注意:
Parallel为并行:指多条垃圾收集器并行工作,但是此时用户先仍然处于等待状态;
Concurrent为并发 :指用户线程和垃圾收集线程同时执行,用户程序在继续运行,而垃圾收集先运行在另一个CPU上。
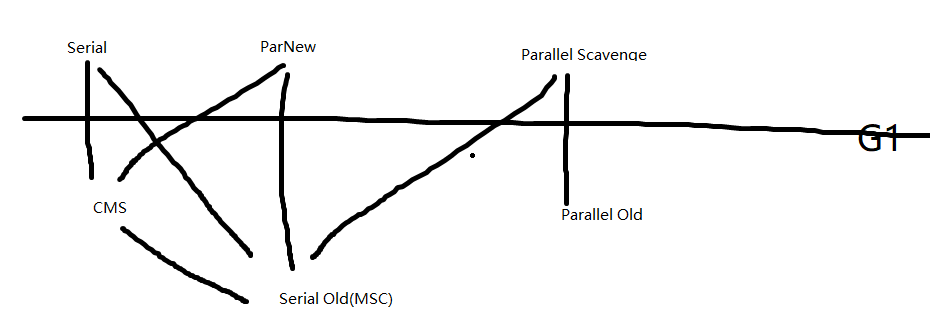
上图中包含了虚拟机中的所有收集器及相互协作的关系。
如果两个收集器连线,说明这两个收集器可以配合使用。
Serial收集器
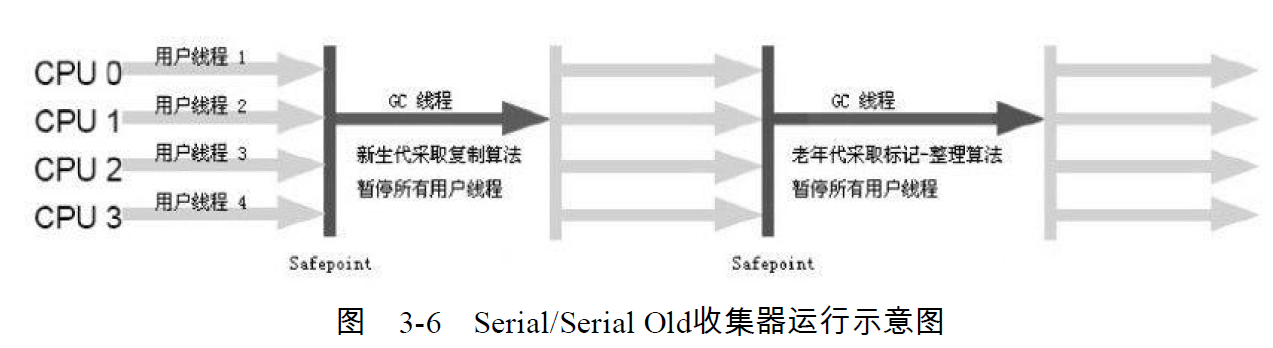
Serial收集器曾经是虚拟机新生代唯一的选择。
Serial收集器是虚拟机运行在client端下默认的新生代收集器。
它的优点是简单并且高效:Serial收集器由于没有线程交换的开销,专心做;垃圾收集自然可以获得最高的单线程收集效率。
这个收集器是单线程的收集器:说明仅仅它只会使用一个CPU或者一条收集线程去完成垃圾收集工作。
更重要的是:它在垃圾回收时必须停止其他所有工作线程,即进行Stop The World,直到它收集完毕。
ParNew收集器
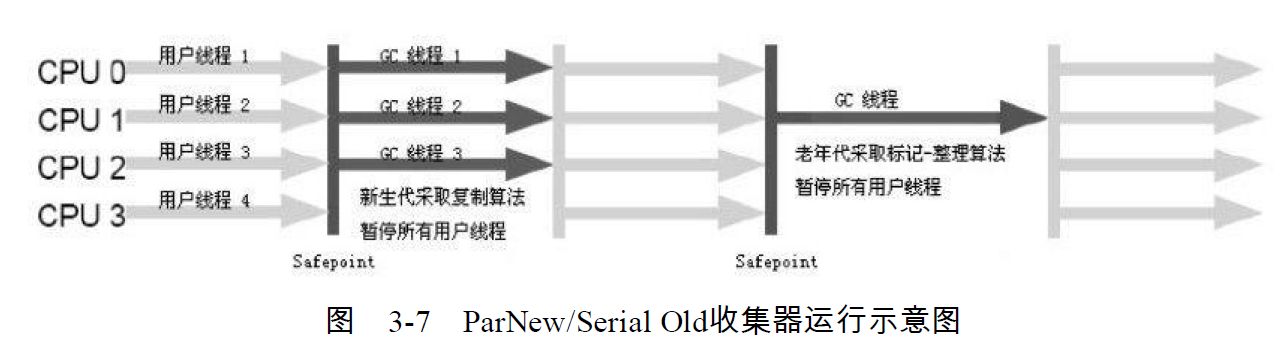
ParNew收集器是Serial收集器的多线程版本。
参数:-XX:SurviorRatio、 -XX:PretemureSizeThreshold等
收集算法、Stop The World、对象分配、回收策略都与Serial收集器完全一样;
它是运行在Server模式下的虚拟机首选新生代收集器。
ParNew是唯一一个可以与老年单CMS收集器配合使用的新生代收集器;
可以通过设置-XX:+UseConMarkSweepGC选项来设置默认的新生代收集器为ParNew;
也可以是有送-XX:+UseParNewGC来强制在新生代中使用;
ParNew收集器在单CPU绝对不会有Serial收集器好,因为它有线程交互的开销。
可以通过-XX:ParallelGCThreads参数来限制垃圾收集的线程数;
Parallel Scavenge收集器
Parallel Scavenge是一个新生代收集器
Parallel Scavenge经常被称为“吞吐量优先收集器”;
它也是用复制算法
是并行的多线程收集器
Parallel Scavenge的目标是达到一个可控的吞吐量,所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量=运行用户线程时间/(运行用户线程时间+垃圾收集时间)。
高吞吐量可以高效率的利用CPU时间,尽快完成程序的运行任务
适合在后台运算而不需要太多交互的任务;
Parallel Scavenge提供了两个参数用于精确控制吞吐量:
- 控制最大垃圾收集停顿时间的-XX:MaxGCPauseMillis
MaxGCPauseMillis参数可以尽可能的保证内存回收花费的时间不超过设置值
不过该参数设置的越小即GC停顿时间越少,会牺牲吞吐量和新生代空间。
- 吞吐量大小的-XX:GCTimeRatio参数;
该值介于1到100之间,也就是垃圾收集时间占总时间的比例,相当于吞吐量的倒数,如果把该参数设置为19,则表示1/(1+19),默认值为99.
Parallel Scavenge总有一个重要的开关:-XX:UseAdaptiveSizePolicy,如果打开该参数,就不需要手动设置新生代的大小(-Xmn)、Eden与Survior区的比例、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数。虚拟机会根据当前系统的运行情况收集性能检测信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种方式成为GC自使用的调整策略(GC Ergonomics)。