第八章 使用数据处理函数
8.1 函数
SQL支持利用函数来处理数据。函数一般是在数据上执行的,给数据的转换和处理提供了方便。
每一个DBMS都有特定的函数。只有少数几个函数被所有主要的DBMS等同的支持。
8.2 使用函数
大多数SQL实现支持以下类型的函数:
用于处理文本串(如删除或填充值,转换值为大写或小写)的文本函数
用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数
用于处理日期和时间值并从这些值中提取特定成分(如,返回两个日期之差,检查日期有效性等)的日期和时间函数
返回DBMS正使用的特殊信息(如返回用户登录信息)的系统函数
8.2.1 文本处理函数
1.UPPER() 函数将文本转换为大写
SELECT member_name,UPPER(member_name) AS
member_name_upcase
FROM personal_appeal
ORDER BY member_name;
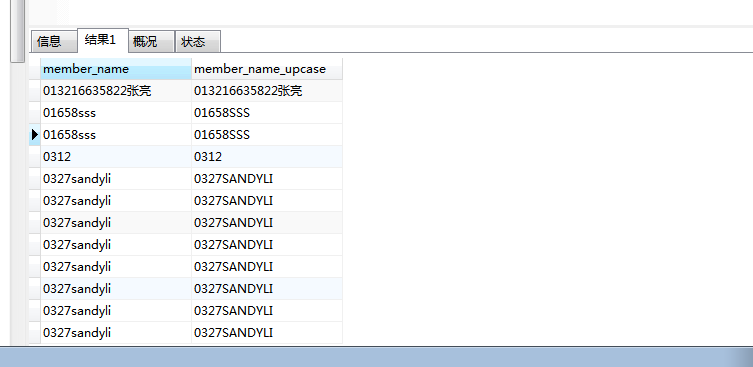
列出两列,第一列是表中存储的值,第二列 member_name_upcase 转换为大写
常用的文本函数:

SOUNDEX是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。
SOUNDEX考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较,多数DBMS都提供了对SOUNDEX的支持。
使用SOUNDEX()函数进行搜索: 匹配所有发音类似于LV的联系名
SELECT member_name FROM personal_appeal WHERE SOUNDEX(member_name)= SOUNDEX('LV');
WHERE 子句使用 SOUNDEX()函数来转换 member_name 列值和搜索串为它们的 SOUNDEX 值。
8.2.2 日期和时间处理函数
日期和时间采用相应的数据类型存储在表中,每种DBMS都有自己的变体。日期和时间值以特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。
一般,应用程序不使用用来存储日期和时间的格式,因此日期和时间函数总是被用来读取、统计和处理这些值。
日期和时间函数在SQL中具有重要的作用。
SELECT member_name,time_add FROM personal_appeal WHERE YEAR(time_add) = 2017;
MYSQL 使用 YEAR 函数从日期中提取年份
DBMS提供的功能远不止简单的日期成分提取。大多数DBMS具有比较日期、执行基于日期的运算、选择日期格式等的函数。
不同DBMS的日期-时间处理函数可能不同。详见相应文档
8.2.3 数值处理函数
数值处理函数仅处理数值数据。这些函数一般主要用于代数、三角或几何运算,因此没有串或日期-时间处理函数的使用那么频繁
常用的数值处理函数:

本章介绍如何使用SQL的数据处理函数。这些函数在格式化、处理和过滤数据中非常有用,但它们在各种SQL实现中很不一致。
第九章 汇总数据
本章介绍什么是SQL的聚集函数以及如何利用它们汇总表的数据。
9.1 聚集函数
经常需要汇总数据而不用实际检索出来,SQL提供了专门的函数。使用这些函数,SQL查询可用于检索数据,以便分析和报表生成。
这种类型的检索例子有:
确定表中行数(或者满足某个条件或包含某个特定值的行数)
获得表中行组的和
找出表列(或所有行或某些特定的行) 的最大、最小、平均值。
上述例子都需要对表中数据汇总而不是检索实际数据本身。因此,返回实际表数据是对时间和处理资源的一种浪费(更不用说带宽)。
为方便这种类型的检索,SQL给出了5个聚集函数。
聚集函数:运行在行组上,计算和返回单个值的函数

9.1.1 AVG()函数
通过对表中行数计数并计算特定列值之和,求得该列的平均值。
AVG()可用来返回所有列的平均值,也可以用来返回特定列或行的平均值。
使用AVG()返回 member_jifen 表中所有用户的平均总积分

AVG()函数只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。
NULL值:AVG()函数忽略列值为NULL的行
9.1.2 COUNT()函数
COUNT()函数进行计数。可用COUNT()确定表中行的数目或符合特定条件的行的数目。
COUNT()函数有两种使用方式:
使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
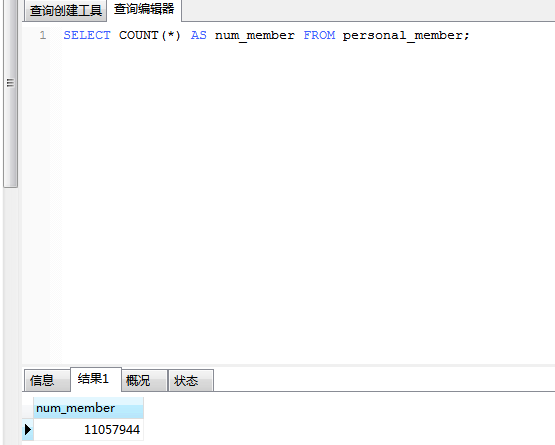
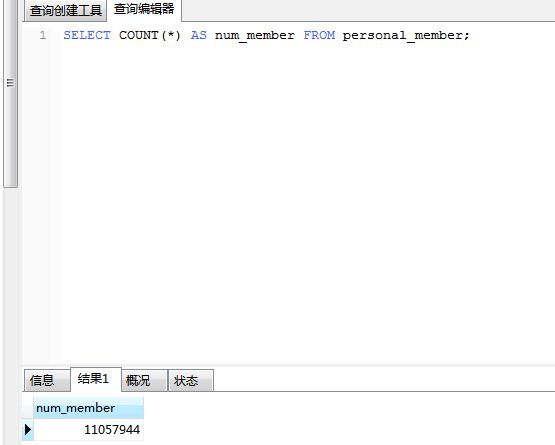
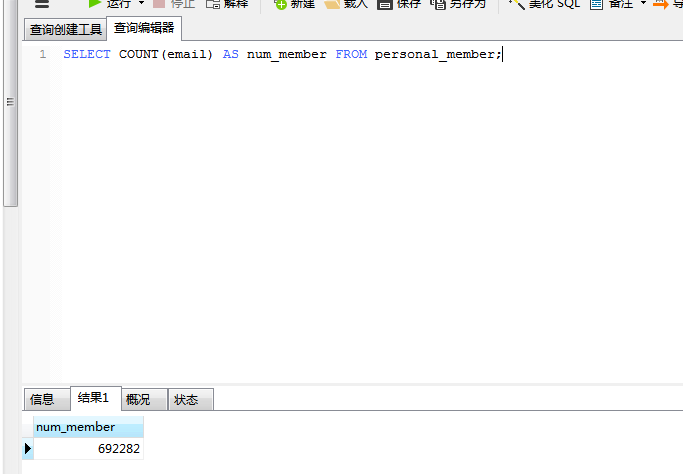
利用 COUNT(*)对所有行计数,不管行中各列有什么值。计数值在num_member中返回。

只对绑定了邮箱的客户计数
NULL值:如果指定列名,指定列的值为空的行被COUNT()函数忽略,但如果 COUNT()函数中用的是星号*,则不忽略
9.1.3 MAX()函数
MAX()返回指定列中的最大值。MAX()要求指定列名。
返回member_id值最大的用户名和member_id
NULL值:MAX()函数忽略列值为NULL的行
9.1.4 MIN()函数
MIN()函数返回指定列的最小值。与MAX()一样,MIN()要求指定列名
用法同 MAX()
9.1.5 SUM()函数
SUM()用来返回指定列值的和(总计)。
列出2017年添加的用户的所有安全分数值

9.2 聚集不同值
以上5个聚集函数都可以如下使用:
对所有的行执行计算,指定ALL参数或不给参数(因为ALL是默认行为)
只包含不同的值,指定DISTINCT参数
ALL为默认:ALL参数不需要指定,因为它是默认行为。如果不指定DISTINCT,则假定为ALL

9.3 组合聚集函数
SELECT语句可以根据需要包含多个聚集函数

用单条SELECT语句执行了4个聚集计算,返回4个值。
取别名:在指定别名以包含某个聚集函数的结果时,不应该使用表中实际的列名。虽然这样做并非不合法,但许多SQL实现不支持,可能会产生模糊的错误消息。
聚集函数用来汇总数据。SQL支持5个聚集函数,可以用多种方法使用它们以返回所需的结果。
这些函数是高效设计的,它们返回结果一般比你在自己的客户机应用程序中计算要快得多。
第十章 分组数据
本章介绍如何分组数据,以便能汇总表内容的子集。
设计两个新SELECT语句子句,分别是:GROUP BY 子句和 HAVING 子句
10.1 数据分组
分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算
创建分组
分组是在SELECT语句的GROUP BY 子句中建立的。
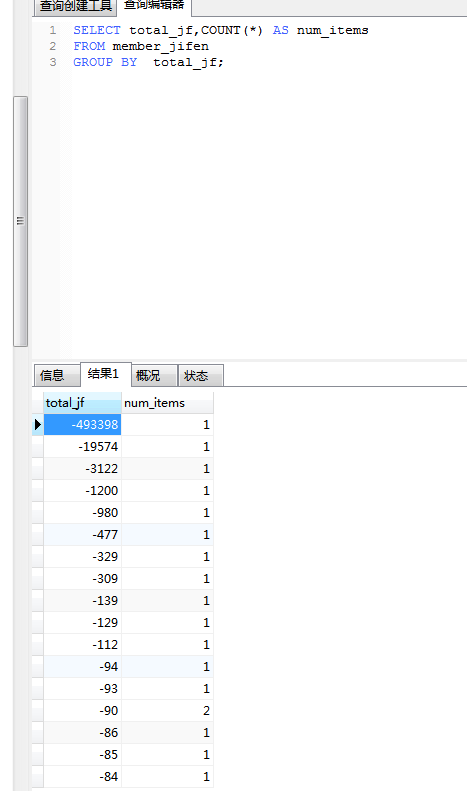
上面的SELECT子句指定了两个列,num_item为计算字段,表示当前积分数的总个数,
GROUP BY子句指示DBMS按tota_jf 排序并分组数据
GROUP BY子句指示DBMS分组数据,然后对每个组而不是整个结果集进行聚集
使用GROUP BY子句前,需要知道一些重要规定:
1.GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
2.如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总
3.GROUP BY子句中列出的每个列都必须是检索列或有效地表达式(但不能是聚集函数)。
在SELECT中使用表达式,必须在GROUP BY 子句中指定相同的表达式,不能使用别名。
4.大多数SQL实现不允许GROUP BY列带有长度可变的数据类型(如文本或备注型字段)
如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
5.GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
10.2 过滤分组
除了能用GROUP BY分组数据外,SQL还允许过滤分组,规定包括哪些分组,排除哪些分组。
列出至少有两个相同总积分的会员,为得出这种数据,必须基于完整的分组而不是个别的行进行过滤。
WHERE过滤指定的是列而不是分组。WHERE没有分组的概念
HAVING类似于WHERE,目前为止学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,HAVING过滤分组。
HAVING支持所有的WHERE操作符
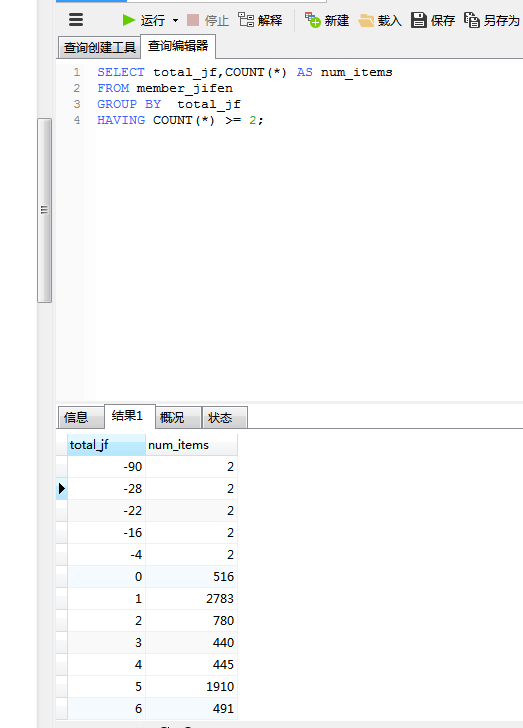
HAVING和WHERE的差别:
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。
WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
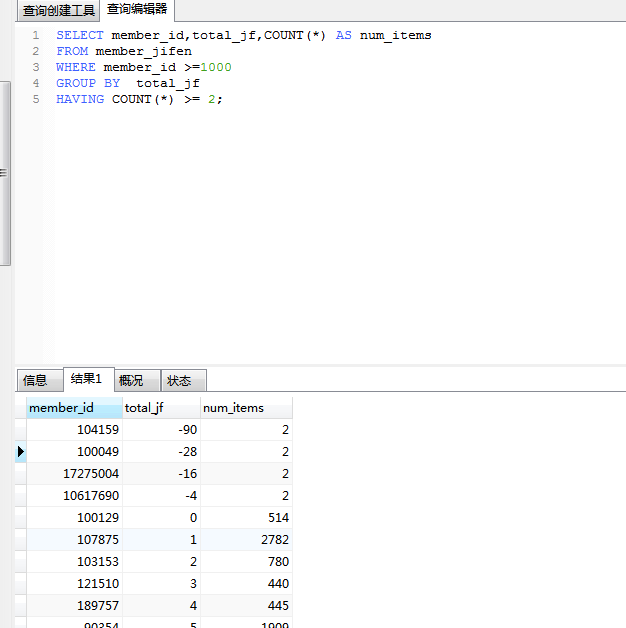
应该仅在与GROUP BY子句结合时才使用HAVING,而WHERE子句用于标准的行级过滤。
10.3 分组和排序


