第十一章EXT2文件系统
0.知识点
本章首先描述了EXT2文件系统在Linux中的历史地位以及EXT3/EXT4文件系统的当前状况;用编程示例展示了各种EXT2数据结构以及如何遍历EXT2文件系统树;介绍了如何实现支持Linux内核中所有文件操作的EXT2文件系统;展示了如何通过虚拟磁盘的mount root来构建基本文件系统;将文件系统的实现划分为3个级别,级别1扩展了基本文件系统,以实现文件系统树,级别2实现了文件内容的读/写操作,级别3实现了文件系统的挂载1装载和文件保护;描述了各个级别文件系统函数的算法,并通过编程示例演示了它们的实现过程;将所有级别融合到一个编程项目中;最后,将所有编程示例和练习整合到一个完全有效的文件系统中。
1.EXT2文件系统
0.ext2文件系统的文件和目录的区别
一个ext2文件系统的文件或目录包括索引结点和数据块两个部分,索引结点存放文件的属性、存取权限、修改时间以及其他的一些信息,而数据块存放文件的内容。文件和目录不一样的地方:
- 目录:
当我们在 Linux 下的 ext2 档案系统建立一个目录时, ext2 会分配一个 inode 与至少一块Block 给该目录。其中,inode 记录该目录的相关属性,并指向分配到的那块 Block ;而 Block则是记录在这个目录下的相关连的档案(或目录)的关连性! - 档案:
当我们在 Linux 下的 ext2 建立一个一般档案时, ext2 会分配至少一个 inode 与相对于该档案大小的 Block 数量给该档案。例如:假设我的一个 Block 为 4 Kbytes ,而我要建立一个 100KBytes 的档案,那么 linux 将分配一个 inode 与 25 个 Block 来储存该档案。
1.通过mkfs创建虚拟磁盘
在Linux下,命令make2fs [-b blksize -N ninodes] device nblocks在设备上创建一个带有nblocks个块(每个块大小为blksize字节)和ninodes个索引节点的EXT2文件系统。
若未指定blksize,则默认块大小为1KB
若未指定ninoides,mke2fs将根据nblocks计算一个默认的ninodes数
2.虚拟磁盘布局
简单的EXT2文件系统布局
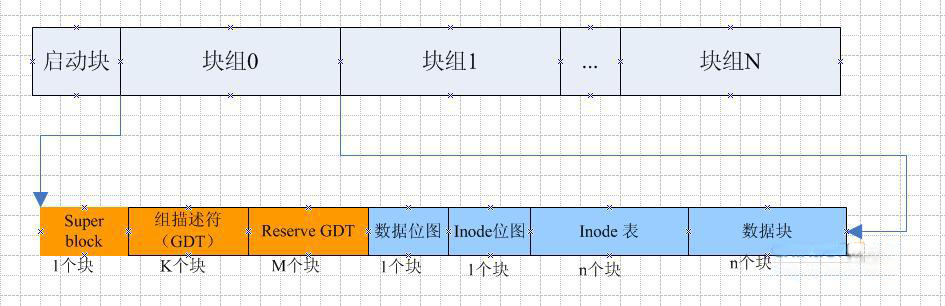
注意:inode表和数据块的个数不一定相等,这里只是示意
3.ext2文件有以下持点
- Blocks 与 inodes 在一开始格式化时 (format) 就已经固定了;
- 一个 partition 能够容纳的档案数与 inode 有关;
- 一般来说,每 4Kbytes 的硬盘空间分配一个 inode ;
- 一个 inode 的大小为 128 bytes;
- Block 为固定大小,目前支持 1024/2048/4096 bytes 等;
- Block 越大,则损耗的硬盘空间也越多。
- 关于单一档案:
- 若 block size=1024,最大容量为 16GB,若 block size=4096,容量最大为 2TB;
- 关于整个 partition :
- 若 block size=1024,则容量达 2TB,若 block size=4096,则容量达 32TB。
- 文件名最长达 255 字符,完整文件名长达 4096 字符。
4.超级块(Super Block)
描述整个分区的文件系统信息,如inode/block的大小、总量、使用量、剩余量,以及文件系统的格式与相关信息。超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。 为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的super block信息在这种情况下也能正常访问。所以一个文件系统的super block会在多个block group中进行备份,这些super block区域的数据保持一致。
超级块记录的信息有:
- block 与 inode 的总量;
- 未使用与已使用的 inode / block 数量;
- block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128 bytes);
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息;
- 一个valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1 。
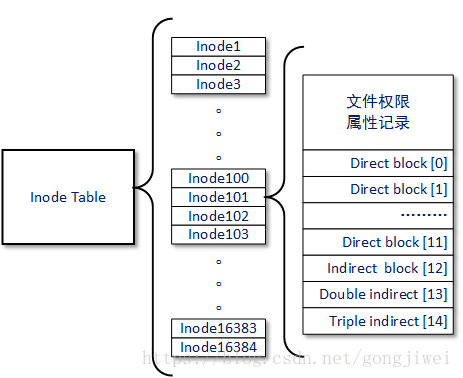
5.inode table (inode 表格)
inode 的内容在记录文件的属性以及该文件实际数据是放置在哪几号block内。基本上,inode 记录的文件数据至少有底下这些:
- 该文件的存取模式(read/write/excute);
- 该文件的拥有者与群组(owner/group);
- 该文件的容量;
- 该文件创建或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义文件特性的旗标(flag),如 SetUID...;
- 该文件真正内容的指向 (pointer);
inode的数量与大小也是在格式化时就已经固定了,除此之外inode还有些什么特点呢? - 每个 inode 大小均固定为 128 bytes;
- 每个文件都仅会占用一个 inode 而已;
- 承上,因此文件系统能够创建的文件数量与 inode 的数量有关;
- 系统读取文件时需要先找到 inode,并分析 inode 所记录的权限与用户是否符合,若符合才能够开始实际读取 block 的内容。
我们约略来分析一下 inode/block 与文件大小的关系好了。inode要记录的数据非常多,但偏偏又只有128bytes而已,而inode记录一个 block号码要花掉4byte ,假设我一个文件有 400MB 且每个block 为4K时,那么至少也要十万笔 block 号码的记录。inode 哪有这么多可记录的信息?为此我们的系统很聪明的将inode记录 block号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。
这样子 inode 能够指定多少个 block 呢?我们以较小的 1K block 来说明好了,可以指定的情况如下:
- 12 个直接指向:12*1K=12K
- 由于是直接指向,所以总共可记录12笔记录,因此总额大小为如上所示;
- 间接:256*1K=256K
- 每笔 block 号码的记录会花去 4bytes,因此 1K 的大小能够记录 256 笔记录,因此一个间接可以记录的文件大小如上;
- 双间接:2562561K=2562K
- 第一层block会指定256个第二层,每个第二层可以指定256个号码,因此总额大小如上;
- 三间接:256256256*1K=2563K
- 第一层block会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256个号码,因此总额大小如上;
- 总额:将直接、间接、双间接、三间接加总,得到 12+256+256256+256256*256(K)=16GB
此时我们知道当文件系统将block格式化为1K大小时,能够容纳的最大文件为16GB,比较一下文件系统限制表的结果可发现是一致的。但这个方法不能用在2K及4Kblock 大小的计算中,因为大于2K的block将会受到Ext2文件系统本身的限制,所以计算的结果会不太符合之故。
6.Filesystem Description(文件系统描述说明)
这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock,bitmap,inodemap,data block)分别介于哪一个block号码之间。这部份也能够用dumpe2fs来观察的。
7.block bitmap(区块对照表)
如果你想要新增文件时总会用到block,那你要使用哪个block来记录呢?当然是选择『空的 block』来记录新文件的数据啰。那如何知道哪个block是空的,就得要透过block bitmap的辅助了。从block bitmap当中可以知道哪些block是空的,因此我们的系统就能够很快速的找到可使用的空间来处置文件啰。
同样的,如果你删除某些文件时,那么那些文件原本占用的block号码就得要释放出来,此时在block bitmap当中相对应到该block号码的标志就得要修改成为『未使用中』。这就是 bitmap 的功能。
8.inode bitmap(inode 对照表)
这个其实与block bitmap是类似的功能,只是block bitmap记录的是使用与未使用的 block号码, 至于inode bitmap则是记录使用与未使用的inode号码。
了解了文件系统的概念之后,再来当然是观察这个文件系统啰!刚刚谈到的各部分数据都与 block 号码有关。每个区段与superblock的信息都可以使用dumpe2fs这个命令来查询的。查询的方法与实际的观察如下:
tzy@tzy-virtual-machine:~$ dumpe2fs [-bh] 装置文件名
选项与参数:
-b :列出保留为坏轨的部分。
-h :仅列出 superblock 的数据,不会列出其他的区段内容。
范例:找出我的根目录磁盘文件名,并观察文件系统的相关信息
tzy@tzy-virtual-machine:~$ df <==这个命令可以叫出目前挂载的装置
文件系统 1K-块 已用 可用 已用% 挂载点
udev 1967916 0 1967916 0% /dev
tmpfs 399508 1804 397704 1% /run
/dev/sda5 65274444 9592588 52336400 16% /
tmpfs 1997540 0 1997540 0% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
tmpfs 1997540 0 1997540 0% /sys/fs/cgroup
/dev/loop0 128 128 0 100% /snap/bare/5
/dev/loop1 101760 101760 0 100% /snap/core/11606
/dev/loop3 224256 224256 0 100% /snap/gnome-3-34-1804/72
/dev/loop2 101760 101760 0 100% /snap/core/11743
/dev/loop4 66816 66816 0 100% /snap/gtk-common-themes/1519
/dev/loop5 66688 66688 0 100% /snap/gtk-common-themes/1515
/dev/loop6 56832 56832 0 100% /snap/core18/2128
/dev/loop7 33152 33152 0 100% /snap/snapd/12883
/dev/loop8 52224 52224 0 100% /snap/snap-store/547
/dev/loop9 33152 33152 0 100% /snap/snapd/13170
/dev/loop10 4352 4352 0 100% /snap/tree/18
/dev/sda1 523248 4 523244 1% /boot/efi
tmpfs 399508 24 399484 1% /run/user/1000
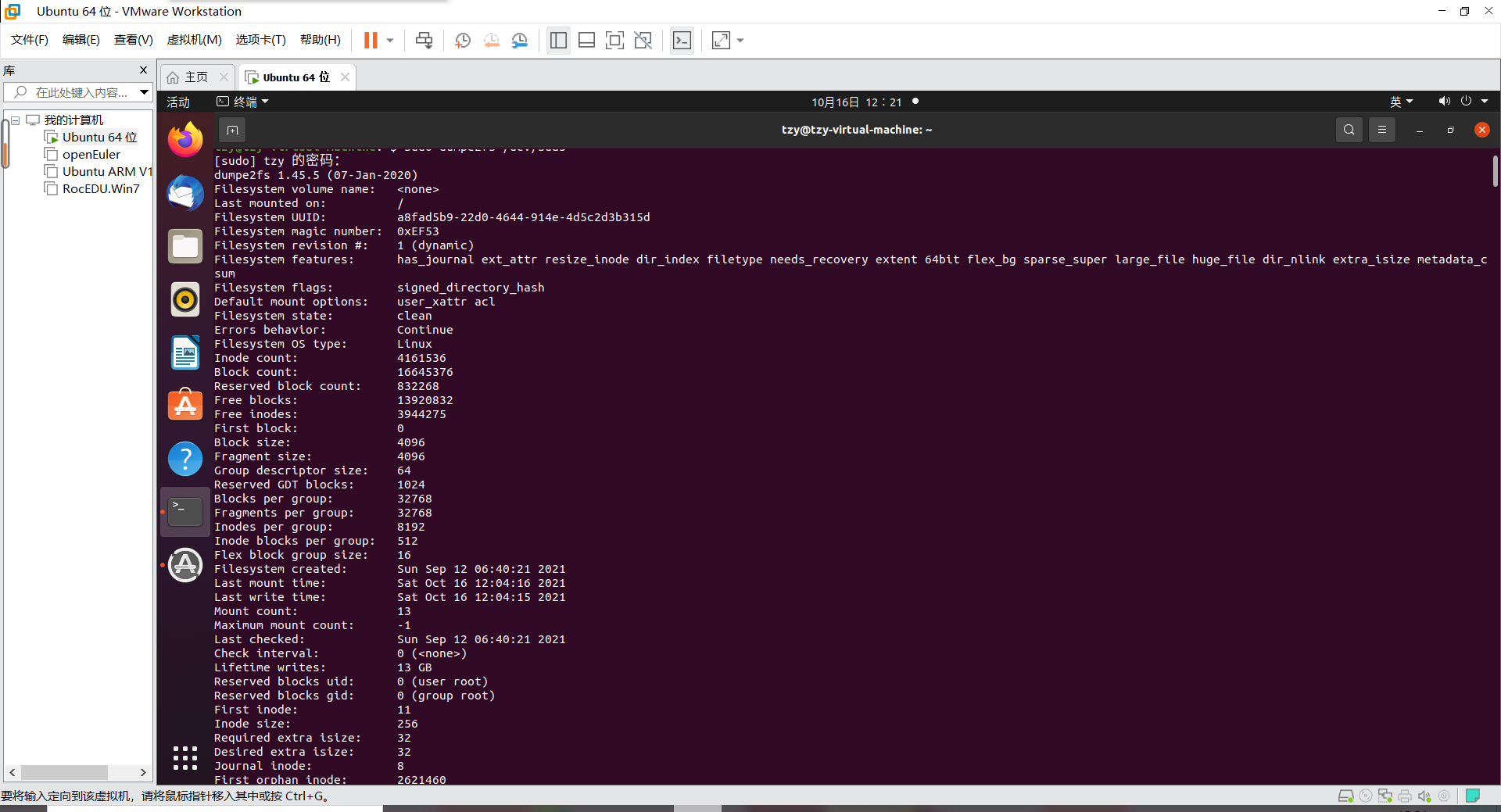
tzy@tzy-virtual-machine:~$ sudo dumpe2fs /dev/sda5
dumpe2fs 1.45.5 (07-Jan-2020)
Filesystem volume name: <none> <==这个是文件系统的名称(Label)
Last mounted on: /
Filesystem UUID: a8fad5b9-22d0-4644-914e-4d5c2d3b315d
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl <==默认挂载的参数
Filesystem state: clean <==这个文件系统是没问题的(clean)
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 4161536 <==inode的总数
Block count: 16645376 <==block的总数
Reserved block count: 832268
Free blocks: 13920832 <==还有多少个block可用
Free inodes: 3944275 <==还有多少个inode可用
First block: 0
Block size: 4096 <==每个block的大小
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 1024
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Sun Sep 12 06:40:21 2021
Last mount time: Sat Oct 16 12:04:16 2021
Last write time: Sat Oct 16 12:04:15 2021
Mount count: 13
Maximum mount count: -1
Last checked: Sun Sep 12 06:40:21 2021
Check interval: 0 (<none>)
Lifetime writes: 13 GB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256 <==每个inode的大小
Required extra isize: 32
Desired extra isize: 32
Journal inode: 8
First orphan inode: 2621460
Default directory hash: half_md4
Directory Hash Seed: a0b431ae-a295-433e-845e-fdef00931640
Journal backup: inode blocks
Checksum type: crc32c
Checksum: 0x089e29fe
Journal features: journal_incompat_revoke journal_64bit journal_checksum_v3
Journal size: 256M
Journal length: 65536
Journal sequence: 0x00005166
Journal start: 1
Journal checksum type: crc32c
Journal checksum: 0x5258563c
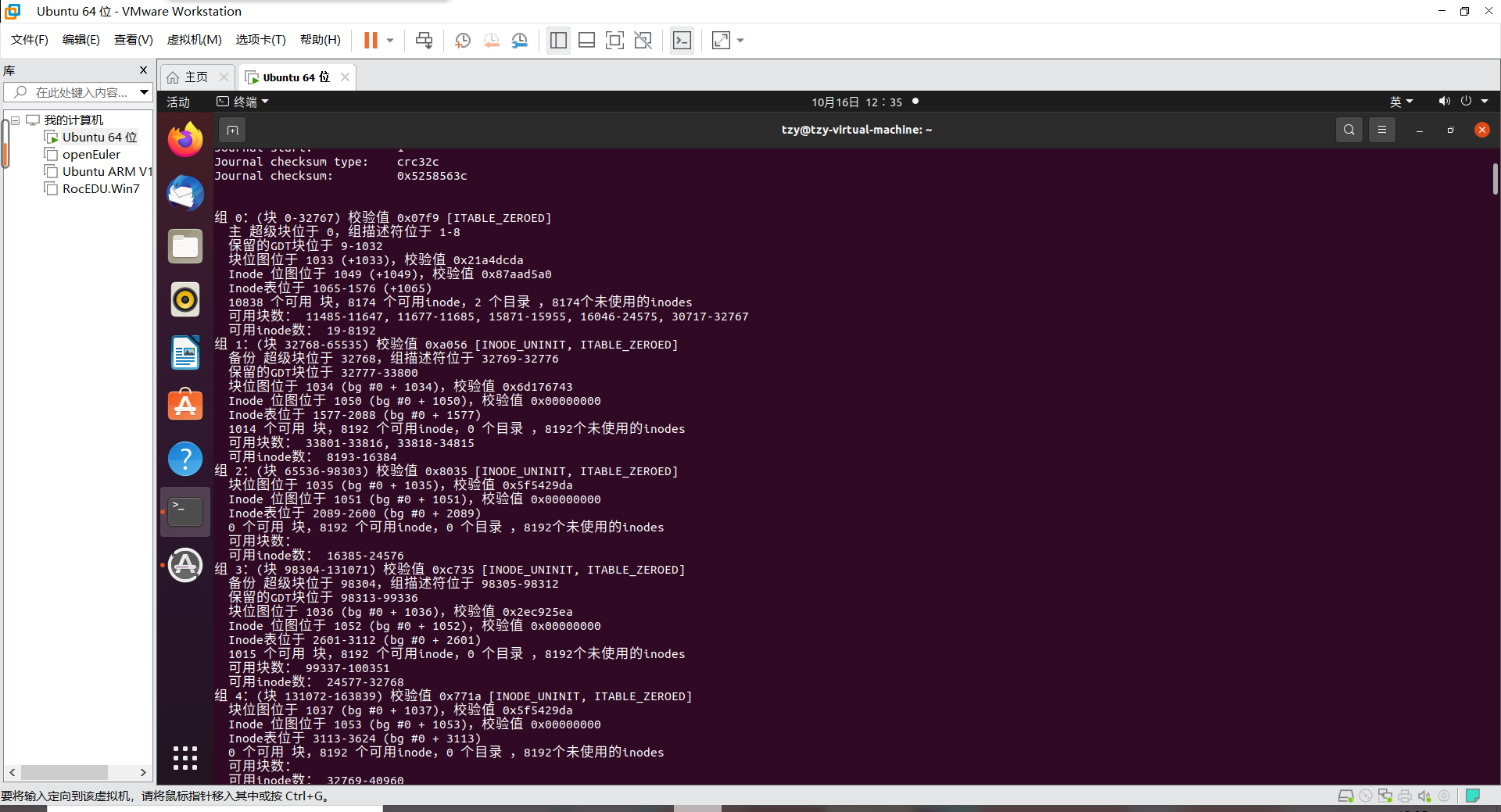
组 0:(块 0-32767) 校验值 0x07f9 [ITABLE_ZEROED]
主 超级块位于 0,组描述符位于 1-8 <==超级区块在0号block
保留的GDT块位于 9-1032
块位图位于 1033 (+1033),校验值 0x21a4dcda
Inode 位图位于 1049 (+1049),校验值 0x87aad5a0
Inode表位于 1065-1576 (+1065)
10838 个可用 块,8174 个可用inode,2 个目录 ,8174个未使用的inodes
可用块数: 11485-11647, 11677-11685, 15871-15955, 16046-24575, 30717-32767
可用inode数: 19-8192
组 1:(块 32768-65535) 校验值 0xa056 [INODE_UNINIT, ITABLE_ZEROED]
....(底下省略)....
# 由于数据量非常的庞大,因此将一些信息省略输出。
# 前半部在秀出supberblock的内容,包括标头名称(Label)以及inode/block的相关信息。
# 后面则是每个block group的个别信息了。可以看到各区段数据所在的号码。
# 也就是说,基本上所有的数据还是与 block 的号码有关。
至于block group的内容我们单纯看 Group0 信息好了。从上表中我们可以发现:如上所示,利用 dumpe2fs 可以查询到非常多的信息,不过依内容主要可以区分为上半部是superblock内容,下半部则是每个block group的信息了。从上面的表格中我们可以观察到这个/dev/sda5规划的 block为4K,第一个 block 号码为 0 号,且block group内的所有信息都以block的号码来表示的。 然后在superblock中还有谈到目前这个文件系统的可用 block与inode数量。
9.邮差算法
一个城市有M个街区,编号从0到M-1.每个街区有N座房子,编号从0到N-1.每座房子有一个唯一的街区地址,用(街区,房子)表示。已知某个街区地址BA=(街区,房子),怎么把他转换为线性地址LA。
Linear_address LA=N*block + house;
Block_address BA=(LA/N,LA%N);
10.ext2文件系统的实现
1.文件系统的结构
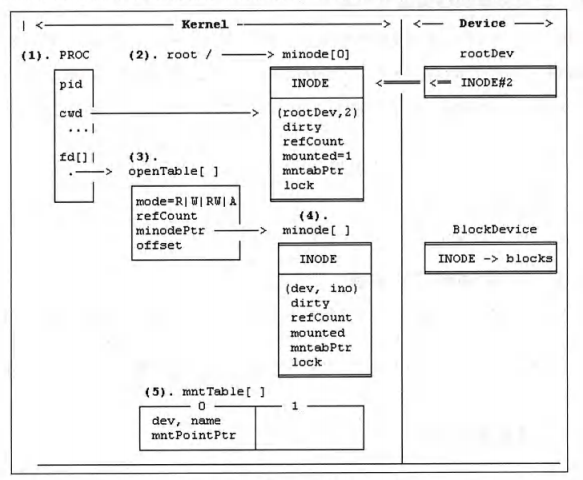
2.文件系统的级别
分为三个级别,第一级别实现了基本文件系统树,第二级别实现了文件内容读/写函数,第三级别实现了文件系统的挂载、卸载和文件保护。
2.ext2和目录树
每个文件(不管是一般文件还是目录文件)都会占用一个 inode , 且可依据文件内容的大小来分配多个 block 给该文件使用。而我们知道目录的内容在记录文件名, 一般文件才是实际记录数据内容的地方。那么目录与文件在 Ext2 文件系统当中是如何记录数据的呢?
1.目录
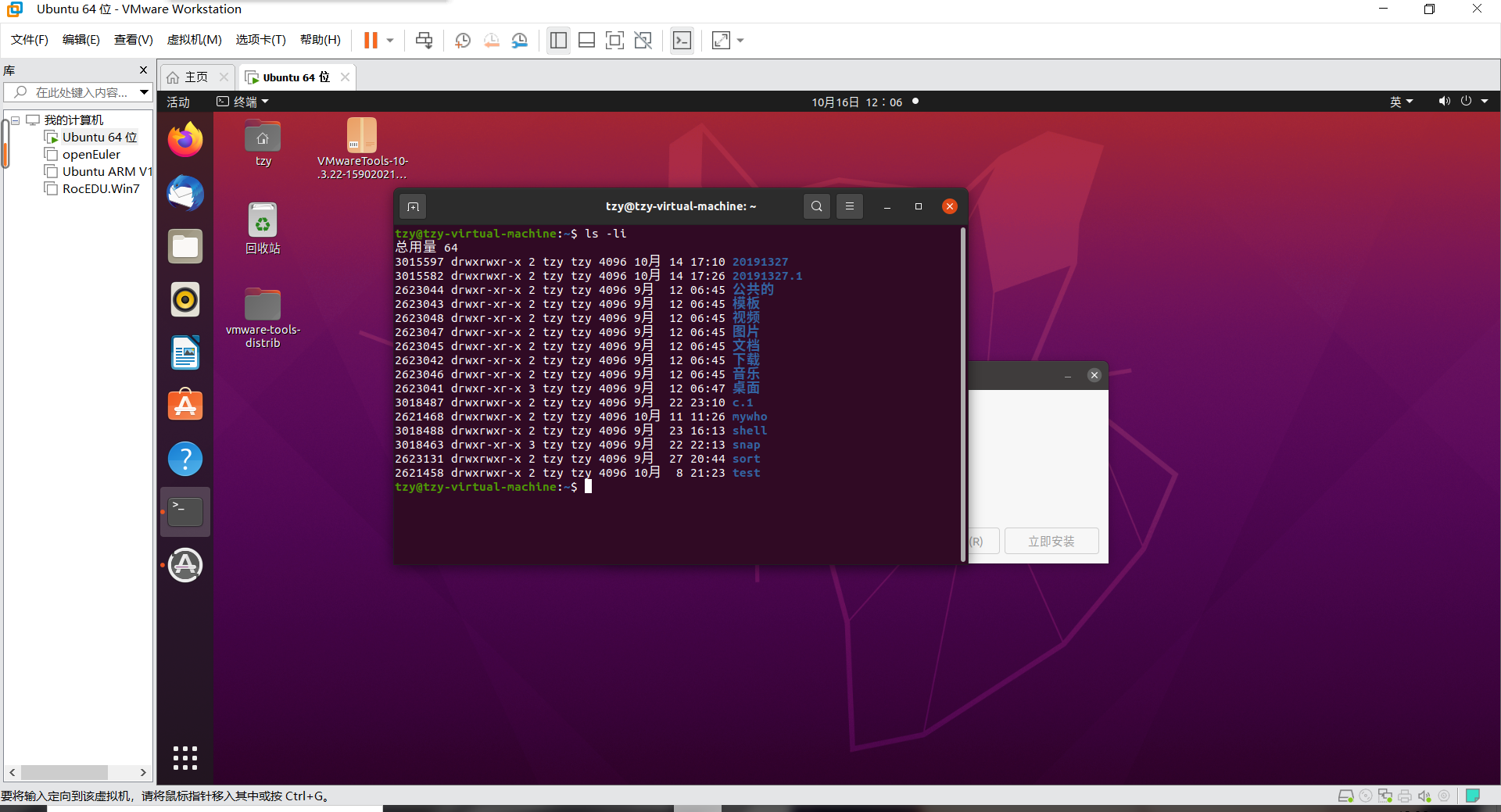
当我们在 Linux 下的 ext2 文件系统创建一个目录时, ext2 会分配一个 inode 与至少一块 block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码; 而 block 则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。如果想要实际观察 root 家目录内的文件所占用的 inode 号码时,可以使用ls -i这个选项来处理:
tzy@tzy-virtual-machine:~$ ls -li
总用量 64
3015597 drwxrwxr-x 2 tzy tzy 4096 10月 14 17:10 20191327
3015582 drwxrwxr-x 2 tzy tzy 4096 10月 14 17:26 20191327.1
2623044 drwxr-xr-x 2 tzy tzy 4096 9月 12 06:45 公共的
2623043 drwxr-xr-x 2 tzy tzy 4096 9月 12 06:45 模板
2623048 drwxr-xr-x 2 tzy tzy 4096 9月 12 06:45 视频
2623047 drwxr-xr-x 2 tzy tzy 4096 9月 12 06:45 图片
2623045 drwxr-xr-x 2 tzy tzy 4096 9月 12 06:45 文档
2623042 drwxr-xr-x 2 tzy tzy 4096 9月 12 06:45 下载
2623046 drwxr-xr-x 2 tzy tzy 4096 9月 12 06:45 音乐
2623041 drwxr-xr-x 3 tzy tzy 4096 9月 12 06:47 桌面
3018487 drwxrwxr-x 2 tzy tzy 4096 9月 22 23:10 c.1
2621468 drwxrwxr-x 2 tzy tzy 4096 10月 11 11:26 mywho
3018488 drwxrwxr-x 2 tzy tzy 4096 9月 23 16:13 shell
3018463 drwxr-xr-x 3 tzy tzy 4096 9月 22 22:13 snap
2623131 drwxrwxr-x 2 tzy tzy 4096 9月 27 20:44 sort
2621458 drwxrwxr-x 2 tzy tzy 4096 10月 8 21:23 test ##可以看到全是一个4k block
2.文件
当我们在Linux下的ext2创建一个一般文件时,ext2会分配一个inode与相对于该文件大小的block数量给该文件。例如:假设我的一个block为4 Kbytes,而我要创建一个100 KBytes的文件,那么linux将分配一个inode与25个block来储存该文件。但同时请注意,由于inode仅有12个直接指向,因此还要多一个block来作为区块号码的记录。
3.目录树读取
经过上面的说明很清楚的知道inode本身并不记录文件名,文件名的记录是在目录的block当中。 因此 我们才会提到『新增/删除/更名文件名与目录的w权限有关』的特色。那么因为文件名是记录在目录的block当中,因此当我们要读取某个文件时,就务必会经过目录的inode与block,然后才能够找到那个待读取文件的inode号码,最终才会读到正确的文件的block内的数据。
由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的 inode 号码(通常一个filesystem的最顶层inode号码会由2号开始),此时就能够得到根目录的inode内容,并依据该inode读取根目录的block内的文件名数据,再一层一层的往下读到正确的档名。
举例来说,如果我想要读取 /etc/passwd 这个文件时,系统是如何读取的呢?
使用ll -di / /etc /etc/passwd

/ 的 inode:在系统上面与 /etc/passwd 有关的目录与文件数据如上表所示,该文件的读取流程为(假设读取者身份为 vbird 这个一般身份使用者):
- 透过挂载点的信息找到 /dev/sda5的inode号码为2的根目录inode,且inode规范的权限让我们可以读取该block的内容(有r与x) ;
- / 的 block:
- 经过上个步骤取得block的号码,并找到该内容有 etc/ 目录的inode号码(2883585);
- etc/ 的inode:
- 读取2883585号inode得知vbird具有r与x的权限,因此可以读取etc/ 的block内容;
- etc/ 的 block:
- 经过上个步骤取得block号码,并找到该内容有passwd文件的inode号码 (2883698);
- passwd的inode:
- 读取2883698号inode得知vbird具有r的权限,因此可以读取passwd的block内容;
- passwd的block:
- 最后将该block内容的数据读出来。
3.挂载点的意义 (mount point)
每个 filesystem 都有独立的inode/block/superblock等信息,这个文件系统要能够链接到目录树才能被我们使用。将文件系统与目录树结合的动作我们称为『挂载』。关于挂载的一些特性我们在稍微提过,重点是:挂载点一定是目录,该目录为进入该文件系统的入口。 因此并不是你有任何文件系统都能使用,必须要『挂载』到目录树的某个目录后,才能够使用该文件系统的。
举例来说,应该会有三个挂载点,分别是 /, /boot, /home 三个。 那如果观察这三个目录的inode号码时,我们可以发现如下的情况:
使用ls -lid / /boot /home

上面的信息中由于挂载点均为 / ,因此三个文件 (/, /., /..) 均在同一个filesystem内,而这三个文件的inode号码均为 2 号,因此这三个档名都指向同一个inode号码,当然这三个文件的内容也就完全一模一样了。也就是说,根目录的上一级 (/..) 就是他自己
由于filesystem最顶层的目录之inode一般为2号,因此可以发现 /, /boot, /home为三个不同的filesystem。(因为每一行的文件属性并不相同,且三个目录的挂载点也均不相同之故。)
根目录下的 . 与 .. 是相同的东西, 因为权限是一模一样的如果使用文件系统的观点来看,同一个filesystem的某个inode只会对应到一个文件内容而已(因为一个文件占用一个inode之故),因此我们可以透过判断inode号码来确认不同文件名是否为相同的文件,所以可以这样看:
tzy@tzy-virtual-machine:~$ ls -ild / /. /..
2 drwxr-xr-x 20 root root 4096 9月 12 06:42 /
2 drwxr-xr-x 20 root root 4096 9月 12 06:42 /.
2 drwxr-xr-x 20 root root 4096 9月 12 06:42 /..

问题:但在测试过程中发现系统执行fsck命令时失败,并报告0x20错误。
- 解决方案:
- (1)fdisk –l找到swap分区/dev/sda2
- (2)swapon /dev/sda2,使能swap分区
- (3)对需要进行fsck的分区手工执行fsck动作。
- (4)fsck完成后,编辑文件/etc/sysconfig/dump ,更改为
## Type: list(0,1)
## Default: 1
# DUMP_ACTIVE indicates whether the dump process is active or not. If this
# variable is 0, the dump kernel process will not be activated.
#
DUMP_ACTIVE="0"
(5)重启系统