该环境布署文档,因项目运营中止2年,IDC均早已撤回。使用openstack 版本虽老,但弃之可惜,故贴出分享,其中已经将各个组件密码进行了提前替换,仅供参考
管理控制层面示图:
其实在修改这个布署文档是,我发现当时生产中的布署已经严重偏离了openstack高可用的指导思想。我们自己实践的高可用其实是适应自己的架构而做的调整,因为我们现实手头上中没有比较符合Ceph高速SSD集群搭建的服务器,并且又要追求最高的硬盘IO速度,这个布署过程,我们没有使用到swift或者cinder或者ceph这样的块存储或分布式存储,使用是均是本地存储的glance服务,这样便意味着,这个方案无法实现虚拟机实例的热迁移等操作,因为官方说过,需要在compute节点上使用swift或者ceph才能使用实例热迁移 或 调整实例大小时,实现操过作程中虚机不关机
当然,需要有需要分布存储的同学,可参考http://www.linuxidc.com/Linux/2015-08/120990.htm 这篇文,它列的ceph集群架构,如果有条件的话,可在它的架构基础上,把服务器的网口升级为2个万兆口,再加万兆交换机堆叠,便可支撑高IO的应用环境。
Openstack中,最关键是数据库,数据库采用集群方式,是为了灾备,因此我们使用了以上3台物理机做了数据库,如果对MariaDB Galera集群操作熟悉的话,是可以将3台数据库机器的角色位置IP进行迁移,验证过是可行的。
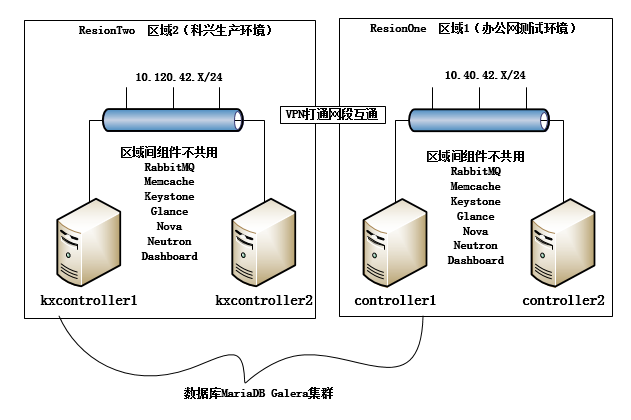
数据库名不共用:我们将数据库名分离,可以让各个区域内部自己访问自己最近的数据库机器,读写不冲突,比如办公网的openstack数据库访问就访问controller1,而科兴网的openstack数据库访问就访问kxcontroller1
区域间组件不共用:openstack的高可用指导建议中提到2个区域之间Keystone和keystone之间数据库可以共用,但因我们是跨公网的机房只是打通了VPN,但这不同于内网。担心公网有网络问题。无论keystone布在哪一端,都有可能影响openstack 管理层的操作。所以就没有用。
如此一来,大家就可以理解,这是2套独立的openstack布署方案,只是在布署过程中我配置Resion参数时,指了ResionOne ResionTwo
那为什么controller每个区域为什么要各2台?因为冷备!
为什么不是热备?因为一开始参考openstack高可用的配置过程,以为会很顺利,但我们实验发现在切换演练过程中(关闭其中1台主用的 controller物理机),并不能实现热切换。关键是RabbitMQ,几乎所有组件都要用到队列,集群中erlang RabbitMQ队列异常时,像nova neutron 的error log都会抛错。导致无法管理,虽然在切换后,组件角色更改了,虽然报错,但如果此时将所以的服务重启一遍,管理就能恢复,人工的介入定位和恢复,这便不是热备的概念
在此声明,我们在演练主用controller服务器挂了,并不影响compute节点上虚拟机的正常运行,
接下来我们进入到布署与配置环境,当前的环境配置定格在2016年11月8号
本次安装 的是openstack的自由版本,以自由版本(Liberty)为准。不是juno和kilo版本,因为他们的前2个版本的网络制式比较复杂。截止2016-11-08,openstack后来又出了2个新版本,Makita和Neton,这2新版本相比自由版本,并没有新开发逆天的功能,网络层架构也是跟自由版本一样,只是优化了配置的步奏和BUG的修复,新添加一些我们暂时用不到的功能而已,这2个新版是否有优化相关的高可用的BUG像RabbitMQ队列之类的,还有待验证
好了,进入正题,其实写这篇文前,我原本是先搭好了ResionOne区域一测试环境,后过了一段时间再搭的ResionTwo环境,但我会把这2个环境的布署整成1本笔记本
笔记本的格式,如果可以合并成1节的话,我们就这个组件布署写成1节,如果不能合并,我将与
X.1 X.2 将这个功能组件布署分开来写
openstack配置文件查询,我都会将原有的配置文件在所有的原机中保存下来,以_bak结尾,以便将来查找配置说明
比如
cp /etc/neutron/neutron.conf /etc/neutron/neutron.conf_bak