ascii 编码
计算机内部,所有信息最终都是一个二进制值
上个世纪60年代,美国制定了一套字符编码ascii
ascii 编码就是定义:英语字符与二进制位之间的关系
unixcs
unicode编码
万国码, 是一种所有符号的编码
unixcs
UTF-8编码
utf-8 是以字节为单位对Unicode进行编码。
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
Unicode 和 ASCII
ASCII编码是1个字节,而Unicode编码通常是2个字节。
如果统一成Unicode编码,乱码问题从此消失了。
但是,如果你写的文本基本上全部是英文的话,
用Unicode编码比ASCII编码需要多一倍的存储空间,
在存储和传输上就十分不划算。
所以把Unicode编码转化为“可变长编码”的UTF-8编码。
UTF-8编码把一个Unicode字符根据不同的数字大小
编码成1-6个字节,常用的英文字母被编码成1个字节,
汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间
ASCII 和 UTF-8
ASCII编码实际上可以被看成是UTF-8编码的一部分
大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作
URL编码
URL 编码通常也被称为 百分号编码
编码方式:%百分号+两位的字符
字符编码工作方式
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
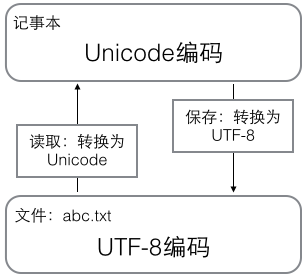
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
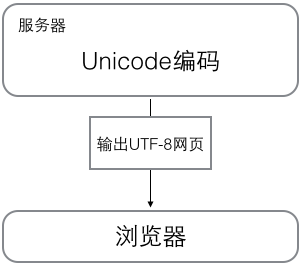
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
参考:https://blog.csdn.net/Deft_MKJing/article/details/79460485