1.聚合
- 为了快速得到统计数据,提供了5个聚合函数,
- 只能得到聚合结果,没有原始数据
- count(*)表示计算总行数,括号中写星与列名,结果是相同的
查询学生总数 select count(*) from students;
mysql> select count(*) from students where isDelete=0; +----------+ | count(*) | +----------+ | 6 | +----------+
- max(列)表示求此列的最大值
查询女生的编号最大值 select max(id) from students where gender=0;
+---------+
| max(id) |
+---------+
| 6 |
+---------+
- min(列)表示求此列的最小值
查询未删除的学生最小编号 select min(id) from students where isdelete=0;
+---------+
| min(id) |
+---------+
| 1 |
+---------+
mysql> select * from students where id=1; #子查询 mysql> select * from students where id=(select min(id) from students where isDelete=0); +----+--------+--------+---------------------+----------+ | id | name | gender | birthday | isDelete | +----+--------+--------+---------------------+----------+ | 1 | 腾旭 | | 1999-09-09 00:00:00 | | +----+--------+--------+---------------------+----------+
- sum(列)表示求此列的和
查询男生的编号之后 select sum(id) from students where gender=1;
- avg(列)表示求此列的平均值
查询未删除女生的编号平均值 select avg(id) from students where isdelete=0 and gender=0;
mysql> select avg(id) from students where gender=0 and isDelete=1; +---------+ | avg(id) | +---------+ | 6.0000 | +---------+
2.分组
- 按照字段分组,表示此字段相同的数据会被放到一个组中
- 分组后,只能查询出相同的数据列,对于有差异的数据列无法出现在结果集中
- 可以对分组后的数据进行统计,做聚合运算
1)语法 group by
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...
- 查询男女生总数
select gender as 性别,count(*) from students group by gender;
mysql> select count(*) from students group by gender; +----------+ | count(*) | +----------+ | 1 | | 6 | +----------+ 2 rows in set (0.00 sec) mysql> select gender,count(*) from students group by gender; +--------+----------+ | gender | count(*) | +--------+----------+ | | 1 | | | 6 | +--------+----------+ 2 rows in set (0.01 sec)
2)分组后的数据筛选 having
对比where与having
- where是对from后面指定的表进行数据筛选,属于对原始数据的筛选
- having是对group by的结果进行筛选
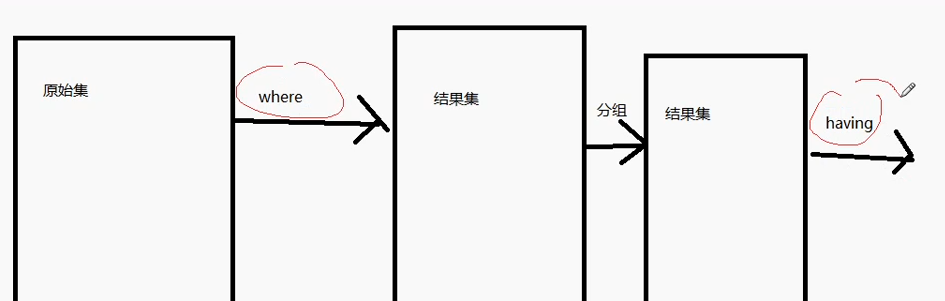
- 语法:
select 列1,列2,聚合... from 表名 group by 列1,列2,列3... having 列1,...聚合...
- having后面的条件运算符与where的相同
查询男生总人数 方案一 select count(*) from students where gender=1; ----------------------------------- 方案二: select gender as 性别,count(*) from students group by gender having gender=1;
mysql> select gender,count(*) from students group by gender having gender=0; +--------+----------+ | gender | count(*) | +--------+----------+ | | 1 | +--------+----------+
mysql> select gender,count(*) from students group by gender having count(*)>2;; +--------+----------+ | gender | count(*) | +--------+----------+ | | 6 | +--------+----------+
mysql> select gender,count(*) as 人数 from students group by gender having 人数>2; +--------+--------+ | gender | 人数 | +--------+--------+ | | 6 | +--------+--------+
3.排序
- 为了方便查看数据,可以对数据进行排序
- 语法:
select * from 表名 order by 列1 asc|desc,列2 asc|desc,...
- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从小到大排列
- asc从小到大排列,即升序
- desc从大到小排序,即降序
- 查询未删除男生学生信息,按学号降序
select * from students where gender=1 and isdelete=0 order by id desc;
mysql> select * from students where isDelete=0 and gender=1 order by id desc; +----+-----------+--------+---------------------+----------+ | id | name | gender | birthday | isDelete | +----+-----------+--------+---------------------+----------+ | 8 | 腾讯云 | | NULL | | | 7 | QQ | | NULL | | | 4 | 小米 | | NULL | | | 3 | 网易 | | NULL | | | 2 | 腾旭 | | 1990-02-02 00:00:00 | | | 1 | 腾旭 | | 1999-09-09 00:00:00 | | +----+-----------+--------+---------------------+----------+
- 查询未删除科目信息,按名称升序
select * from subject where isdelete=0 order by stitle;
mysql> select * from subjects where isDelete=1 order by id asc; +----+---------+----------+ | id | title | isDelete | +----+---------+----------+ | 2 | linux | | | 4 | redis | | | 5 | mysqlDB | | +----+---------+----------+
4.分页
1)获取部分行
- 当数据量过大时,在一页中查看数据是一件非常麻烦的事情
- 语法
select * from 表名 limit start,count
- 从start开始,获取count条数据
- start索引从0开始
+----+-----------+--------+---------------------+----------+ | id | name | gender | birthday | isDelete | +----+-----------+--------+---------------------+----------+ | 1 | 腾旭 | | 1999-09-09 00:00:00 | | | 2 | 腾旭 | | 1990-02-02 00:00:00 | | | 3 | 网易 | | NULL | | | 4 | 小米 | | NULL | | | 6 | 酷狗 | | 2017-02-13 00:00:00 | | | 7 | QQ | | NULL | | | 8 | 腾讯云 | | NULL | | +----+-----------+--------+---------------------+----------+
mysql> select * from students limit 1,3; +----+--------+--------+---------------------+----------+ | id | name | gender | birthday | isDelete | +----+--------+--------+---------------------+----------+ | 2 | 腾旭 | | 1990-02-02 00:00:00 | | | 3 | 网易 | | NULL | | | 4 | 小米 | | NULL | | +----+--------+--------+---------------------+----------+
mysql> select * from students limit 2,1; +----+--------+--------+----------+----------+ | id | name | gender | birthday | isDelete | +----+--------+--------+----------+----------+ | 3 | 网易 | | NULL | | +----+--------+--------+----------+----------+
2)示例:分页
- 已知:每页显示m条数据,当前显示第n页
- 求总页数:此段逻辑后面会在python中实现
- 查询总条数p1
- 使用p1除以m得到p2
- 如果整除则p2为总数页
- 如果不整除则p2+1为总页数
- 求第n页的数据
select * from students where isdelete=0 limit (n-1)*m,m
limit start,m m=5 0,5 == 0,1,2,3,4 1,5 == 5,6,7,8,9 2,5 == 10,11,12,13,14 .... m*n m=3 0,3 == 0,1,2 1,3 == 3,4,5 2,3 == 6,7,8 n start 1 0 2 m (n-1)*m
mysql> select * from students where isDelete=0 limit 0,5; +----+--------+--------+---------------------+----------+ | id | name | gender | birthday | isDelete | +----+--------+--------+---------------------+----------+ | 1 | 腾旭 | | 1999-09-09 00:00:00 | | | 2 | 腾旭 | | 1990-02-02 00:00:00 | | | 3 | 网易 | | NULL | | | 4 | 小米 | | NULL | | | 7 | QQ | | NULL | | +----+--------+--------+---------------------+----------+ mysql> select * from students where isDelete=0 limit 5,5; +----+-----------+--------+----------+----------+ | id | name | gender | birthday | isDelete | +----+-----------+--------+----------+----------+ | 8 | 腾讯云 | | NULL | | | 9 | 华为 | | NULL | | | 10 | 京东 | | NULL | | | 11 | 微博 | | NULL | | | 12 | 微信 | | NULL | | +----+-----------+--------+----------+----------+
总结
- 完整的select语句
select distinct * from 表名 where .... group by ... having ... order by ... limit star,count
- 执行顺序为:
- from 表名
- where ....
- group by ...
- select distinct *
- having ...
- order by ...
- limit star,count
- 实际使用中,只是语句中某些部分的组合,而不是全部