1.作业头
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/SE2020-2 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/SE2020-2/homework/11769 |
| 这个作业的目标 | <让我们学习并了解文件的使用,编写基本的测试程序。> |
| 学号 | <20209136> |
一、本周教学内容&目标
第6章 回顾数据类型和表达式,第12章 文件
二、本周作业
2.1 题目:给定一个十进制正整数N,写下从1开始,到N的所有整数,然后数一下其中出现的所有“1”的个数。
例如:
N=2,写下1,2。这样只出现了1个”1“。
N=12,我们会写下1,2,3,4,5,6,7,8,9,10,11,12。这样,1的个数是5。
问题是:
1.写出一个函数f(N),返回1到N之间出现的”1“的个数,比如f(12)=5;
2.满足条件”f(N)=N“的最大的N是多少?
要求:
1.贴出代码图片,写出解题思路,列出测试数据(5分)
(1)代码如下:
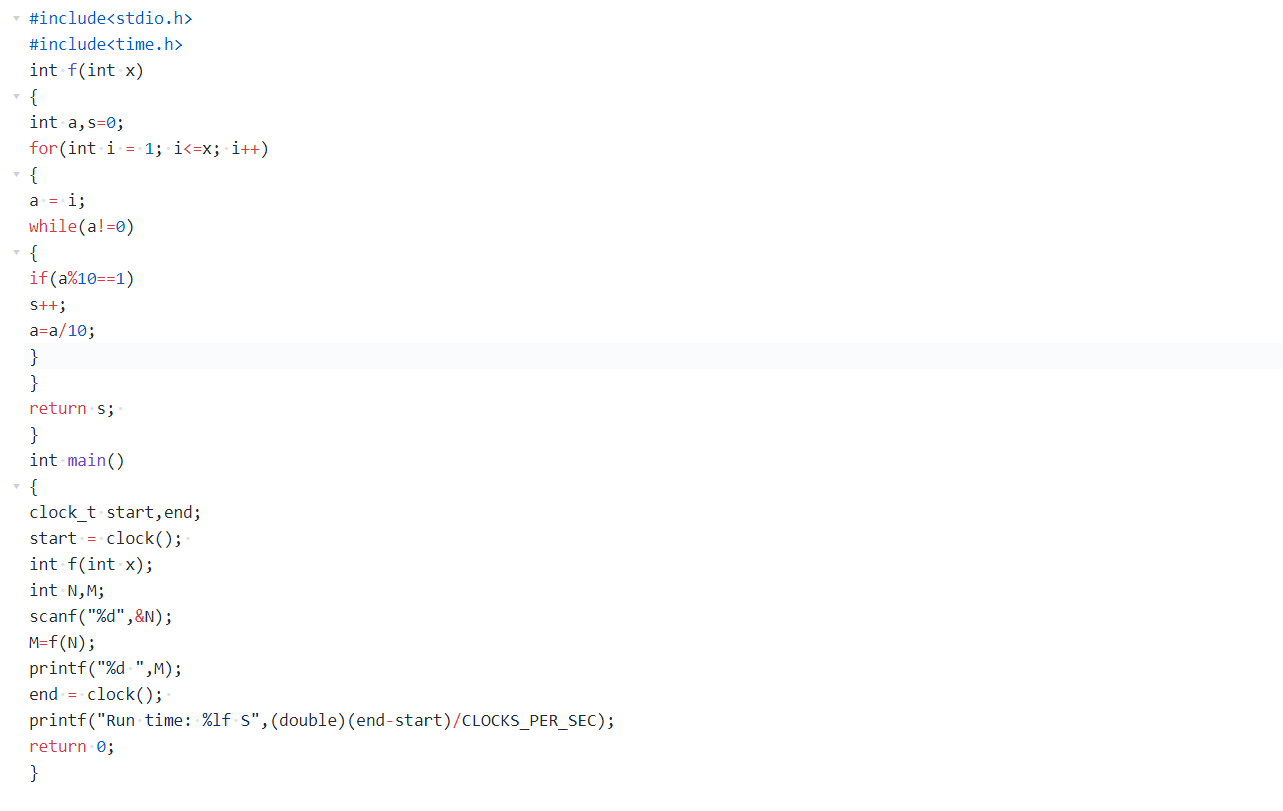
(2)解题思路:
1.首先看了看题目,是要写出一个函数来求1的个数,既然是要写函数,那么联系所学函数知识那一章,首先想到的就是先要自定义一个函数再来调用它计算并反馈出结果。稍微看了看后面的题目,所以就先放弃定义浮点型变量,因为要留有改进空间。使用for循环做一个数数器,在其中增加while循环,用取余的方法使得一个数的每一位都会被判断是否满足条件,如果满足条件那么最终结果会加1,不满足条件最终结果不会加1,一直到数数器数到最后一位,以此循环。
(3)测试数据
| N | 数字1的个数 |
|---|---|
| 1 | 1 |
| 10 | 2 |
| 100 | 21 |
| 1000 | 301 |
| 10000 | 4001 |
| 100000 | 50001 |
2.给出不同测试数据的运算时间,如果你的运算时间不变,说明你的测试数据不够大(5分)





3.思考针对足够大的数据,如何减少运算时间,并给出在原有算法基础上的改进算法和改进思路。(10分)
针对足够大的数据,减少变量的定义,改变原来使用调用函数的方法,压缩代码尽量精简。本来想定义浮点型来增加范围,但是浮点数用取余的方法得调用库函数fmod,fmodl或fmodf,试过发现得到的数据不对便使用了长整型。
算法如下:
#include<stdio.h>
int main()
{
long long int a,N,i,s=0;
scanf("%d",&N);
for( i = 1; i<=N; i++)
{
a = i;
while(a!=0)
{
if(a%10==1)
s++;
a=a/10;
}
}
printf("%lld",s);
return 0;
}
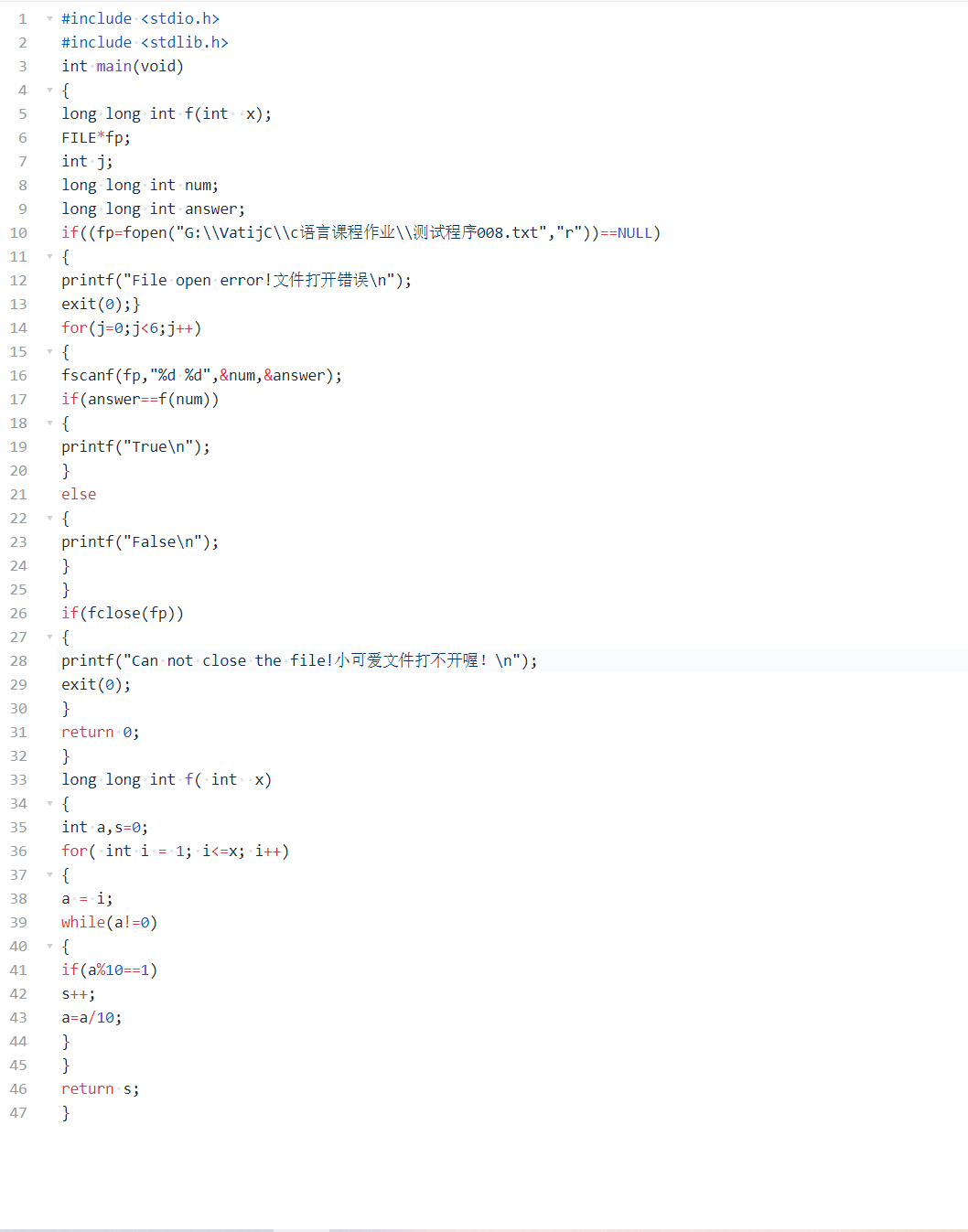
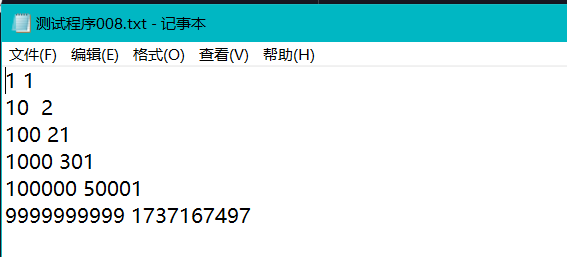
2.2 将上题中多组测试数据写入文件,并给出测试程序以检测你的代码有没有问题,贴出你的代码、运行结果和文件内容。(5分)
(1)代码
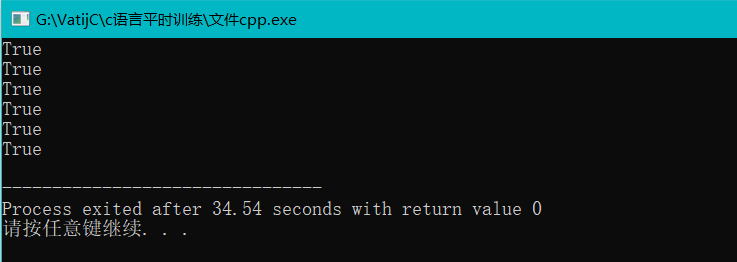
(2)运行结果
(3)文件内容
2.3 用自己的语言回答两个问题,并给出所查阅资料的引用(10分)
1.什么是文件缓冲系统?工作原理如何?
就比如我们平时用的WPS软件,在打开它时系统会自动打开一个一个wps临时文件,可以就看做是缓冲文件,我们在原文件中的修改只是在临时文件中操作的,点击保存时才会将所有修改的操作全部保存到原文件中。而这种缓冲区技术的目的就是为了提高系统读写效率,我们将所有修改一次性完成,和每次修改都要访问依次原文件来说,效率更高。我们知道磁盘的访问速度是远小于内存的。所以引入缓冲区技术提高访问效率。工作原理,从内存向磁盘输出的数据会先送到内存的缓冲区,等装满缓冲区后一起送到磁盘上从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区,然后再从缓冲区中将数据送到程序数据区。---参考文献来源于CSDN社区代号[k]
2.什么是文本文件和二进制文件?
文本文件与二进制文件的定义
大家都知道计算机的存储在物理上是二进制的,所以文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。这两者只是在编码层次上有差异。
简单来说,文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。二进制文件是基于值编码的文件,你可以根据具体应用,指定某个值是什么意思(这样一个过程,可以看作是自定义编码)。
从上面可以看出文本文件基本上是定长编码的,基于字符嘛,每个字符在具体编码中是固定的,ASCII码是8个比特的编码,UNICODE一般占16个比特。而二进制文件可看成是变长编码的,因为是值编码嘛,多少个比特代表一个值,完全由你决定。大家可能对BMP文件比较熟悉,就拿它举例子吧,其头部是较为固定长度的文件头信息,前2字节用来记录文件为BMP格式,接下来的8个字节用来记录文件长度,再接下来的4字节用来记录bmp文件头的长度。。。大家可以看出来了吧,其编码是基于值的(不定长的,2、4、8字节长的值都有),所以BMP是二进制文件。---参考文献来源于CSDN社区Zebul博
2.4 请给出本周学习总结(15分)
(1)学习进度条(5分)
| 周/日期 | 代码行 | 这周所花的时间 | 学到的知识点简介 | 目前比较疑惑的问题 |
|---|---|---|---|---|
| 第八周10.19-10.25 | 480 | 23小时 | 调用输入输出函数,输出任意的字符串。 | 输入输出格式常没有与题目一致 |
| 第九周10.26-11.01 | 599 | 33小时 | 数的类型,定义变量时要先考虑清楚。 | 数据溢出和负数的浮点型 |
| 第十周11.02-11.08 | 519 | 27小时 | for循环语句,if的判断语句。 | 多次循环与循环体中再添加变量赋值并再循环 |
| 第十一周11.09-11.15 | 520 | 20小时 | 定义函数,调用函数 | 调用函数和定义函数易将变量弄混淆 |
| 第十二周11.16-11.22 | 550 | 28小时 | 多分支结构、字符型数据类型和逻辑运算符。 | 多分支结构容易弄错,逻辑运算符使用不熟练 |
| 第十三周11.23-11.29 | 540 | 30小时 | 多分支结构switch语句 | switch语句使用不熟练,容易出现漏掉符号的情况 |
| 第十四周11.30-12.06 | 510 | 20小时 | while和do-while结构 | 在while和do-while结构的循环体中添加判断和累加代码就很难弄清 |
| 第十六周11.14-12.20 | 510 | 19小时 | break、continue的使用,循环嵌套方法 | 多重循环中的运算步骤常常弄错 |
| 第一周03.01-03.07 | 510 | 20小时 | 回顾了数据类型和表达式,学习编写文件读写程序。 | 用代码把数据写入文件还不懂,学过的知识有点模糊了,新学的知识还有待消化。 |
(2)累积代码行和博客字数(5分)
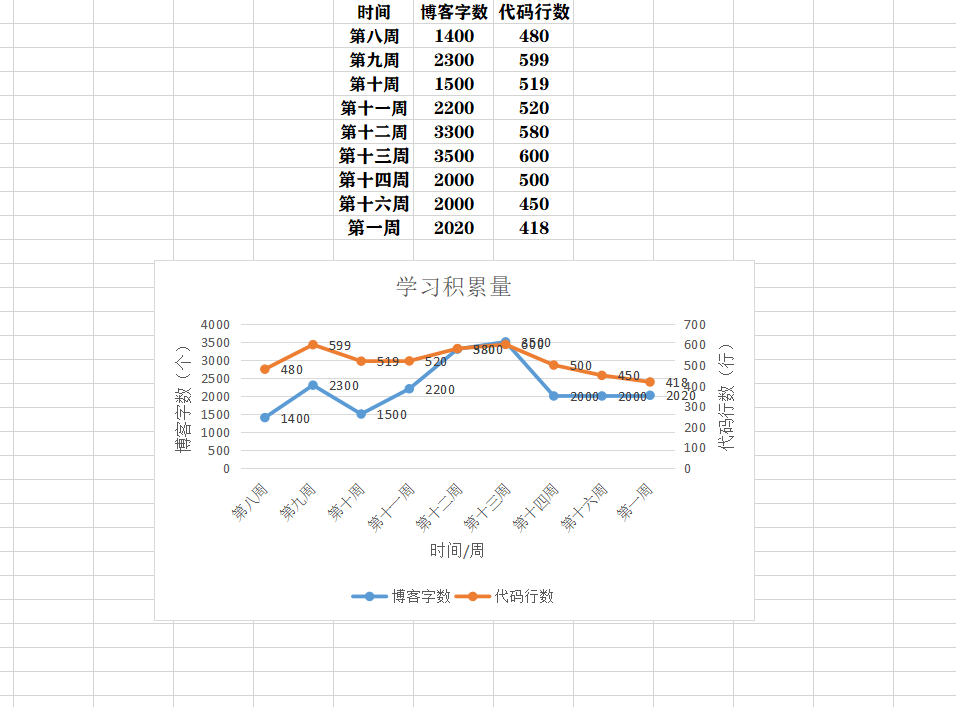
(3)学习内容总结和感悟(5分)
1.学习内容总结