前言
一直以来,对java对象大小的概念停留在基础数据类型,比如byte占1字节,int占4字节,long占8字节等,但是一个对象包含的内存空间肯定不只有这些。
假设有类A和B,当new A()或者new B()后,实际占用的java内存是多大呢?下面就对此进行详细分析。
static class A{ String s = new String(); int i = 0; } static class B{ String s; int i; }
对象大小分析
如图1,java对象在内存中占用的空间分为3类, 1. 对象头(Header); 2. 实例数据(Instance Data); 3. 对齐填充(Padding)。而我们常说的基础数据类型大小主要是指第二类实例数据。
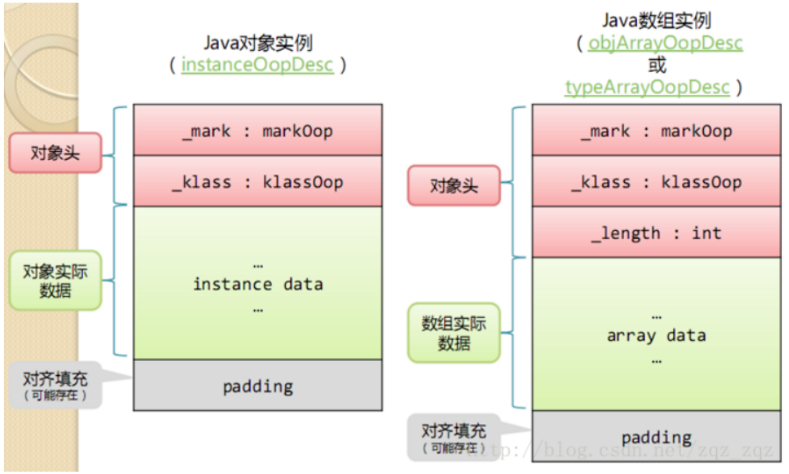
图1
对象头
HotSpot虚拟机的对象头包括两部分信息:
markword和klass 。第一部分markword,用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。 另外一部分是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
数组长度
如果对象是一个数组, 那在对象头中还必须有一块数据用于记录数组长度,也就是一个int类型的对象,占4字节。
对象头占用空间
1. 在32位系统下,存放Class指针的空间大小是4字节,MarkWord是4字节,对象头为8字节。
2. 在64位系统下,存放Class指针的空间大小是8字节,MarkWord是8字节,对象头为16字节。
3. 在64位开启指针压缩的情况下 -XX:+UseCompressedOops,存放Class指针的空间大小是4字节,MarkWord是8字节,对象头为12字节。
4. 如果对象是数组,那么额外增加4个字节
实例数据
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
对齐填充
最后一块对齐填充空间并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。这是由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,就是对象的大小必须是8字节的整数倍。
如何查看java对象大小
1. 基于JDK1.8
JDK1.8有一个类`jdk.nashorn.internal.ir.debug.ObjectSizeCalculator`可以评估出对象的大小
// 直接调用静态方法即可使用
ObjectSizeCalculator.getObjectSize(obj)
2. spark库
spark库中有一个类`org.apache.spark.util.SizeEstimator`
// 直接调用静态方法即可使用
SizeEstimator.estimate(obj)
3. 基于JDK1.5的Instrumentation
// 需要编译成jar调用,没有前者方便
案例
分析完对象的组成结构后,再回头来看那个问题
// 对象A: 对象头12B + 内部对象s引用 4B + 内部对象i 基础类型int 4B + 对齐 4B = 24B // 内部对象s 对象头12B + 2个内部的int类型8B + 内部的char[]引用 4B + 对齐0B = 24B // 内部对象str的内部对象char数组 对象头12B + 数组长度4B + 对齐0B = 16B // 总: 对象A 24+ 内部对象s 24B + 内部对象s的内部对象char数组 16B =64B class A { String s = new String(); int i = 0; } // 对象B:对象头12B + 内部对象s引用 4B + 内部对象i 基础类型int 4B + 对齐 4B = 24B // s没有被分配堆内存空间 // 总: 对象B 24B class B { String s; int i = 0; }
总结
对象在jvm中不是完全连续的,这是由于GC的原因,总会出现散乱的内存。这就导致了jvm必须为每个对象分配一段内存空间来存储其引用的指针,再结合对象的其他必须的元数据,使得对象在持有真实数据的基础上还需要维护额外的数据。
在写java代码需要小心这些jvm内存陷阱。
参考
// stackoverflow给出的几种计算对象大小方法