Hadoop的全分布式安装网上也很多教程,踩过很多坑,整理不出来了……赶紧把增加删除节点留住。
均衡数据
(1)设置数据传输带宽为64M(默认值比较低)
hdfs dfsadmin -setBalancerBandwidth 67108864

(2)平衡数据,默认balancer的threshold为10%,即各个节点存储使用率偏差不超过10%,我们可将其设置为1%(1~100)
./sbin/start-balancer.sh -threshold 1
或者hdfs balancer -threshold 1(显示平衡过程)
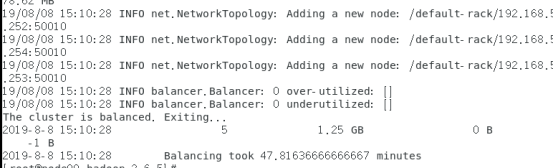
从hadoop的web页面可以观察到各个节点的存储使用率更接近了
1.增加节点
已有CentOS 7的虚拟机node00(namenode)、node01(datanode)、node02(datanode),虚拟机上都有JDK1.8.0_45,Hadoop-2.6.5。准备一个新的虚拟机node03(datanode)。
为了方便,选择克隆虚拟机node02,克隆后修改新虚拟机node03的配置:
(1)删除logs和core-site.xml配置文件中hadoop.tmp.dir的目录
rm -rf /usr/local/hadoop-2.6.5/logs/*.*
rm -rf /usr/local/hadoop-2.6.5/tmp/*
(2)删除hdfs-site.xml配置文件中datanode.data.dir目录
rm -rf /app/hadoop/data/*
(3)修改主机名、IP地址
vi /etc/sysconfig/network
vi /etc/sysconfig/network-scripts/ifcfg-ens33
然后修改所有虚拟机的配置(加上新节点):
(1)/etc/hosts
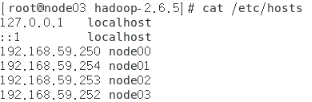
(2)Slaves

设置无密码访问node03(在node00生成密钥并分发给其他虚拟机)
ssh-keygen -t rsa
scp -p ~/.ssh/id_rsa.pub node01@192.168.59.254:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub node02@192.168.59.253:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub node03@192.168.59.252:/root/.ssh/authorized_keys
启动node03的datanode和nodemanager
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
刷新hadoop 的web页面即可看的新的节点。如果原节点中有数据,会自动分给新节点一定量的数据
2. 删除节点
在namenode中打开hdfs-site.xml,设置节点排除文件的位置(绝对路径)
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop-2.6.5/etc/hadoop/excludes</value>
</property>
在路径中新建文件excludes,并在文件中添加要排除的节点主机名
在namenode中强制重新加载配置
hdfs dfsadmin -refreshNodes
在hadoop的web页面上看到该节点变成Decommission,此时namenode会检查并将数据复制到其它节点上以恢复副本数(要移除的节点上的数据不会被删除,如果数据比较敏感,要手动删除它们)。
通过命令也可以查看状态:
hdfs dfsadmin -report
等状态变成Decommissioned后就可以关闭该节点
hadoop-daemon.sh stop datanode
几分钟后,节点将从Decommissioned进入Dead状态。
最后更新集群配置,从namenode的excludes文件及slaves文件、hosts文件中去掉已经移除的主机名,在所有DataNode上执行hadoop-pull.sh脚本,同步配置。
删除的节点可以清空数据重新使用
rm -rf /usr/local/hadoop-2.6.5/logs/*.*
rm -rf /usr/local/hadoop-2.6.5/tmp/*
rm -rf /app/hadoop/data/*
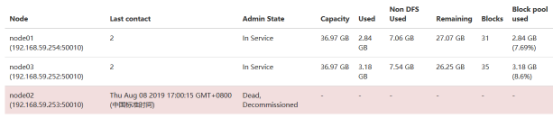
原始数据分布

自动备份中
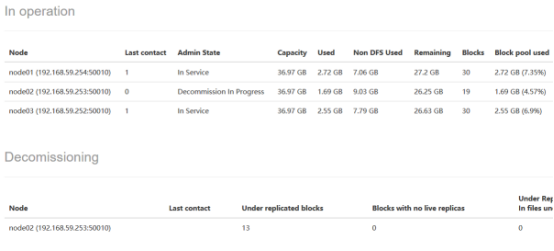
自动备份后

删除节点后