Hadoop安装
http://hadoop.apache.org/releases.html
CentOS 下载 http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
下载后解压
tar zxf hadoop-3.0.0.tar.gz
把解压后的文件自己定义的目录,这里为 /usr/local/hadoop/
设置JAVAHOME
如果不知道可以通过java -verbose 查看
export JAVA_HOME=/usr/java/jdk1.8.0_112/
查看Java版本
java -version
设置HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使用以下指令判断Hadoop是否工作
hadoop version

配置SSH
apt-get install ssh
centos7 默认安装了ssh,不用上面的命令
基于空口令创建一个新SSH密钥,以实现无密码登陆
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
用以下指令测试
ssh localhost

因为我们此时用root登陆,需要编辑以下文件
编辑vi /usr/local/hadoop/sbin/start-yarn.sh
在顶部添加用户
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
编辑vi /usr/local/hadoop/sbin/start-dfs.sh
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
3.0版本后HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER
启动HDFS和YARN守护进程
/usr/local/hadoop/sbin/start-dfs.sh
/usr/local/hadoop/sbin/start-yarn.sh
如果启动yarn报错如下: localhost: ERROR: JAVA_HOME is not set and could not be found.
需在etc/hadoop/hadoop-env.sh 中写入JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_211/
如果发现dataNode没有启动,
是因为之前多次格式化namenode导致的namenode与datanode之间的不一致。
所以需要删除之前配置的data目录(即为dfs.data.dir所创建的文件夹),然后将temp文件夹与logs文件夹删除,重新格式化namenode;
可以在logs/hadoop-root-namenode-node02.log日志中看到

如果看到如下警告
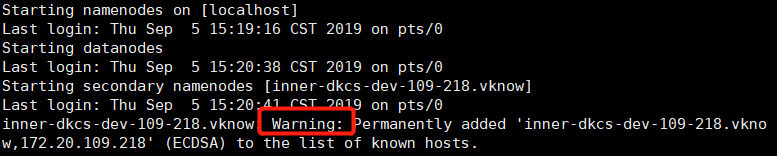
参考https://blog.csdn.net/mmake1994/article/details/79715359
namenode端口:9870
datanode端口:9864
NodeManager:8042
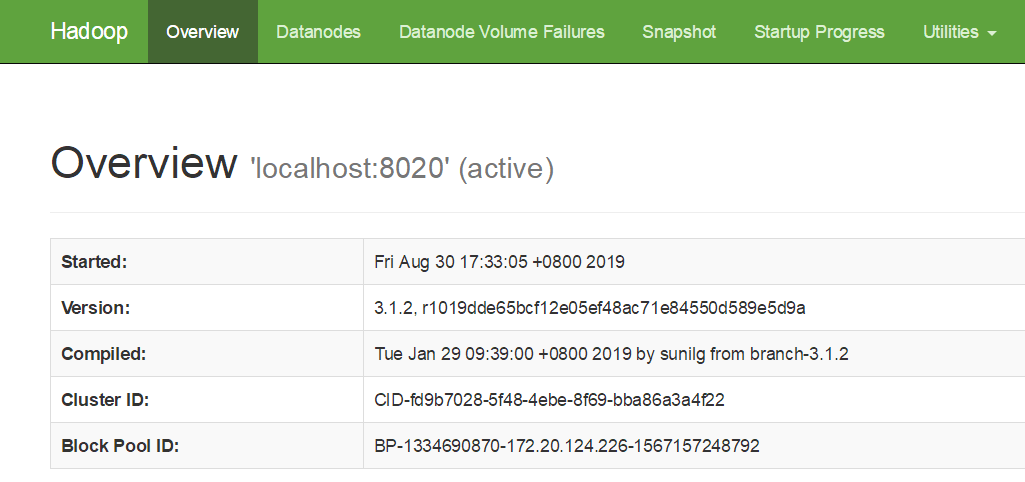
YARN的资源管理器Web地址:http://localhost:8088
打开防火墙端口
firewall-cmd --zone=public --add-port=8088/tcp --permanent firewall-cmd --reload
执行命令
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/<username> $ bin/hdfs dfs -put etc/hadoop input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+' $ bin/hdfs dfs -get output output $ cat output/*
如果出现hadoop找不到或无法加载主类,org.apache.hadoop.mapreduce.v2.app.MRAppMaster
1.输入命令 hadoop classpath
2.将输出的内容直接复制到yarn-site.xml文件中


<configuration>
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop-3.1.2//etc/hadoop:/opt/hadoop-3.1.2//share/hadoop/common/lib/*:/opt/hadoop-3.1.2//share/hadoop/common/*:/opt/hadoop-3.1.2//share/hadoop/hdfs:/opt/hadoop-3.1.2//share/hadoop/hdfs/lib/*:/opt/hadoop-3.1.2//share/hadoop/hdfs/*:/opt/hadoop-3.1.2//share/hadoop/mapreduce/lib/*:/opt/hadoop-3.1.2//share/hadoop/mapreduce/*:/opt/hadoop-3.1.2//share/hadoop/yarn:/opt/hadoop-3.1.2//share/hadoop/yarn/lib/*:/opt/hadoop-3.1.2//share/hadoop/yarn/*</value>
</property>
</configuration>
重启即可。
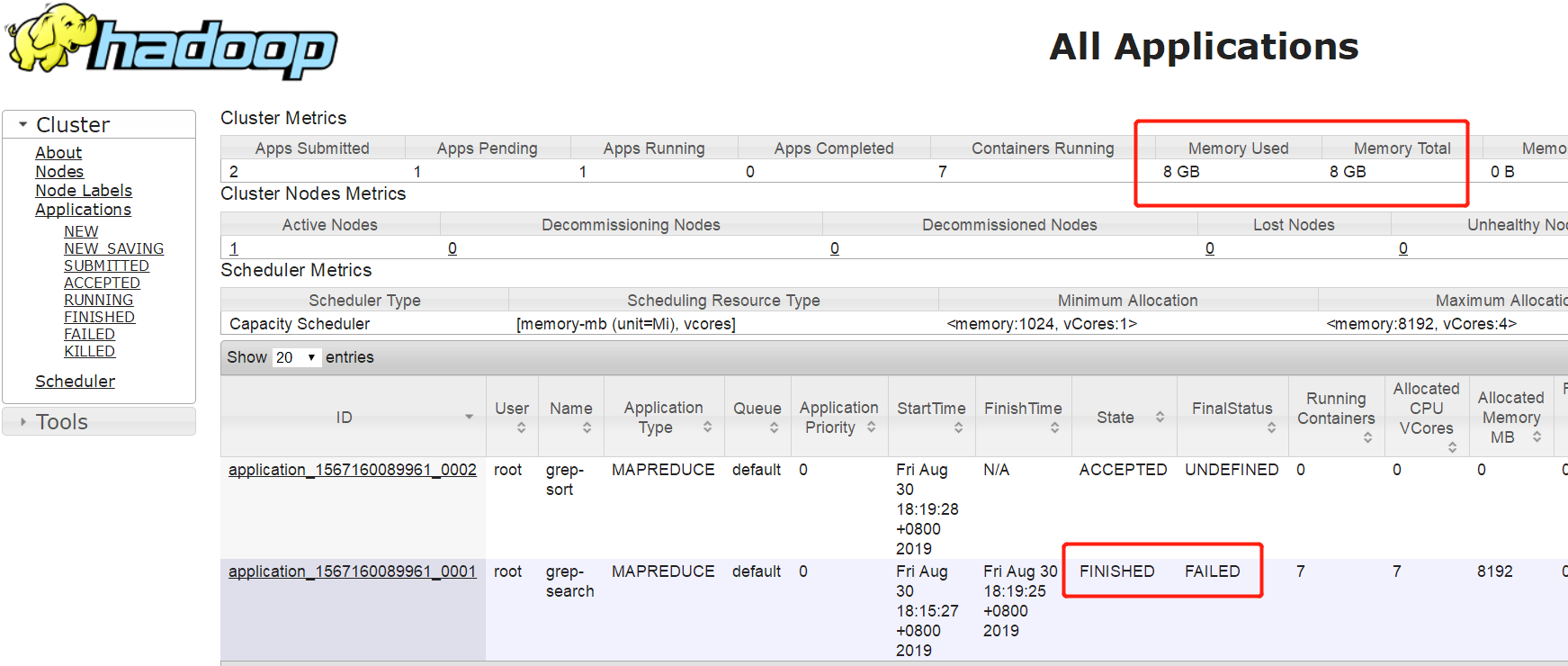
跑第一次失败了,原因是8G的内存不够用。。。自动创建了第二次任务
程序访问
使用maven新建工程hadoopdemo,添加依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
定义Mapper
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class MaxTemperatureMapper extends Mapper<LongWritable,Text,Text,IntWritable> { private static final int MISSING=9999; @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line=value.toString(); String year=line.substring(15,19); int airTemperature; if(line.charAt(87)=='+'){ airTemperature=Integer.parseInt(line.substring(88,92)); }else{ airTemperature=Integer.parseInt(line.substring(87,92)); } String quality=line.substring(92,93); if(airTemperature!=MISSING&&quality.matches("[01459]")){ context.write(new Text(year),new IntWritable(airTemperature)); } } }
定义Reducer
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MaxTemperatureReducer extends Reducer<Text,IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue=Integer.MIN_VALUE; for(IntWritable value:values){ maxValue=Math.max(maxValue,value.get()); } context.write(key,new IntWritable(maxValue)); } }
定义主程序
import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MaxTemperature { public static void main(String[] args) throws Exception { if(args.length!=2){ System.err.println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } Job job=new Job(); job.setJarByClass(MaxTemperature.class); job.setJobName("Max temperature"); FileInputFormat.addInputPath(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); job.setMapperClass(MaxTemperatureMapper.class); job.setReducerClass(MaxTemperatureReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true)?0:1); } }
使用maven打包
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
如果是springboot应用,需要注意这里的打包插件使用的是如上配置
将jar包上传至CentOS中,这里放到/opt/hadoop/ncdc/
下载测试数据:https://github.com/tomwhite/hadoop-book/tree/master/input/ncdc/all
这里下载1901.gz ,解压到当前目录
gunzip 1901.gz

运行测试
export HADOOP_CLASSPATH=hadoop-demo.jar
hadoop org.mythsky.hadoopdemo.MaxTemperature 1901 output
这里的 org.mythsky.hadoopdemo是包名,如果没有放在包内直接使用类名即可,第三个参数是输入文件,第四个参数是输出目录
运行过程
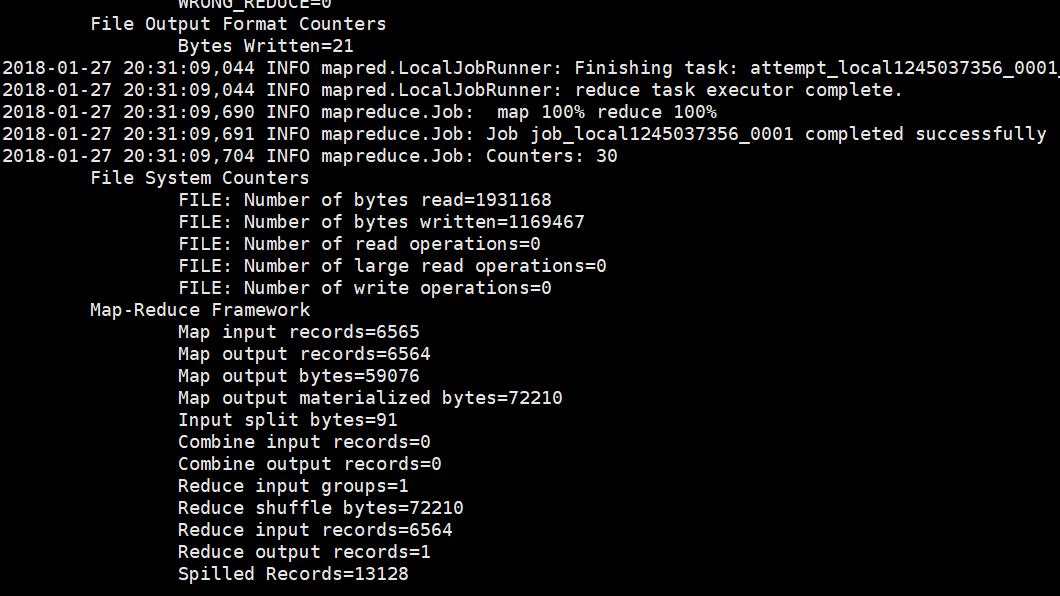
查看输出目录

查看文件

这里即使计算结果。