ASC与HEX之间的转换
有这么两个函数:
|
函数 |
原型 |
功能 |
返回值 |
参数 |
备注 |
|
hex2asc |
__int16 hex2asc(unsigned char *strhex,unsigned char *strasc,__int16 length); |
字符串转换函数,十六进制字符转换成普通字符 |
成功则返回 0,否则返回非0 |
strhex:要转换的字符 strasc:转换后的字符 length:字符strasc的长度 |
长转短 |
|
asc2hex |
__int16 asc2hex(unsigned char *strasc,unsigned char *strhex,__int16 length); |
字符串转换函数,普通字符转换成十六进制字符 |
成功则返回0,否则返回非0 |
strasc:要转换的字符 strhex:转换后的字符 length:字符strasc的长度 |
短转长 |
我们首先对这两个函数进行的测试如下:
// hex2asc和asc2hex的测试程序 #include "dculd.h" #include <iostream> using namespace std; #pragma comment(lib, "dculd.lib") int main() { unsigned char strhex[101] = "0123456789ABCDEF"; //unsigned char strhex[101] = "0123456789ABCD8"; unsigned char strasc[101] = {0}; hex2asc(strhex, strasc, 8); cout << "strhex: " << strhex << endl; cout << strlen((const char*)strhex) << endl; cout << strasc << endl; cout << strlen((const char*)strasc) << endl; cout << endl << "strasc DEC: "; for (int i = 0; i < strlen((const char*)strasc); ++i) { cout << dec << (int)strasc[i] << ' '; } cout << endl << "strasc HEX: "; for (int i = 0; i < strlen((const char*)strasc); ++i) { cout << hex << "0x" << (int)strasc[i] << ' '; } cout << endl; cout << endl; unsigned char strhex_2[101] = {0}; asc2hex(strasc, strhex_2, 8); cout << "strhex_2: " << strhex_2 << endl; return 0; }
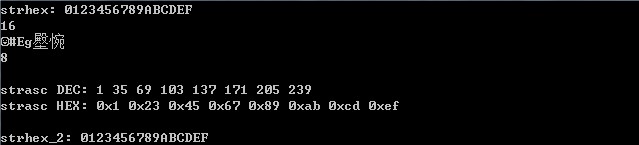
hex2asc和asc2hex这两个函数本质上都是字符串转换函数。其中,hex2asc的被转化参数strhex为字符串”0123456789ABCDEF”,该字符串表示的是十六进制的值,每个元素相当于4个bit的值,所以每两位相当于一个byte。该字符串每个元素的取值范围为0~9和A~F,总共16个值,即16进制的16个数字。
转换后的参数strasc为字符串” #Eg壂惋”,该字符串的长度为8,每个元素的ASCII值为:
十进制:1 35 69 103 137 171 205 239
十六进制:0x1 0x23 0x45 0x67 0x89 0xab 0xcd 0xef
具体转换的规则为strhex中的两个元素的字符串所代表的十六进制数,转换为一个byte的ASCII值,然后将其存储到strasc中,所以strhex的长度为strasc长度的两倍。
相应地,asc2hex函数是将strasc字符串中每个元素实际的ASCII值以十六进制的形式转换为字符串,即用strhex存储。
这里的转换是用的十六进制,strhex中的字符串都是以十六进制的形式存在,因为每个元素的值为0~9和A~F,所以hex2asc函数中的转换操作必须是16进制的处理。asc2hex中也必须是十六进制的处理,如果改用十进制、八进制等其他进制操作,转换后的strhex中的字符必定与原来的strhex不同,并且元素个数也有可能不同。
关于为什么使用十六进制,这是我们预先规定的。如果不涉及A~F的字符,完全可以用十进制进行操作。
另一个问题是为什么要进行hex和asc之间的转换?hex更便于程序员自身识别,而asc更便于计算机识别,所以为了使得程序员更好的识别机器指令,在书写的时候才有strhex的形式进行书写,而非直接的strasc形式。机器执行字节码指令的时候必然需要strasc的形式,所以需要hex2asc函数进行相应的转换。asc2hex函数的作用是将机器返回的字节码数据更友好地呈现给程序员识别,所以需要将asc转换为hex的形式。通知hex2asc和asc2hex的转换,既有利于程序员的指令识别,也有利于机器的指令识别。
另外,用字节存储十六进制的字符标识,可以节省空间,一个字节可以存储两个十六进制字符,如果感兴趣,可以阅读《字节存储数据》。
一般情况下,一个指令字节是八位,必然对应于strhex中的2个元素,所以,strhex的长度一般情况下都是偶数的,对于基数的情况上述hex2asc函数会导致转换错误:
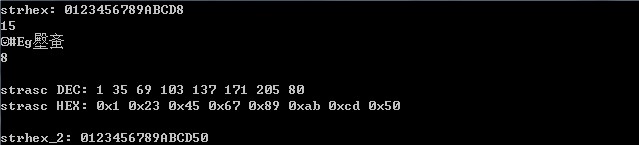
对于最后一个单独的元素’8’,hex2asc函数将其转换为字节:0x50,十进制的80,两个strhex元素对应于一个strasc元素,所以当strhex的长度为奇数时会存在这种情况。asc2hex函数不会存在这种问题,因为asc2hex是将strasc中的每个元素转换为strhex中的两个元素,不存在奇偶性的问题。
针对以上奇偶性的问题,我们队hex2asc进行相应的改进,使其可以处理strhex长度为奇数的情况,当然针对字节指令一般情况下不会存在这种问题,因为如果strhex长度为奇数,hex2asc应该返回错误信息。对hex2asc改进的同时,需要对asc2hex进行改进,使其可以处理strhex长度为奇数的情况。
另外,hex2asc和asc2hex第三个参数length是标识了字节指令的字节个数,即strasc和strhex都可以支撑length,也就是说strasc的长度大于等于length,strhex的长度大于等于length*2。在我们的实现代码中,length的意义有所改变,HexToAsc的length参数是指的转换strhex的元素个数,所以length可以为奇数。AscToHex的length参数是指的转换strasc的元素个数,length可以向原来的参数那样可以是偶数也可以是奇数。但是length的值在HexToAsc中需要小于等于strhex的元素个数,在AscToHex中需要小于等于strasc的元素个数,在两个函数中需要同时考虑处理strhex奇数长度的情况。
下面我们对hex2asc和asc2hex进行重新实现,具体代码如下:
// hex2asc和asc2hex的重实现,可以处理strhex长度为奇数的情况 #include <iostream> using namespace std; // 将a~f转换为A~F unsigned char ToUpperHex(unsigned char& ch) { if (ch >= 'a' && ch <= 'f') { ch = 'A' + ch - 'a'; } return ch; } // 检测ch是否为十六进制字符 bool IsHex(unsigned char ch) { return ch >= '0' && ch <= '9' || ch >= 'A' && ch <= 'F' || ch >= 'a' && ch <= 'f'; } int HexVal(unsigned char ch) { if (ch >= '0' && ch <= '9') { return ch - '0'; } else if (ch >= 'A' && ch <= 'F') { return 10 + ch - 'A'; } else if (ch >= 'a' && ch < 'f') { return 10 + ch - 'a'; } else { return -1; } } unsigned char ValHex(int val) { if (val >= 0 && val <= 9) { return val + '0'; } else if (val >= 10 && val <= 15) { return val - 10 + 'A'; } else { return '$'; } } int HexToAsc(unsigned char* strhex, unsigned char* strasc, int length) { //if (length % 2 == 1) // length表示转换strhex的元素个数,如果严格要求只能转换偶数个,这里可以进行判断 //{ // return -1; //} if (length > strlen((const char*)strhex)) { length = strlen((const char*)strhex); } // 检测strhex是否合法,是否存在非0~9、A~F、a~f字符 for (auto i = 0; i != length; ++i) { if (!IsHex(strhex[i])) { return -2; } } // 以下for-if结构可以同时处理奇偶的情况 int pos = 0, i = 0; for (i = 0; i < length - 1; i += 2) { unsigned char tmp = HexVal(strhex[i]) * 16 + HexVal(strhex[i + 1]); strasc[pos++] = tmp; } if (i == length - 1) { unsigned char tmp = HexVal(strhex[i]) * 16; strasc[pos++] = tmp; // 用来标识length的奇偶,这里是奇数 strasc[pos++] = 1; } else { // 用来标识length的就,这里偶数 strasc[pos++] = 2; } strasc[pos++] = 0; return 0; } int AscToHex(unsigned char* strasc, unsigned char* strhex, int length) { length = length <= strlen((const char*)strasc) - 1 ? length : strlen((const char*)strasc) - 1; // strasc中的元素不存在合不合法的情况,所以不做检测 int i = 0, pos = 0; for (i = 0; i < length - 1; ++i) // 这里先处理length-1个字符,第length个字符后续处理,因为需要考虑奇偶的情况 { strhex[pos++] = ValHex(strasc[i] / 16); strhex[pos++] = ValHex(strasc[i] % 16); } if (strasc[strlen((const char*)strasc) - 1] == 1) // 奇数的情况 { strhex[pos++] = ValHex(strasc[length - 1] / 16); } else if (strasc[strlen((const char*)strasc) - 1] == 2) // 偶数的情况 { strhex[pos++] = ValHex(strasc[length - 1] / 16); strhex[pos++] = ValHex(strasc[length - 1] % 16); } strhex[pos++] = 0; return 0; } int main() { unsigned char strhex[101] = "0123456789ABCDEF"; //unsigned char strhex[101] = "0123456789ABCD8"; unsigned char strasc[101] = {0}; HexToAsc(strhex, strasc, 16); // 这里的16标识的是转换strhex的元素个数 //HexToAsc(strhex, strasc, 15); // 这里的15标识的是转换strhex的元素个数 cout << "strhex: " << strhex << endl; cout << strlen((const char*)strhex) << endl; cout << strasc << endl; cout << strlen((const char*)strasc) << endl; cout << endl << "strasc DEC: "; for (int i = 0; i < strlen((const char*)strasc); ++i) { cout << dec << (int)strasc[i] << ' '; } cout << endl << "strasc HEX: "; for (int i = 0; i < strlen((const char*)strasc); ++i) { cout << hex << "0x" << (int)strasc[i] << ' '; } cout << endl; cout << endl; unsigned char strhex_2[101] = {0}; AscToHex(strasc, strhex_2, 8); // 这里的8标识的是转换strasc的元素个数 cout << "strhex_2: " << strhex_2 << endl; return 0; }
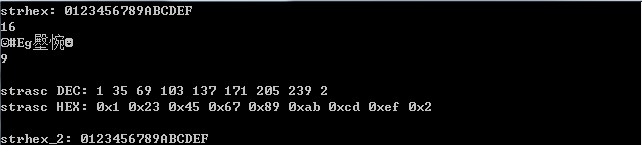
以上是针对length值为偶数的情况。如果length为奇数,我们有如下测试:
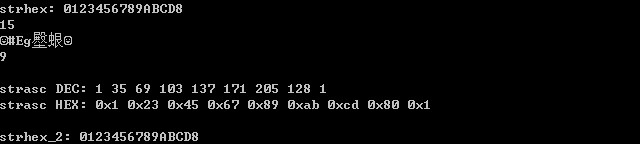
从测试中,我们可以看出,即便是转换奇数个strhex元素的情况,我们也可以照常进行处理。下面是我们对程序的说明:
这是我们的函数原型,其中length参数在HexToAsc中我们指代的是转换strhex的元素个数,既可以是偶数也可以是奇数。AscToHex中的length参数是标识转换strasc的元素个数,可以是偶数也可以是奇数。
int HexToAsc(unsigned char* strhex, unsigned char* strasc, int length);
int AscToHex(unsigned char* strasc, unsigned char* strhex, int length);
程序中我们定义了一下几个函数:
ToUpperHex,用来将a~f转换为A~F,我们并没有用到该函数。
IsHex,用来检测strhex的合法性。
HexVal,用来得到十六进制字符的实际值。
ValHex,用来根据实际值得到十六进制的字符,这里都是转换为A~F字符,而非a~f。
HexToAsc函数中,我们首先检测length的长度,如果大于strhex的长度,则将其更改为strhex的长度,然后检测strhex的合法性。根据for-if-else结构来处理length奇偶数的情况。我们在strasc最后一位设定了一个标识元素,用来标识length的奇偶性。该标识在AscToHex函数转换中也要用到。
AscToHex函数一开始也要检测length的长度,由于strasc最后一个元素是标示了奇偶性,所以我们需要检测length与strasc长度减一的关系。然后我们对0到length-2元素进行诸位转换,针对length-1元素,我们需要判断strasc最后一个元素的标识,根据其标识的奇偶性来进行转换。
通过我们重实现的HexToAsc和AscToHex,我们可以正常的处理转换strhex元素个数为奇数的情况。
需要注意的一点是,length参数标注的是要转换的元素个数,如果大于原来的元素个数,则全部转换,如果小于,则只转换length个元素。