Logistic回归模型
1. 模型简介:
线性回归往往并不能很好地解决分类问题,所以我们引出Logistic回归算法,算法的输出值或者说预测值一直介于0和1,虽然算法的名字有“回归”二字,但实际上Logistic回归是一种分类算法(classification y = 0 or 1)。
Logistic回归模型:
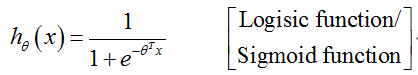
课堂记录(函数图像):
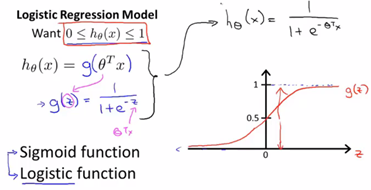
函数h(x)的输出值,我们把它看做,对于一个输入值x,y = 1的概率估计。比如说肿瘤分类的例子,我们有一个特征向量x,似的h(x)的输出为0.7,我们的假设将这样解释:这个具有特征向量x的患者,患有恶性肿瘤(y=1)的概率为0.7。
进一步理解假设函数:

如上推导过程由y = 0/y = 1,的结论出发,转化成为对![]() 的取值范围要求。下面引入一个简单的例子,并介绍决策边界的概念。
的取值范围要求。下面引入一个简单的例子,并介绍决策边界的概念。
决策边界:
在上图例中,我们假设已经拟合出参数![]() ,满足
,满足![]() 时,
时, ![]() ,我们将图中标为绿色的这条直线
,我们将图中标为绿色的这条直线![]() 称为决策边界,这条直线上的点满足
称为决策边界,这条直线上的点满足![]() 。【注:决策边界是假设函数
。【注:决策边界是假设函数![]() 的属性,决定于其参数,不是数据集的属性。只要给定了假设函数参数,决策边界(形状)就确定了。】
的属性,决定于其参数,不是数据集的属性。只要给定了假设函数参数,决策边界(形状)就确定了。】

在logistic回归中,应用更复杂的假设函数,我们就可能得到具有更复杂形状的决策边界。
2. 如何拟合Logistic回归(假设函数参数):
具体来说,我要来定义用来拟合参数的代价函数,这便是监督学习问题中Logistic回归模型的拟合问题。

我们有一个训练集,里面有m个训练样本,每个训练样本用n+1维的特征向量表示,特征![]() 。由于是一个分类问题,所以具有这样的特征:所有的标签y不是0就是1。
。由于是一个分类问题,所以具有这样的特征:所有的标签y不是0就是1。
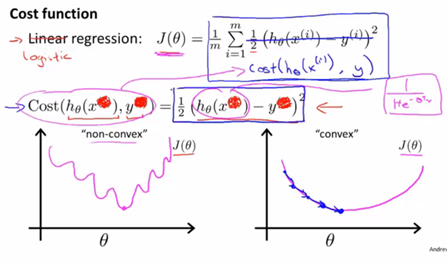
对于这个代价函数Cost的理解是这样的,它是在输出的预测值是![]() 时,而实际标签是y的情况下,我们希望学习算法付出的代价。由于在Logistic回归中我们的假设函数是非线性的,所以我们得到的代价函数
时,而实际标签是y的情况下,我们希望学习算法付出的代价。由于在Logistic回归中我们的假设函数是非线性的,所以我们得到的代价函数![]() 可能会是一个非凸函数,如左边的图像,很显然如果我们对这样的使用梯度下降法是无法保证得到全局最优的。因此我们需要找到一种新的Cost函数形式,使我们得到右侧的凸函数图像,以便使用我们比较好的算法如梯度下降算法。
可能会是一个非凸函数,如左边的图像,很显然如果我们对这样的使用梯度下降法是无法保证得到全局最优的。因此我们需要找到一种新的Cost函数形式,使我们得到右侧的凸函数图像,以便使用我们比较好的算法如梯度下降算法。
凸优化问题:

y = 1的情况
我们对函数的左右两端(0,1)进行分析可知此代价函数合理(y = 1时,如果![]() ,将会获得巨大的代价;如果
,将会获得巨大的代价;如果![]() ,则预测正确,代价为0)。
,则预测正确,代价为0)。
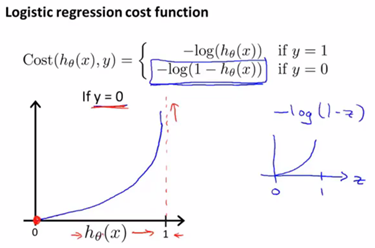
y = 0的情况
同理我们可对其合理性进行分析。
我们可以将代价函数优化后写成如下更加紧凑的等价形式:

课堂记录:

Conclusion:

有了代价函数,我们要寻找使其最小的一组参数 ![]() 。Logistic回归整体思路如下:
。Logistic回归整体思路如下:

3. 梯度下降过程:

尽管蓝色框中更新参数的规则看起来和线性回归的梯度下降参数更新规则基本相同,但实际上由于假设的定义发生变化,它和线性回归中的梯度下降实际上是完全不同的。同时,在实现的过程中记得要注意特征缩放带来的优化效果。
4. 高级优化:
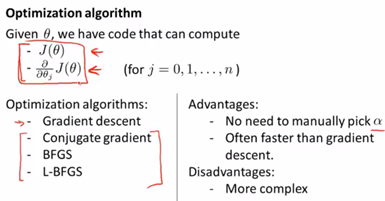
实际上完全有可能成功使用这些算法并应用于许多不同的学习问题,而不需要真正理解这些算法的内循环在做什么。同时除非你的研究方向即数值计算,否则都不推荐自己实现这些算法去应用,因为它们比梯度下降要复杂得多。
下面以一个例子解释这些高级算法如何应用。

我们实现一个代价函数costFounction(theta),它返回两个参数,其中jVal是我们要计算的代价函数![]() ,gradient是一个n*1维向量,其值与偏导数项一一对应。运行这个costFounction函数,完成以上两部分值的计算后,我们就可以调用高级的优化函数,这个函数叫fminunc(in Octave 表示无约束最小化函数)。(首先需要设置一些options:此处设置梯度目标参数为“on”、100次迭代)@costFunction指向我们刚定义的costFunction函数的指针,如果你调用它,就会使用高级优化算法其中的一个,当然你可以把它当做是梯度下降,只不过它能自动选择学习速率
,gradient是一个n*1维向量,其值与偏导数项一一对应。运行这个costFounction函数,完成以上两部分值的计算后,我们就可以调用高级的优化函数,这个函数叫fminunc(in Octave 表示无约束最小化函数)。(首先需要设置一些options:此处设置梯度目标参数为“on”、100次迭代)@costFunction指向我们刚定义的costFunction函数的指针,如果你调用它,就会使用高级优化算法其中的一个,当然你可以把它当做是梯度下降,只不过它能自动选择学习速率![]() (注:此处使用fminunc时
(注:此处使用fminunc时![]() )。
)。
实现代码:

有了这些高级优化的概念,并将它们很好的应用于较大规模的机器学习问题。我们就能将Logistic回归和线性回归模型应用于解决更多的学习问题。
5. 多类别分类问题:

其实我们也可以将二元分类问题的思想用在多分类问题中,称为一对多的思想。
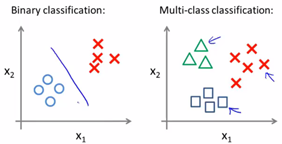
如上图左侧是我们解决二元分类问题的过程。一对多分类的思想如下图:
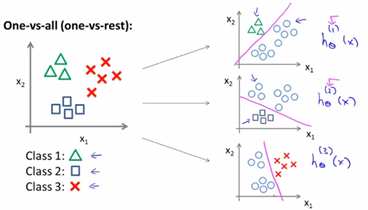
我们拟合出三个分类器![]() ,每一个分类器都针对其中一种情况进行训练,最终我们训练了逻辑回归的分类器
,每一个分类器都针对其中一种情况进行训练,最终我们训练了逻辑回归的分类器![]() ,预测i类别y=i的概率。最后为了做出预测,我们对每个分类器输入一个x,最后取h最大的类别。
,预测i类别y=i的概率。最后为了做出预测,我们对每个分类器输入一个x,最后取h最大的类别。