我负责的主要部分是文本的分类,运用最基础的朴素贝叶斯分类算法进行处理数据。
一、数据源
采用22673篇文档的数据集,其中的0.7作为训练集,其中的0.3当做测试集来计算roc,测试集一共有6802篇文章的题目和摘要。
二、数据预处理
原始数据是一个TXT中有很多篇文章,包括他的各种属性,我们只把需要的题目和摘要提取出来。
1、分文档:
把一个TXT的多篇文章,每一篇分到一个TXT里面,让每篇文章的唯一标识号作为文章的名称。

import os
def open_text():
#遍历存放原始文件的目录,获取文件内容
for dirname in os.listdir(r'C:UserswxxDesktop rain_split2 rain_split2'):
for text_name in os.listdir(r'C:UserswxxDesktop rain_split2 rain_split2{}'.format(dirname)):
with open(r'C:UserswxxDesktop rain_split2 rain_split2{}{}'.format(dirname,text_name),'r') as f:
clean_text(f.readlines(),dirname,text_name)
def clean_text(contents,dirname,text_name):
#处理文件内容
if not os.path.exists(r'C:UserswxxDesktopclean_text{}'.format(dirname)):
#创建新的目录来存放处理好的文件
os.mkdir(r'C:UserswxxDesktopclean_text{}'.format(dirname))
try:
with open(r'C:UserswxxDesktopclean_text{}{}'.format(dirname,text_name),'w') as f :
i = 0#内容list下标
while i < len(contents):
if i == len(contents)-1:
#如果是最后一行
f.write(contents[i])
i += 1
continue
if not contents[i].startswith(' ') and not contents[i+1].startswith(' '):
#当前行和下一行不是一类内容
f.write(contents[i])
i += 1
continue
if not contents[i].startswith(' ') and contents[i+1].startswith(' ') :
#当前行和下一行是一类内容
i += 1
str = []
str.append(contents[i-1].rstrip('
'))
while i < len(contents) and contents[i].startswith(' '):
#合并到一行
str.append(contents[i].rstrip('
'))
i += 1
str.append('
')
f.write(''.join(str))
print('{} write successfully'.format(text_name))
except Exception :
print('{} has wrong'.format(text_name))
with open(r'C:UserswxxDesktopclean_texterror.txt','a') as fe:
#记录下出错的文件
fe.write('{} has wrong'.format(text_name))
open_text()
2、提取题目和摘要:

# -*- coding: UTF-8 -*-
from os import path
import os
import re
d = path.dirname(__file__)
p = r"C:Users yy1Desktopgongzuoclean_textCarbon Based" #文件夹目录
files= os.listdir(p) #得到文件夹下的所有文件名称
fd = open('./title and abstract1.txt','a')
for file in files: #遍历文件夹
if not os.path.isdir(file): #判断是否是文件夹,不是文件夹才打开
f = open(p+"/"+file); #打开文件
iter_f = iter(f); #创建迭代器
str = ""
for line in iter_f: #遍历文件,一行行遍历,读取文本
index = line.find("AB - ")
index1 = line.find("TI - ")
if 'TI - ' in line:
index = index + len("TI - ")
s2 = line[index:index+200]
fd.write(s2)
fd.flush()
if 'AB - ' in line:
index = index + len("AB - ")
s1 = line[index:index+2000]
fd.write(s1+'
')
fd.write(" "+'
')
fd.flush()
三、数据处理
1、tf-idf算法提取关键词
第一步,计算词频:

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

第二步,计算逆文档频率:
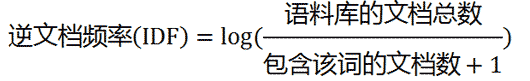
第三步,计算TF-IDF:
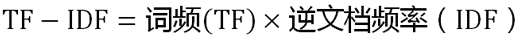
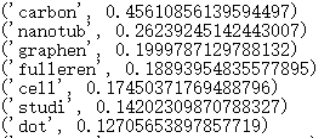
结果:
import nltk
import os
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer("english")
# nltk.download()
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
# stopwords = nltk.corpus.stopwords.words('english')
with open(r'C:UserswxxDesktop全文stopwords.txt','r') as f:
stopwords = f.readlines()
clean_stopwords = []
for stopword in stopwords:
clean_stopwords.append(stopword.strip())
# print(clean_stopwords)
# tags = ['FW','NN','NNS','NNP','NNPS']
def open_text():
corpus = []
for text_name in os.listdir(r'C:UserswxxDesktop全文全文
um'):
with open(r'C:UserswxxDesktop全文全文
um{}'.format(text_name),'r') as f:
words_first = []
sens = nltk.sent_tokenize(f.read())
for sen in sens:
for word in nltk.word_tokenize(sen):
words_first.append(stemmer.stem(word.strip()))
words_second = [stemmer.stem(w) for w in words_first if w not in clean_stopwords]
# words_third = []
# for word_tag in nltk.pos_tag(words_second):
# if word_tagwords_second[1] in tags:
# words_third.append(stemmer.stem(word_tag[0]))
# test = dict(nltk.FreqDist(words_third))
clean_content = ' '.join(words_second)
corpus.append(clean_content)
return corpus
def tfidf(corpus):
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
for i in range(len(weight)):
wordlist = []
valuelist = []
for j in range(len(word)):
wordlist.append(word[j])
valuelist.append(weight[i][j])
wordandvalue = dict(zip(wordlist, valuelist))
dd = sorted(wordandvalue.items(), key=lambda d: d[1], reverse=True)
for i in range(5): # 显示前五个
print(dd[i])
print('--------------------')
tfidf(open_text())
2、朴素贝叶斯算法进行分类
第一阶段:训练数据生成训练样本集:TF-IDF
第二阶段;对每个类别计算 P(yi)(先验概率)
第三阶段:对每个特征属性计算所有划分的条件概率P(x/yi)
第四阶段:对每个类别计算P(x/yi)P(yi)
第五阶段:以 P(x/yi)P(yi)最大项作为 的所属类别
#encoding:utf-8
import pandas as pd
import numpy as np
import os
def read_data( path ,classes):
with open(path,'r') as file:
lines = file.readlines()
finallines = []
pertxt = ""
i = 0
for line in lines:
if line == '
':
i += 1
else:
i = 0
pertxt += line
if i >= 2:
finallines.append(pertxt)
pertxt = ""
i = 0
txts = pd.DataFrame({"content": finallines})
txts['classes'] = classes
txts = txts.dropna()
return txts
def cleanFormat_test(data):
txts = data
stop_txt = pd.read_table(r'C:UsersPCDesktop itle and abstractstopwords.txt', sep='
', names=['words'])
stop_txt = stop_txt.dropna()
english_stopwords =stop_txt.words.values.tolist()
english_punctuations = [',', '.', ':', ';', '?', '(', ')', '<', '>', '{', '}','[', ']', '!', '@', '#', '%', '$', '*', '/','0','1','2','3','4','5','6','7','8','9',"
"]
finallines = []
for pertxt in txts:
no_punctual=""
for w in pertxt:
if w not in english_punctuations:
no_punctual += w
else: no_punctual += " "
words=no_punctual.replace(" "," ").split()
clean_pertxt = ""
for word in words:
if word not in english_stopwords:
if(len(word)>4):
clean_pertxt += word+ " "
finallines.append(clean_pertxt)
return finallines
tr1=read_data(r'C:UsersPCDesktop itle and abstractTest SetCarbon Based.txt','Carbon Based')
tr2=read_data(r'C:UsersPCDesktop itle and abstractTest Setmetallic.txt','metallic')
tr3=read_data(r'C:UsersPCDesktop itle and abstractTest Set
ano ceramic.txt','nano ceramic')
tr4=read_data(r'C:UsersPCDesktop itle and abstractTest SetOrganic Inorganic.txt','Organic Inorganic')
tr5=read_data(r'C:UsersPCDesktop itle and abstractTest SetPolymer.txt','Polymer')
tr6=read_data(r'C:UsersPCDesktop itle and abstractTest SetSemi-Metallic.txt','Semi-Metallic')
df_data = pd.concat([tr1,tr2,tr3,tr4,tr5,tr6])
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y = train_test_split(df_data['content'].values,df_data['classes'].values,test_size=0.3,random_state=10)
words=df_data.content.values.tolist()
classes=df_data.classes.values.tolist()
orign_content_list = test_x
words=cleanFormat_test(words)
train_x=cleanFormat_test(train_x)
test_x=cleanFormat_test(test_x)
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(analyzer='word', lowercase = False)
vec.fit(train_x)
#训练集数据用来拟合分类器
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(train_x),train_y)
print("贝叶斯分类器精度:")
print(classifier.score(vec.transform(words), classes))
四、数据可视化
词云制作:调用python中 matplotlib WordCloud。

# _*_ coding:utf-8 _*_
#!/usr/bin/python
# -*- coding: <encoding name> -*-
import sys
reload(sys)
sys.setdefaultencoding('gbk')
from os import path
import os
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 获取当前文件路径
# __file__ 为当前文件, 在ide中运行此行会报错,可改为
# d = path.dirname('.')
d = path.dirname(__file__)
p = r"C:Users yy1Desktopgongzuowx00-17wx2016" #文件夹目录
files= os.listdir(p) #得到文件夹下的所有文件名称
s = []
for file in files: #遍历文件夹
if not os.path.isdir(file): #判断是否是文件夹,不是文件夹才打开
f = open(p+"/"+file); #打开文件
iter_f = iter(f); #创建迭代器
str = " "
for line in iter_f: #遍历文件,一行行遍历,读取文本
str = str + line
s.append(str) #每个文件的文本存到list中
# 设置背景图片,也就是掩膜图像,在非白色部分我们的统计好的词频会显示在这里
alice_coloring = imread(path.join(d, "16.jpg"))
stopwords = set(STOPWORDS)
stopwords.add("Journal")
stopwords.add("Article")
stopwords.add("using")
stopwords.add("used")
stopwords.add("based")
stopwords.add("also")
stopwords.add("However")
wc = WordCloud(background_color="black", # 背景颜色<br>#max_words=2000,# 词云显示的最大词数
mask=alice_coloring, # 设置背景图片
stopwords=stopwords,
max_font_size=300, # 字体最大值
random_state=50)
# 上述函数设计了词云格式
# 生成词云, 可以用generate输入全部文本(中文不好分词),也可以我们计算好词频后使用generate_from_frequencies函数
wc.generate(' '.join(s))
# 文本词频统计函数,本函数自动统计词的个数,以字典形式内部存储,在显示的时候词频大的,字体也大
# 从背景图片生成颜色值
image_colors = ImageColorGenerator(alice_coloring)
# 以下代码显示图片
plt.figure()
# recolor wordcloud and show
# we could also give color_func=image_colors directly in the constructor
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
plt.show()
五、分类结果评估
(1)数据集:
采用2万多篇文档的数据集中的0.3测试集来计算roc,一共有6802篇文章的题目和摘要。
去标点符号:english_punctuations = [',', '.', ':', ';', '?', '(', ')', '<', '>', '{', '}','[', ']', '!', '@', '#', '%', '$', '*', '/'," "]
去停用词:附件有个stopwords.txt 没有转换大小写。
(2)精确度、召回率、F值:
混淆矩阵(Confusion Matrix):

真正例(True Positive;TP):将一个正例正确判断成一个正例
伪正例(False Positive;FP):将一个反例错误判断为一个正例
真反例(True Negtive;TN):将一个反例正确判断为一个反例
伪反例(False Negtive;FN):将一个正例错误判断为一个反例
Ⅰ.精确率(Precision)
预测为正例的样本中,真正为正例的比率.

精确率本质来说是对于预测结果来说的.表示对于结果来说,我对了多少。
Ⅱ.召回率(Recall)
预测为正例的真实正例(TP)占所有真实正例的比例.
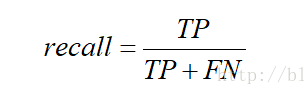
召回率是对于原来的样本而言的.表示在原来的样本中,我预测中了其中的多少。
Ⅳ.F值
表示精确率和召回率的调和均值


微精确度为多个混淆矩阵的精确率的平均
微精确度:0.758751607
微召回率为多个混淆矩阵的召回率的平均
微召回率:0.763060747
微F1: 0.76090008
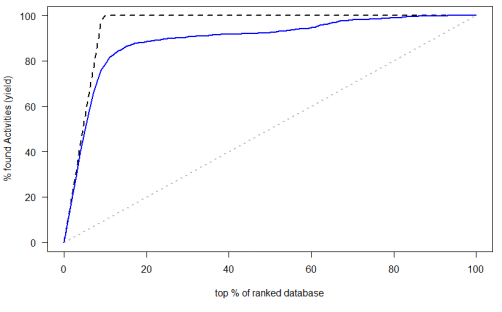
(3)AUC和ROC曲线
Ⅰ.FPR伪正类率(False Positive Rate,FPR)------横坐标
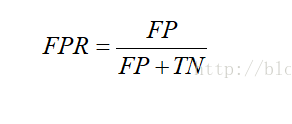
Ⅱ.TPR真正类率(Ture Positive Rate,TPR)-------纵坐标
预测为正且实际为正的样本占所有正样本的比例.你会发现,这个不就是召回率
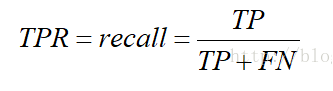
ROC就是对于一个分类器,给定一些阈值,每一个阈值都可以得到一组(FPR,TPR),以FPR作为横坐标,TPR作为纵坐标
AUC:为ROC曲线下面积
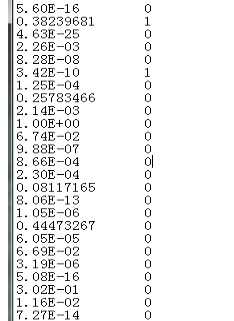
第一列是每一篇文献属于这一类的概率
第二列是真实的类别 如果属于这类就为1,不属于就为0
放入Excel中,然后再使用R语言计算AUC,可以直接画出ROC曲线。
第一步:首先加载这个选中的程序包

第二步,导入文件:

第三步:画图,FALSE和TURE是做升序还是降序

第四步:前百分之多少的AUC
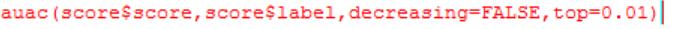
(其中top=0.01可以不设置)
第五步:算AUC

得到的结果:
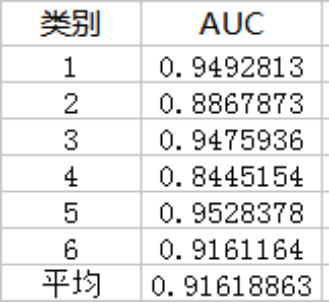
第一类:
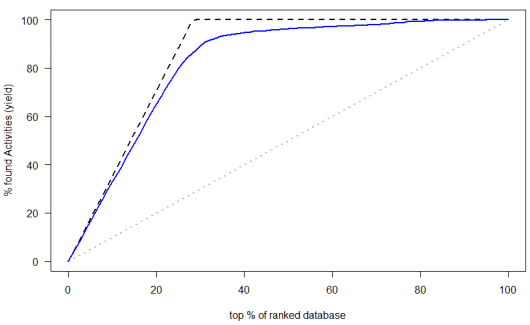
第二类:
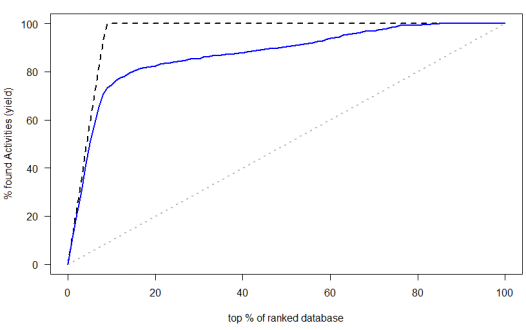
第三类:
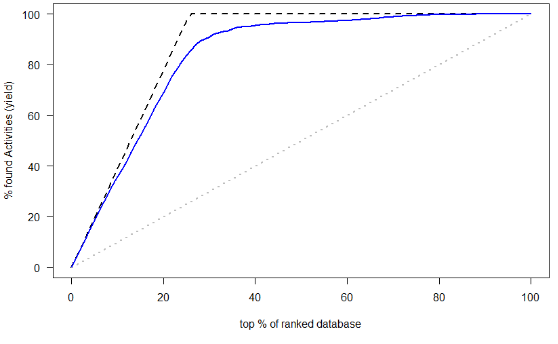
第四类:
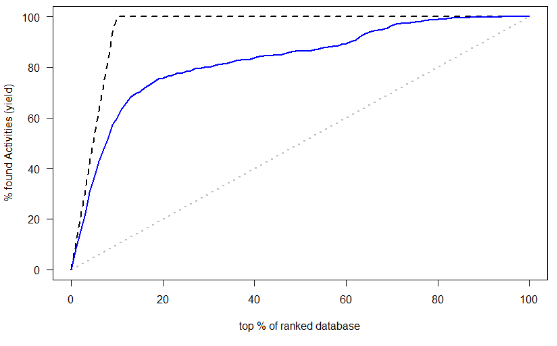
第五类:
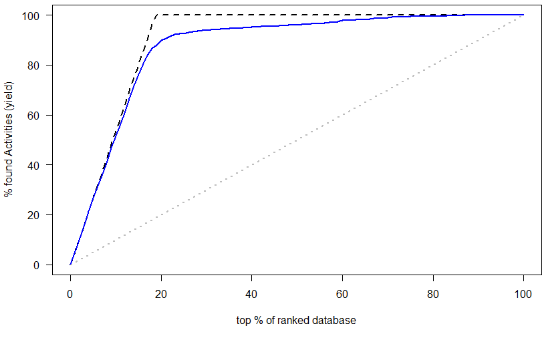
第六类: