MapReduce背景
在程序由单机版扩成分布式版时,会引入大量的复杂工作。为了提高开发效率,可以将分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。Hadoop 当中的 MapReduce 就是这样的一个分布式程序运算框架。
MapReduce是什么
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用” 的核心框架。
核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
MapReduce将整个并行计算过程抽象到两个函数:
Map(映射):对一些独立元素组成的列表的每一个元素进行制定的操作,可以高度并行。
Reduce(归约):归约过程,把若干组映射结果进行汇总并输出。
一个简单的MapReduce程序只需要指定Map()、reduce()、input和output,剩下的事情由框架完成。
基于MapReduce写出来的应用程序能够运行在大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。一个Map/Reduce 作业*通常会把输入的数据集切分为若干独立的数据块,由 /map任务(task)/以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给/reduce任务/。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
MapReduce的架构简单介绍
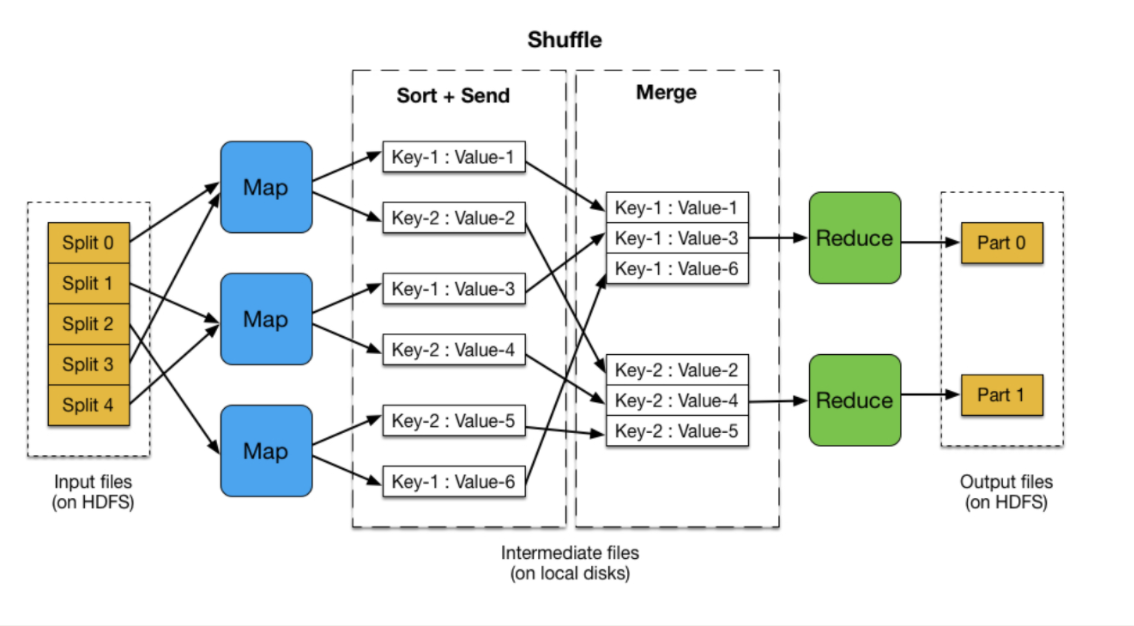
Input:输入文件的存储位置。可以是hdfs文件位置,也可以是本地文件位置
Map阶段:自己编写映射逻辑
Shuffle阶段:是我们不需要编写的模块,但却是十分关键的模块。Shuffle 阶段需要从所有 map主机上把相同的 key 的 key value对组合在一起,传给 reduce主机, 作为输入进入 reduce函数里。
Reduce阶段:自己编写合并逻辑
Final result: 最终结果存储在hdfs
MapReduce 更深层次分析后续讲解