库定义
创建数据库
create database school;
create schema school;
show charset; #查看支持的字符集
show collation; #查看支持的排序规则
CREATE DATABASE test CHARSET utf8; #创建数据库标准写法
create database test charset utf8mb4 collate utf8mb4_bin; #utf8mb4_bin可以存储中文拼音
参考资料:排序跟字符集的关系
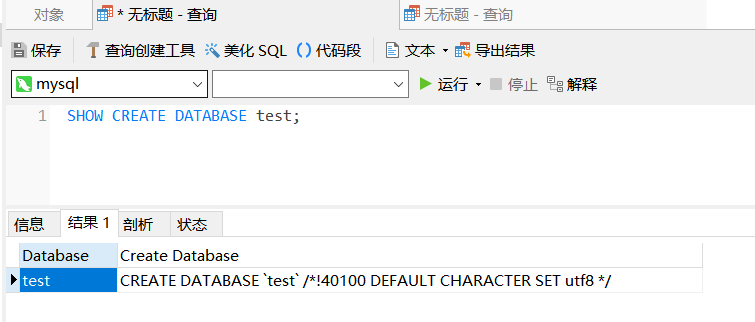
查看创建数据库的语句
建库规范:
1.库名不能有大写字母
2.建库要加字符集
3.库名不能有数字开头
4. 库名要和业务相关
删库(谨慎)
mysql> drop database test;
修改库
注意:修改字符集,修改后的字符集一定是原字符集的严格超集(即包含原字符集的集合)
mysql> SHOW CREATE DATABASE school;
mysql> ALTER DATABASE school CHARSET utf8;
参考资料:修改数据库名
查询数据库
mysql> show databases;
#查看数据库创建的语句
mysql> show create database test;
表定义
语法
create table stu(
列1 属性(数据类型、约束、其他属性),
列2 属性,
列3 属性
)
案例
USE school;
CREATE TABLE stu(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号', #自增长列
sname VARCHAR(255) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
sgender ENUM('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别' , #enum枚举,只能选择m,f,n其中一个,默认n
sfz CHAR(18) NOT NULL UNIQUE COMMENT '身份证',
intime TIMESTAMP NOT NULL DEFAULT NOW() COMMENT '入学时间'
) ENGINE=INNODB CHARSET=utf8 COMMENT '学生表';
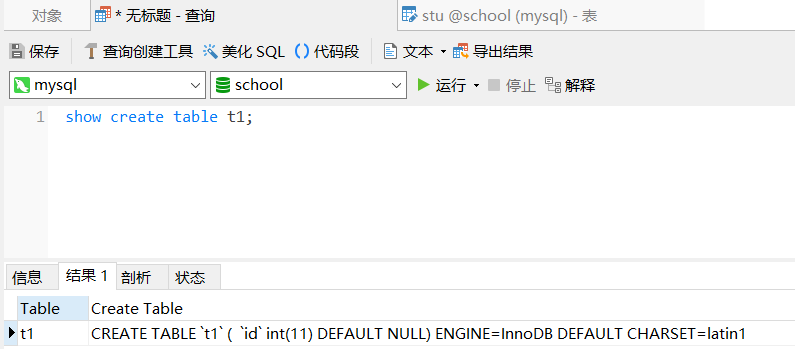
可以看出不指定字符集默认为latin1
列属性说明
primary key:主键约束,非空且唯一
auto_increment: 自增长的列
not null:不允许空值
unique key:唯一键约束,不允许重复值
default:默认值,配合not null使用
unsigned: 无符号,一般配合数字列使用,非负数
unique:表示不能重复
comment: 注释
建表规范:
- 表名小写字母,不能是数字开头
- 主键列最好是数字列,自增长
- 表需要设置字符集和存储引擎
- 表名和业务有关,不能是保留字符
- 选择合适的数据类型及长度
- 每个列都要有注释
- 每个列设置为非空,无法保证非空,用0来填充。
删除表
drop table stu;
查询建表信息
use school; #先选择数据库
show tables;
show create table stu; #查询建表语句
desc stu; #显示表结构
create table test like stu; #创建一个表结构一样的表
修改列
1、现在school数据库stu表如下,需求在sname后加微信列
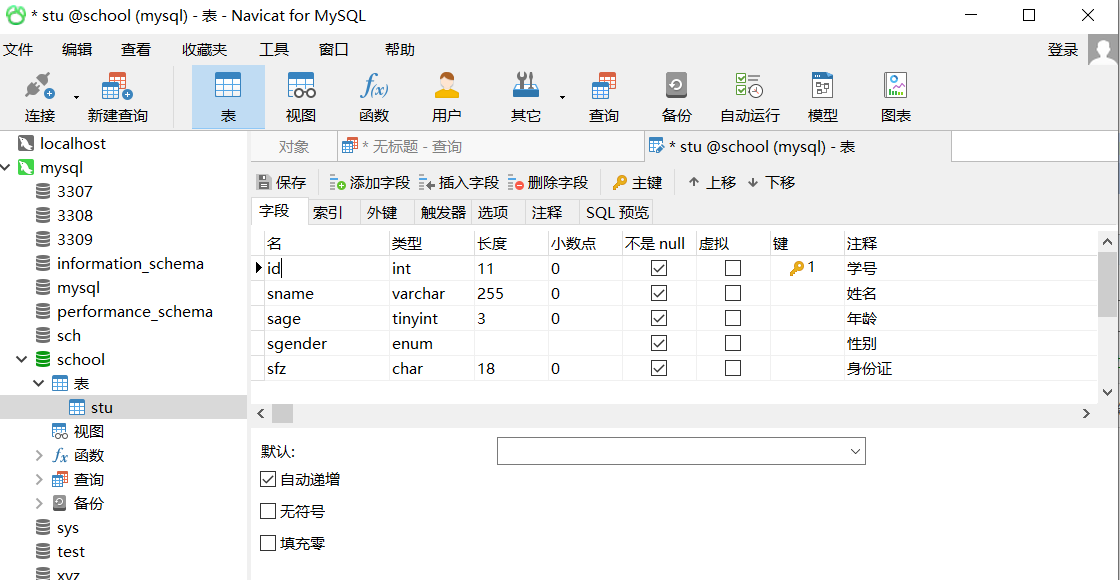
执行语句
ALTER TABLE stu ADD wechat VARCHAR(64) NOT NULL UNIQUE COMMENT '微信号' AFTER sname;
查看结果
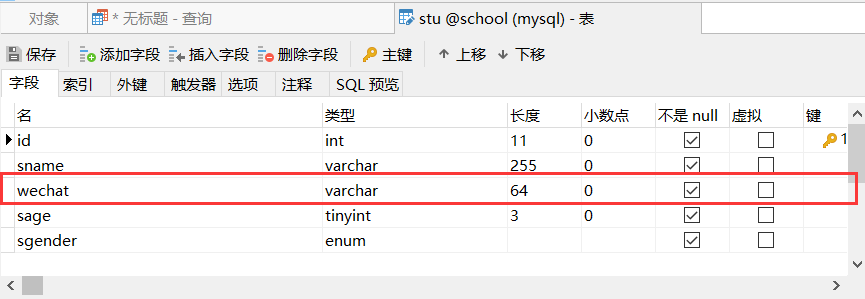
2、在stu表中增加qq列,默认会添加到最后
ALTER TABLE stu ADD qq VARCHAR(20) NOT NULL UNIQUE COMMENT 'qq号';
DESC stu; #显示stu表结构
3、在id列前增加num列
执行语句
ALTER TABLE stu ADD num INT NOT NULL UNIQUE COMMENT '身份证' FIRST;
注意添加跟删除都会锁表,如果数据量大的表可能会中断业务访问,所以需要提前做好相关准备。
4、删除刚才添加的列(谨慎)
ALTER TABLE stu DROP num;
ALTER TABLE stu DROP qq;
ALTER TABLE stu DROP wechat;
DESC stu; #显示表结构
5、修改sname数据类型属性
ALTER TABLE stu MODIFY sname VARCHAR(128) NOT NULL ;
原来sname列属性为
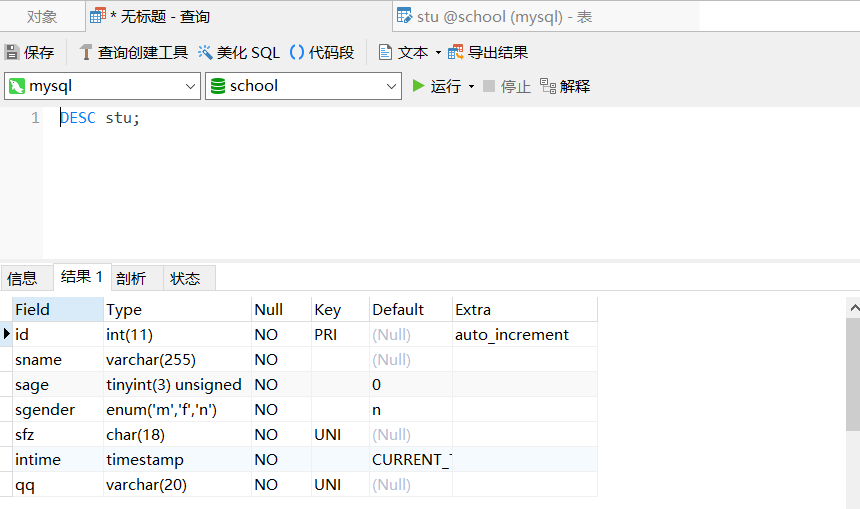
修改后

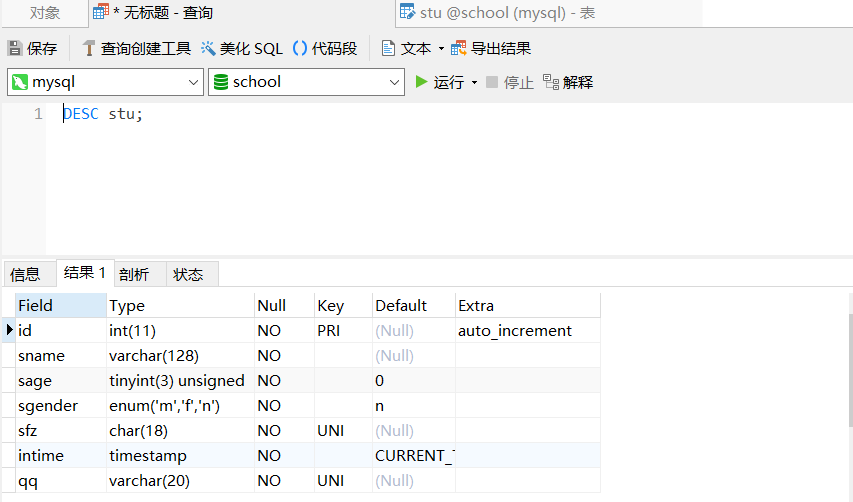
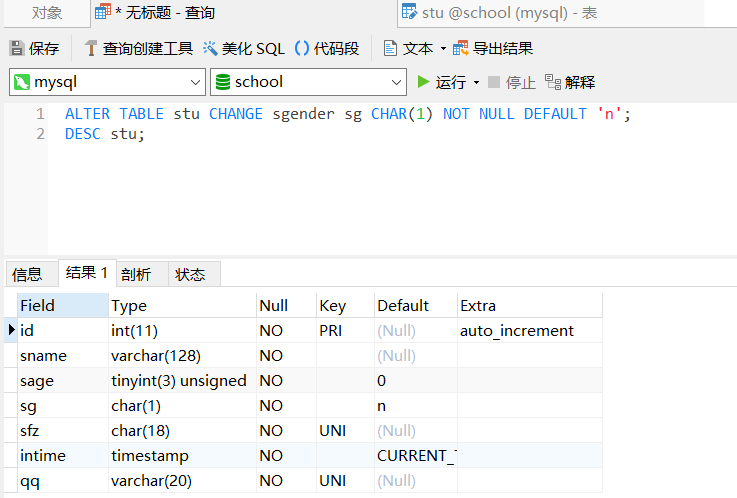
6、将列名sgender改为sg,数据类型改为CHAR类型
ALTER TABLE stu CHANGE sgender sg CHAR(1) NOT NULL DEFAULT 'n' ;
DESC stu;
原来sgender列属性为
修改后
对表数据行进行增删改查
1、使用insert插入数据行
#最标准写法
INSERT INTO stu(id,sname,sage,sg,sfz,intime)
VALUES (1,'zs',18,'m','123456',NOW());
SELECT * FROM stu;
#省事的写法
INSERT INTO stu
VALUES (2,'ls',18,'m','1234567',NOW());
#针对性的录入数据
INSERT INTO stu(sname,sfz)
VALUES ('w5','34445788');
#同时录入多行数据
INSERT INTO stu(sname,sfz)
VALUES
('w55','3444578d8'),
('m6','1212313'),
('aa','123213123123');
SELECT * FROM stu;
2、使用update修改数据行
DESC stu;
SELECT * FROM stu;
UPDATE stu SET sname='zhao4' WHERE id=2;
注意:update语句必须要加where。
3、删除某行数据(谨慎)
DELETE FROM stu WHERE id=3;
全表删除
DELETE FROM stu;
truncate table stu;
区别:
delete: DML操作, 逐行进行删除,速度慢.
truncate: DDL操作,对与表段中的数据页进行清空,速度快.
保守删除(建议)
也叫伪删除,用update更新某列,保证业务查不到即可。
优点:可以不删除数据,数据是最重要的东西,可能跟其他表相关联。
缺点:where条件不是state还是可以查到
#添加状态列
ALTER TABLE stu ADD state TINYINT NOT NULL DEFAULT 1 ;
SELECT * FROM stu;
#UPDATE 替代 DELETE
UPDATE stu SET state=0 WHERE id=6;
#业务语句查询
SELECT * FROM stu WHERE state=1;
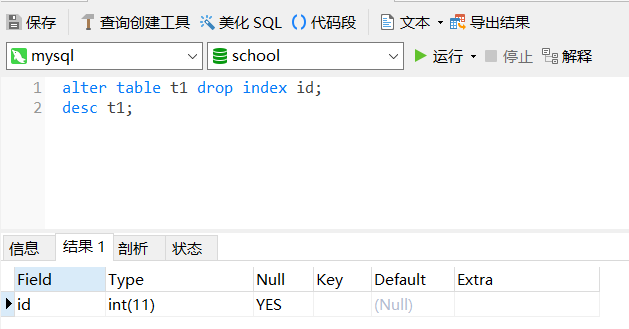
4、回收列属性
create table t1(id int unique);
desc t1;
alter table t1 drop index id;
回收前

回收后
5、多个列可以定义为主键,但建议最多2个列
定义id为主键列
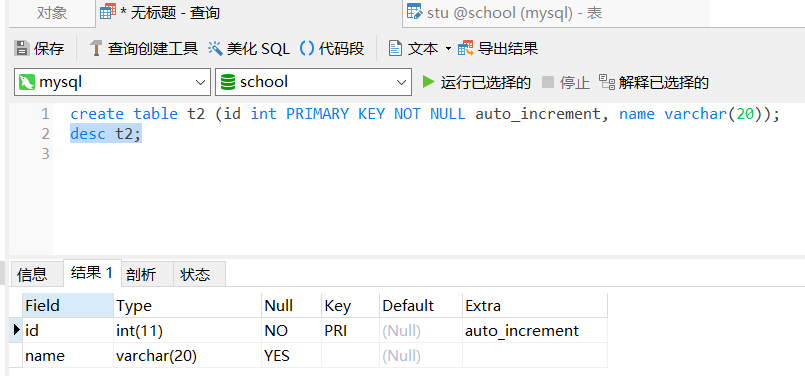
同时定义id跟name为主键列

学习来自:郭老师博客,老男孩深标DBA课程 第三章