本章内容:
- 列表生成式
- 生成器
- yield
- 迭代器
列表生成式
当我们要定义一个列表的时候,我们通常用这种方式a = [1,2,3],但是如果我们定义了一个比较长的列表的时候,手动定义列表就会比较麻烦,这是我们通常的做法就是利用循环的手段来创建列表,例如创建如下的列表:
L = [0,1,4,9,16,25,36,49,64,81]
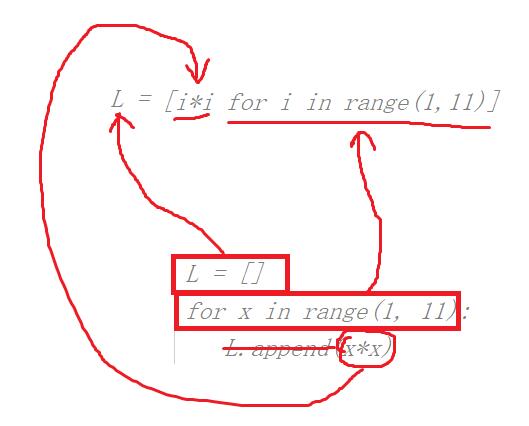
L = [] for x in range(1, 11): L.append(x*x)
这样我们就创建了一个较长的列表。
但是这样写,我们用了三行代码,其实我们可以用一行代码就代替了它:
L = [i*i for i in range(1,11)]
这就是列表生成式。
前面的i*i是运算式,也可以用函数,然后后面加上一个for循环就可以了。
其实我们不难看出,for循环和列表生成式的关系,如下图:
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
[x * x for x in range(1, 11) if x % 2 == 0] #结果为: #[4, 16, 36, 64, 100]
还可以使用两层循环,可以生成全排列:
[m + n for m in 'ABC' for n in 'XYZ'] #结果为: #['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
三层用的就比较少了。
生成器
上面的列表生成式的最外面是用中括号括起来的,如果把中括号变成小括号,也就是这样:
L = (i*i for i in range(1,11))
这样就是一个生成器了。
那么生成器有什么好处呢?
我们用列表生成式直接生成列表后,列表会直接放在内存中等待被使用。但是如果列表过于长了,但是我们暂时又用不到全部的元素,就会造成内存的浪费。生成器的好处就在于(i*i for i in range(1,11))这句话执行完毕后将返回一个算法给L,并不是直接将所有的数据放到内存中,当我们访问数据时,生成器就会根据算法现生成我们需要的书库,这样就避免了内存的浪费。
但是生成器不能像列表一样a[100]这样直接取出某个数据,因为生成器还没有访问到第100个元素。生成器其实就像一个递推公式一样,想要知道第100个元素是什么,就必须要先知道第99个元素是什么,以此类推...
下面用生成器生成一个列表并且遍历所有的数据
L = (i*i for i in range(1,11))
for i in L:
print(i)
也可以一个一个数据的访问,调用生成器中下一个数据
a = (i*i for i in range(1,11)) a.__next__() #这样就调用了下一个数据
并且生成器也只有一个方法,就是__next__()方法,只能往下走,不能回头。
yield
先来看一个菲波那切数列的迭代算法。
def fib(max):
n,a,b = 0,0,1
while n<max:
#print(b) #如果用print,那么这个函数就会直接输出数列的所有值
yield b #如果用yield,那么这个函数就会变成一个生成器
a, b = b, a + b
n = n + 1
return '---done---' #如果程序抛异常,就会返回这个信息
yield可以保存当前循环的状态,然后可以先做其他的事情,做完其他的事情,可以回来继续进行下一个循环。
yield的一个稍微复杂的应用 - 利用yield模拟多线程
import time
def consumer(name):
print("%s 准备吃包子了!" %name)
while True:
baozi = yield
print("包子[%s]来了,被[%s]吃了!" %(baozi,name))
#当函数中有yield时,这个函数就会变成一个生成器
c = consumer('lisi') #将这个生成器赋值给c
c.__next__() #然后执行一次这个生成器,但是一次调用只会执行到含有yield的语句前面,
# 因为yield可以暂停并保存当前的状态,一到yield就会暂停,所以while循环里面的输出语句没有执行
c.send('猪肉') #send()函数,用来向yield里面传值,然后继续执行一次,直到再次碰到yield时就会再次暂停
#注意,第一次执行时一定要执行__next__()函数,后面才可以执行send()函数
c.send('牛肉') #再次传值,再次执行while里面的语句,注意,不会执行上面的print("%s 准备吃包子了!" %name)语句
c.send('niurou') #再次传值,再次执行while里面的语句
c.__next__() #这里再次调用__next__()函数,同样还是执行while里面的输出语句,但是不会向yield里面传值
上面是手动执行这个生成器,下面写一个函数来调用这个生成器。
import time
def consumer(name):
print("%s 准备吃包子了!" %name)
while True:
baozi = yield
print("包子[%s]来了,被[%s]吃了!" %(baozi,name))
def producer():
c = consumer('A')
c2 = consumer('B')
c.__next__()
c2.__next__()
print('老子开始准备做包子了')
for i in range(10):
time.sleep(1)
print('做了一个包子,分两半')
c.send(i)
c2.send(i)
producer()
#这样就是一边做包子,一边吃包子了
迭代器
可以被next()函数调用并不断返回下一个值的对象成为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象或者Iterable对象
from collections import Iterator #需要先导入这个模块
isinstance((x for x in range(10)),Iterator)
#第一个参数为想要判断的东西,第二个参数是想要判断的类型
isinstance({},Iterator)
from collections import Iterable
isinstance((),Iterator)
isinstance('abc',Iterator)
生成器都是Iterator对象,但是list、dict、str虽然是Iterator,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()对象。
isinstance(iter([]),Iterator) #这样结果就是True了 #例子 a = [1,2,3] b = iter(a) b.__next__()