执行的文件就是执行文件) print(__name__) #结果 __main__ # 2. 在调用文件里执行 A文件里导入了B模块,A文件就是调用文件,B模块文件是被调用文件 print(__name__) # 结果 是B模块的文件名 (Pycharm会自作主张给出文件路径) 知道了这个原理,那if __name__=="__main__" 有什么作用呢? # 1. 如果放在被调用文件里,用于被调用文件的测试 if __name__=="__main__": print("ok") a=add(5,8) print(a) 解释: 一般写好了一个被调用文件,肯定是要先进行测试的,测试通过了,才能让别人调用。那么测试一般也是在被调用文件里进行的:
如果不加if __name__=="__main__",那么,该文件被调用后,测试代码就会被执行;
如果加上了if __name__=="__main__",Python就会知道该语句下面的代码是测试代码,其他人引入该文件,就自动忽略了(忽略了这写测试代码,不会被执行),而不去执行了。 # 2. if __name__=="__main__"如果放到执行文件里,就一点,意思是这个执行文件不想被其他人调用。(就是禁止别人调用我的文件)。 比如bin.py一般作为程序的入口,不希望别人调用,那也可以加上 if __name__=="__main__":
所以,写代码要养成习惯,在文件里要加上 if __name__=="__main__", 主动避免一些坑。
Python内置模块
1. time模块
文件名与内置模块同名,是可以的。
time模块里需要掌握的三种时间表达式。
关于时间模块,记住两张图
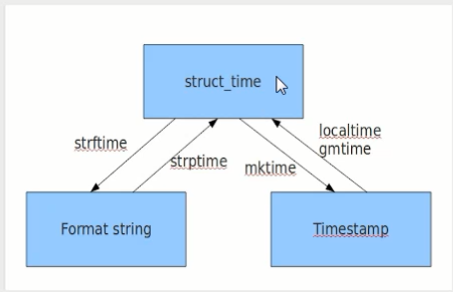
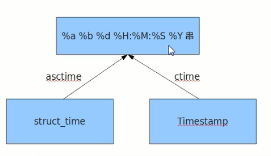
# 1. 时间戳:是一堆秒数 # 作用:做计算来用的 print(time.time()) #1481321748.481654秒 1970.1.1 00:00:00开始计算到当前为止总归的秒数 # 1970年是unix诞生的日子 # 2. #结构化时间---当地时间 print(time.localtime()) # 结果 time.struct_time(tm_year=2018, tm_mon=6, tm_mday=26, tm_hour=13, tm_min=7, tm_sec=29, tm_wday=1, tm_yday=177, tm_isdst=0) # tm_wday :表示这个星期的第几天,默认是从0开始的,1代表星期二 # tm_yday: 表示当前是第多少天 print(time.localtime(1529989999.4332166)) # 结果 time.struct_time(tm_year=2018, tm_mon=6, tm_mday=26, tm_hour=13, tm_min=13, tm_sec=19, tm_wday=1, tm_yday=177, tm_isdst=0) t=time.localtime() print(t.tm_year) # 2018 print(t.tm_wday) # 1 # 星期二,做显示的时候,需要手动 +1,转换为人类意识能接受的之后再显示 #-----#结构化时间---UTC市区,世界标准时间 print(time.gmtime()) # 结果 time.struct_time(tm_year=2018, tm_mon=6, tm_mday=26, tm_hour=5, tm_min=15, tm_sec=47, tm_wday=1, tm_yday=177, tm_isdst=0) print(time.gmtime(time.time())) # 结果 time.struct_time(tm_year=2018, tm_mon=6, tm_mday=26, tm_hour=5, tm_min=22, tm_sec=51, tm_wday=1, tm_yday=177, tm_isdst=0) # 将结构化时间转换成时间戳 print(time.mktime(time.localtime())) # 1529990485.0 # 将结构化时间转换成字符串时间(******) strftime() # 第一个参数:转换后的显示格式 # 第二个参数:要转换的时间 print(time.strftime("%Y---%m-%d %X",time.localtime())) # 结果 2018---06-26 13:25:27 # 年: %Y 月:%m 日:%d 时分秒:%X # 年月日之间的分隔符完全是自己定义的 # 将字符串时间转换为结构化时间 strptime() # 第一个参数:字符串时间,要转换的时间 # 第二个参数:结构化时间的格式与第一个字符串时间进行对应 print(time.strptime("2016:12:24:17:50:36","%Y:%m:%d:%X")) # 重点记住下面两种转换,因为不需要自己再自定义时间格式了 asctime() # 把一个表示时间的元组或者结构化时间 表示为:Tue Jun 26 13:35:21 2018 这种固定的形式 # 如果没有传参数,会默认将time.localtime()作为参数传入 print(time.asctime(time.localtime())) # Tue Jun 26 13:35:21 2018 ctime() # 把一个时间戳(按秒计算的浮点数)转换为time.asctime()的形式。 # 如果参数未给或者为None的时候,会默认将time.time()作为参数。 # 他的作用相当于time.asctime(time.localtime()) print(time.ctime()) # Tue Jun 26 13:36:26 2018
2. datetime 模块
import datetime print(datetime.datetime.now()) # 结果 2018-06-26 13:43:04.853231
3. random 模块
random模块提供各种用于生产伪随机数的函数,以及根据不同的实数分布来随机生产值的函数。
# random() : 生成(0,1)内的随机浮点数 ret = random.random() # uniform(a,b): 生成[a,b) 内的大于1的随机浮点数 ret=random.uniform(1,4) # randint(a,b) : 生成[a,b]内的随机整型数字,闭区间 ret=random.randint(1,3) # randrange(a,b [,step]) : 生成[a,b)内的随机整型数字,左闭右开区间, step表示步长 ret=random.randrange(1,10,2) # 只能在 1,3,5,7, 9里随机生成 随机序列: # choice(seq): 从非空序列seq中返回一个随机元素 ret=random.choice([11,22,33,44,55]) # sample(seq, len) : 返回长度为len的序列,包含从序列 seq中随机选择的元素。结果序列中的元素按照选择他们时的顺序排列 ret=random.sample([11,22,33,44,55],3) # shuffle(x, [random]): 随机原地打乱列表x中的项,random是可选参数,它指定随机生成函数。如果提供该参数,则该参数不能是包含参数并且返回范围在[0.0, 1.0)内的浮点数的函数。 ret=[1,2,3,4,5] random.shuffle(ret) print(ret) # [2, 1, 5, 4, 3]-->随机乱序的
生成一个数字和字母并存的4位数的随机验证码
def vCode(): ret = "" for i in range(4): num = random.randint(0,9) alf = chr(random.randint(65,122)) # A~Z 和 a~z finalVocd = str(random.choice([num, alf])) ret += finalVocd # 字符串拼接 return ret print(vCode())