用Python爬取一个网站图片
先看看主页的规律
这是他的地址:https://pic.netbian.com/4kfengjing/
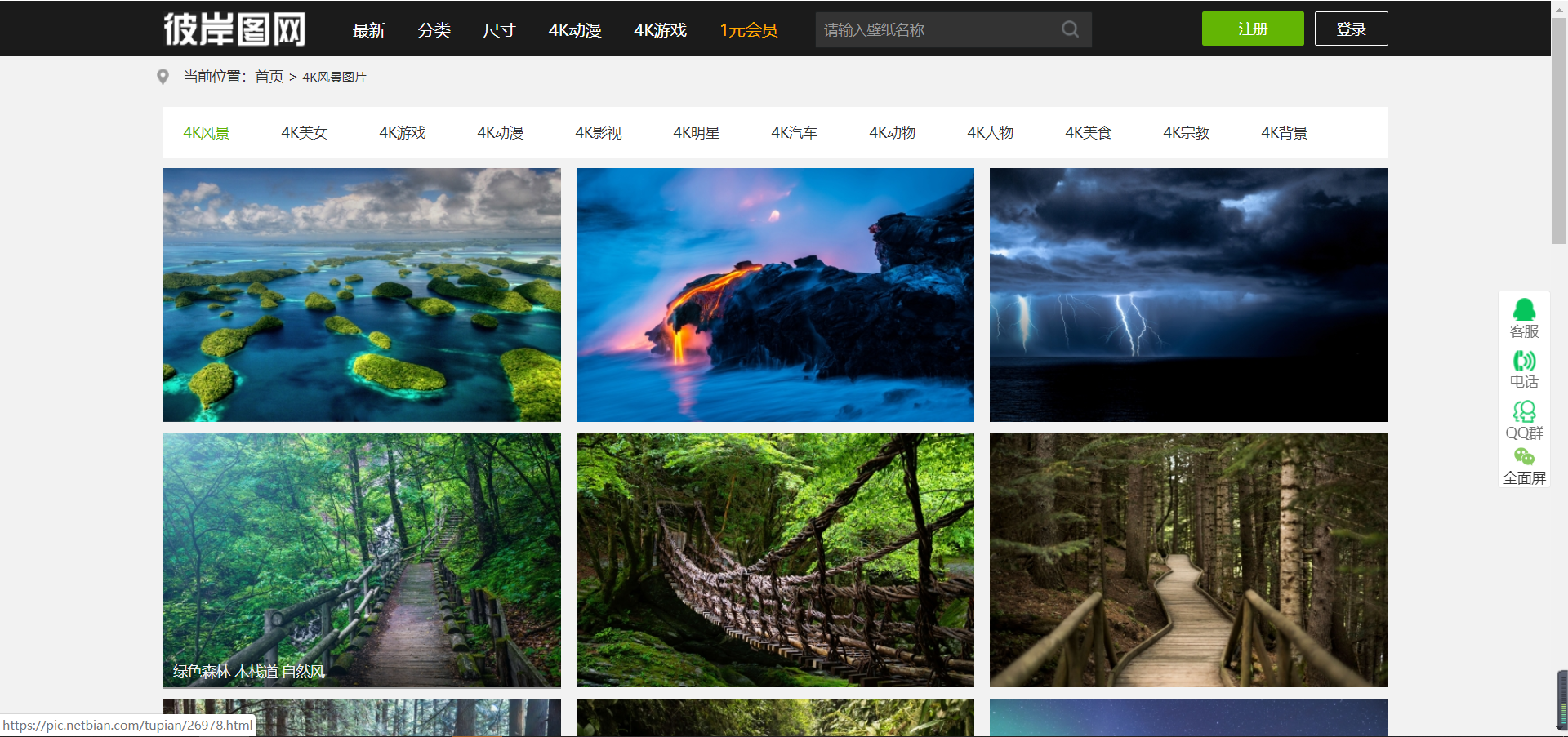
它有200多页
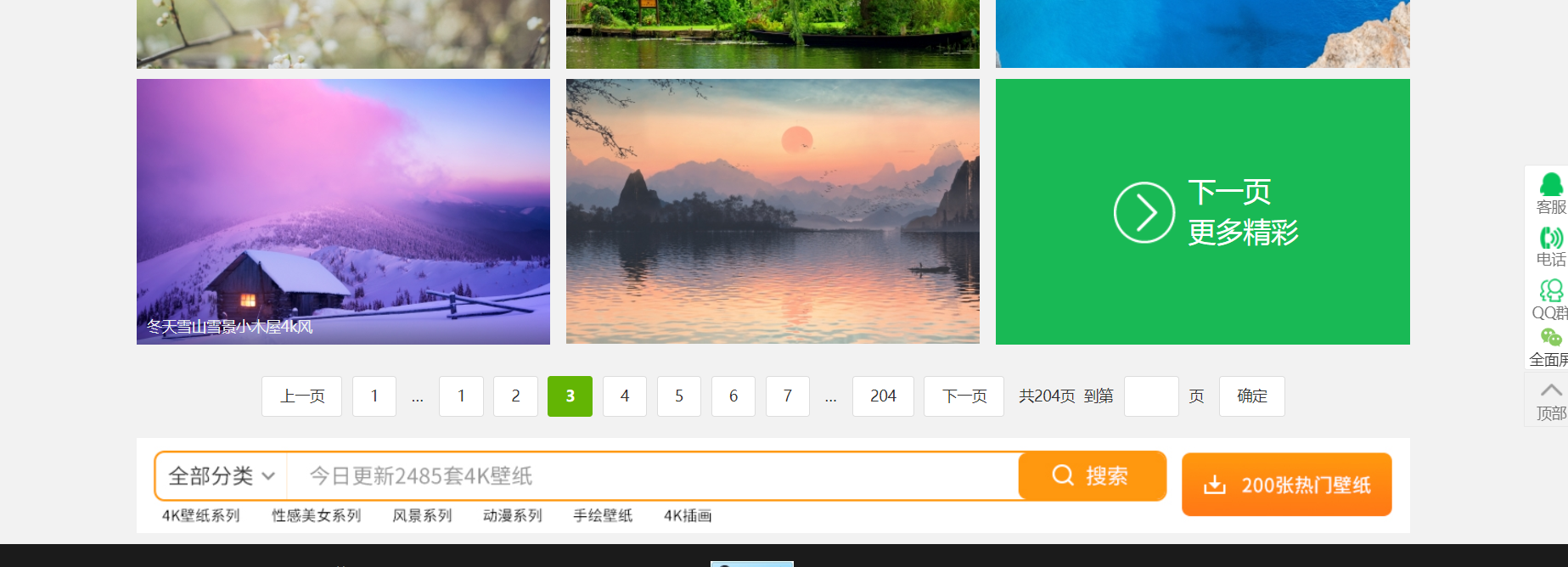
第3页的地址

第4页的地址

发现规律!
第i页的地址为:https://pic.netbian.com/4kfengjing/index_i.html
再看看图片的规律
F12按一下看看

按照箭头顺序进行元素审查看看
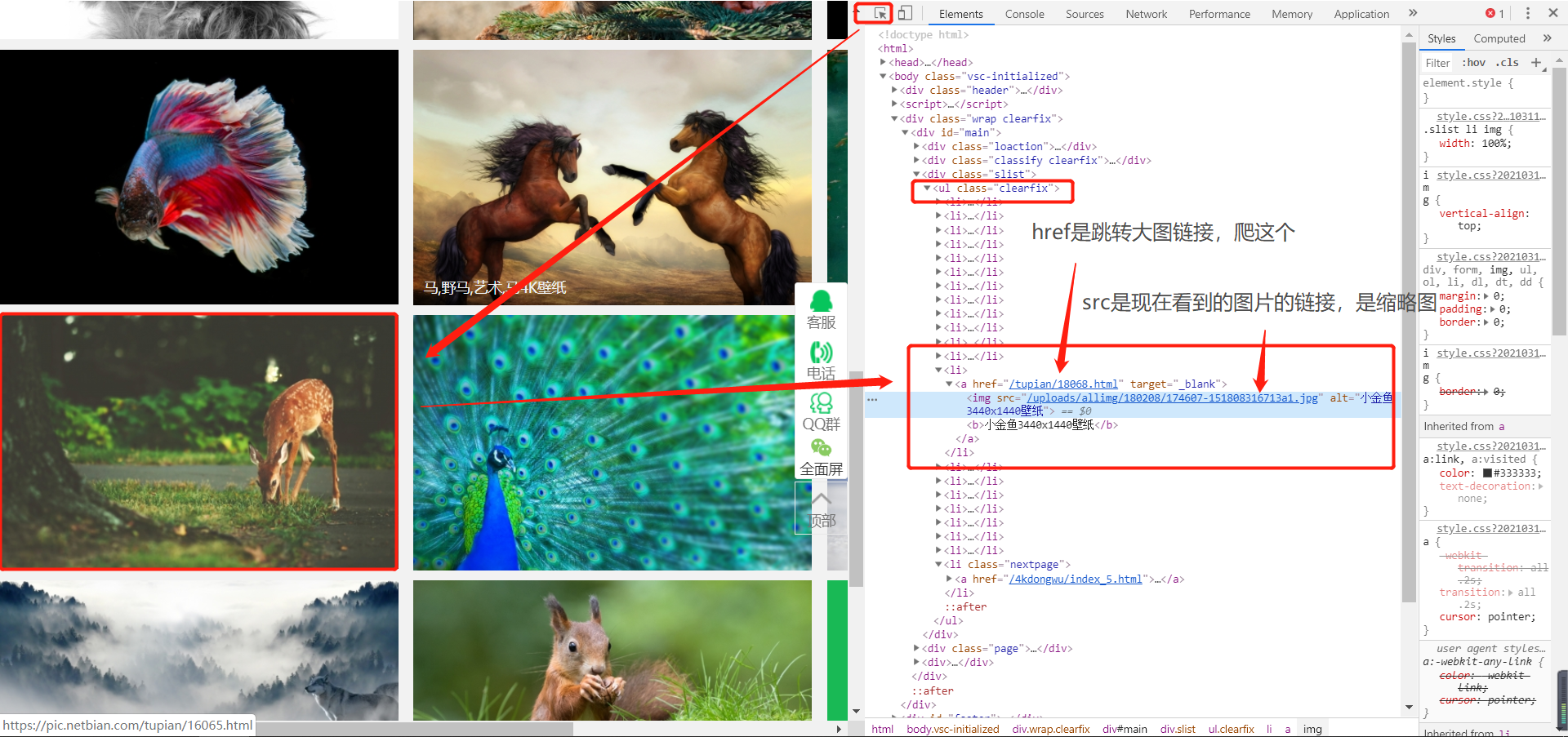
点进跳转页面看看
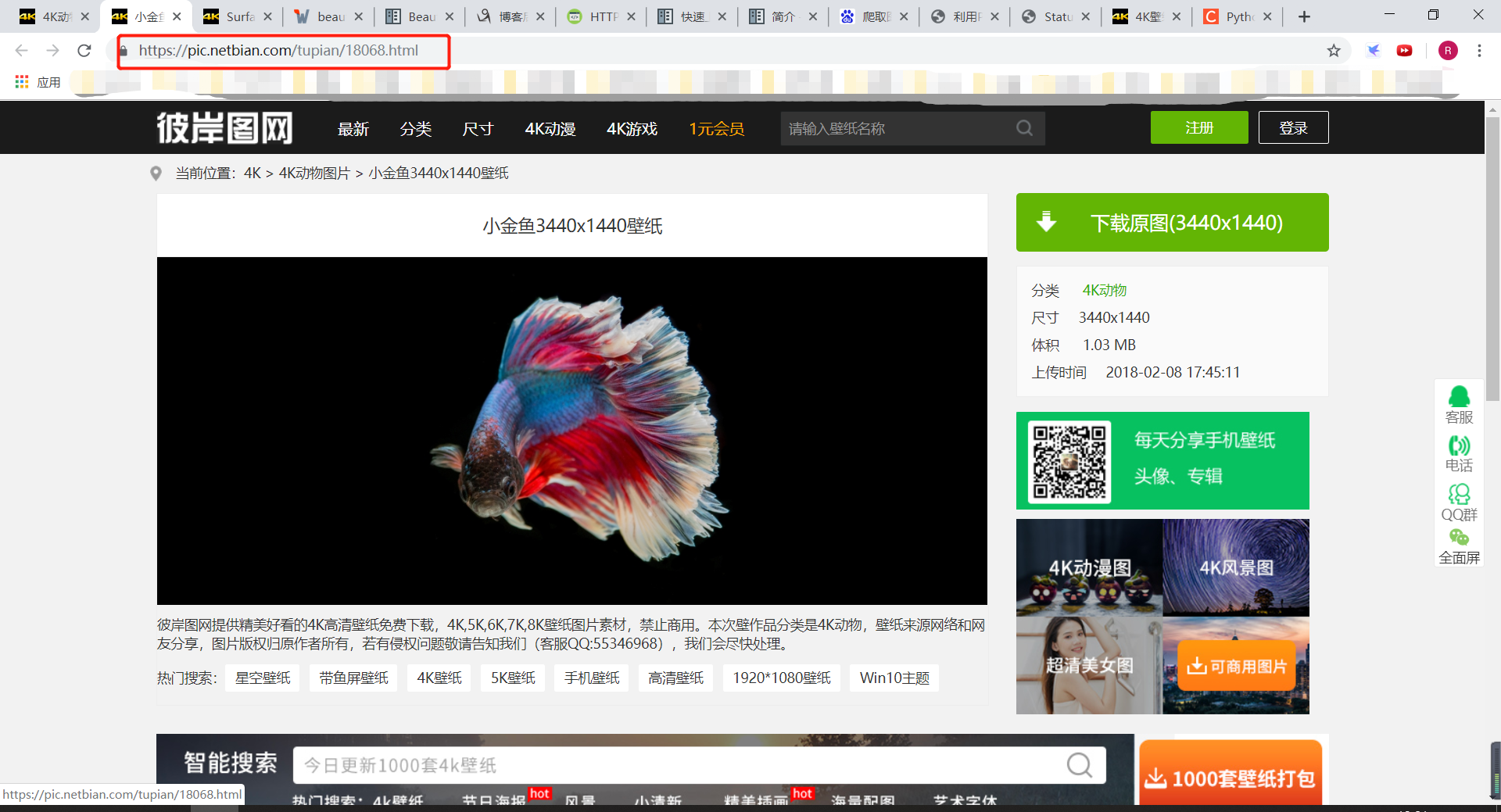
可以发现,跳转页面的url规律,是主页https://pic.netbian.com/拼接上刚刚找到的那个href

对跳转页面进行元素审查

注意
直接上代码
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 1 11:40:22 2021
@author: koneko
"""
import requests
from bs4 import BeautifulSoup
#主页地址
home = 'https://pic.netbian.com'
headers={'User-Agent':'ozilla/5.0 (Windows NT10.0; WOW64
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/70.0.3538.25 Safari/537.36
Core/1.70.3870.400 QQBrowser/10.8.4405.400'}
n = 0 #下载的图片的序号
k = 2 #从第二页开始爬起
while k < 100: #爬取100个页面的照片
#获取主页面
url = 'https://pic.netbian.com/4kfengjing/index_'+str(k)+'.html'
response = requests.get(url, headers = headers)
response.encoding = 'gb18030'
soup = BeautifulSoup(response.text,'html.parser')
index_page = requests.get(url, headers = headers)
index_page.encoding = 'gb18030'
soup = BeautifulSoup(index_page.text,'html.parser')
#获取页面中 class="clearfix" 的ul板块,缩略图都在里面
clearfix = soup.find("ul", class_ = "clearfix")
#找到每一张图片的链接所在的<a>
a_list = clearfix.find_all('a')
#处理处最后一张的所有缩略图
for i in range(len(a_list)-1):
#拼接得到图片大图跳转页面的url
newurl = home+a_list[i]['href']
r = requests.get(newurl)
newpage = BeautifulSoup(r.text, 'html.parser')
#获取图片所在板块
photo_pic = newpage.find(id="img")
#获取图片下载链接
pic_url = home+photo_pic.find('img')['src']
#下载图片
pic = requests.get(pic_url)
#图片保存的路径
save_path = r'E:爬虫图片\'+str(n)+'.jpg'
print('正在保存第'+str(n)+'张图片...')
#以二进制写的形式打开
f = open(save_path,'wb')
f.write(pic.content)
n += 1
k += 1
最后效果