背景
公司业务由数以百计的分布式服务沟通,每一个请求路由过来后,会经过多个业务系统并留下足迹,并产生对各种缓存或者DB的访问,但是这些分散的数据对于问题排查,或者流程优化比较有限。对于一个跨进程的场景,汇总收集并分析海量日志就显得尤为重要。在这种架构下,跨进程的业务流会经过很多个微服务的处理和传递,我们难免会遇到这样的问题:
- 一次请求的流量从哪个服务而来? 最终落到了哪个服务中去?
- 为什么这个请求这么慢? 到底哪个环节出了问题?
- 这个操作需要依赖哪些东西? 是数据库还是消息队列? Redis挂了,哪些业务受影响?
对于这个问题,业内已经有了一些实践和解决方案,通过调用链的方式,把一次请求调用过程完整的串联起来,这样就实现了对请求条用路径的监控。在业界,Twitter的Zipkin和淘宝的鹰眼就是类似的系统,它们都起源于Google Dapper论文,就像历史上Hadoop起源于Google Map/Reduce论文,Hbase起源于Google BigTable论文一样
设计目标
- 低消耗性:跟踪系统对业务系统的影响应该做到足够小。在一些高度优化过的服务,即使一点点损耗也容易察觉到,而且有可能迫使在线负责的部署团队不得不将跟踪系统关停
- 低侵入性:作为非业务组件,应当尽可能少侵入或者无侵入业务系统,对于使用方透明,减少开发人员的负担
- 时效性:从数据的收集产生,到数据计算处理,再到最终展现,都要求尽可能快
- 决策支持:这些数据是否能在决策支持层面发挥作用,特别是从DevOps的角度
- 数据可视化:做到不用看日志通过可视化进行筛选
实现功能
- 故障快速定位
- 调用链路跟踪,一次请求的逻辑轨迹可以完整清晰的展示出来。
- 各个调用环节的性能分析
- 调用链的各个环节分表添加调用耗时,可以分析出系统的性能瓶颈,并针对性的优化。
- 数据分析
- 调用链是一条完整的业务日志,可以得到用户的行为路径,汇总分析应用在很多业务场景
设计性能指标
| 项目 | 指标 |
|---|---|
| kafka | > 5000 Query Per Second |
| 数据延迟 | < 1 Min |
| 查询延迟 | < 3 Second |
相关软件与硬件
| 名称 | 数量 | 备注 |
|---|---|---|
| Kafka | 1套3节点 | 与监控系统共用一套集群,分属不同Topic |
| ElasticSearch | 1套3节点 | 与ELK共用一套集群,前提ELK需做扩容准备 |
| API机器 | 虚拟机3台 | 公司标准虚拟机配置4core 8G即可 |
系统限制
公司服务部署在多个机房中,但是分布式跟踪的数据需汇总收集并展示,故暂时进行采用不了多机房部署方案。考虑到分布式跟踪系统类似于ELK系统的基础服务,部署架构与现有ELK保证一致,核心服务部署在B7机房
设计思路
一般分布式跟踪系统, 主要有三个部分:数据收集,数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查,全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分享。虽然每一部分都可能变的很复杂,但基本原理都类似。
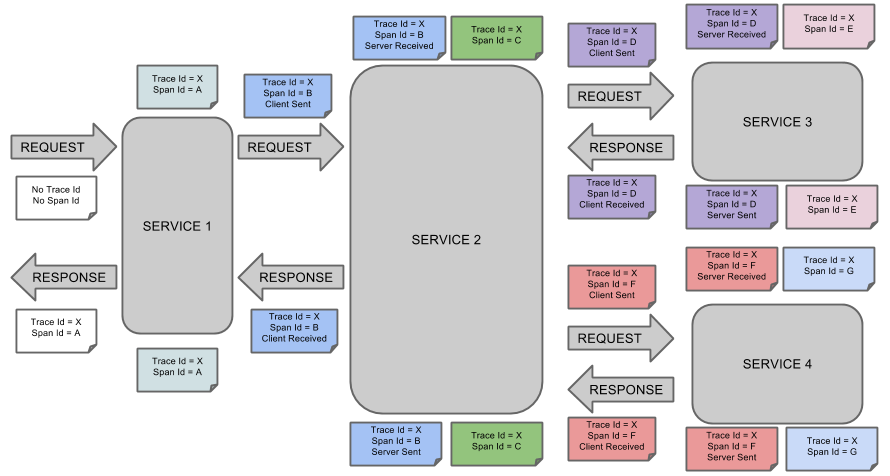
图1:这个路径由用户的X请求发起,穿过一个简单的服务系统。用字母标识的节点代表分布式系统中的不同处理过程。
分布式服务的跟踪系统需要记录在一次特定的请求后系统中完成的所有工作的信息。举个例子,图1展现的是一个和5台服务器相关的一个服务,包括:前端(A),两个中间层(B和C),以及两个后端(D和E)。当一个用户(这个用例的发起人)发起一个请求时,首先到达前端,然后发送两个RPC到服务器B和C。B会马上做出反应,但是C需要和后端的D和E交互之后再返还给A,由A来响应最初的请求。对于这样一个请求,简单实用的分布式跟踪的实现,就是为服务器上每一次你发送和接收动作来收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
黑盒和标签方案
为了将所有记录条目与发起者惯量上并记录所有信息,现在有两种解决方案,黑盒和基于标签(annotation-based)的监控方案。
黑盒方案采用framework为基础,将依赖集成进去,对各接入业务线透明。基于标签的方案,依赖业务线明确标记一个trace id,从而连接每一条记录和发起者的请求。基于标签的方案主要缺点很明显,需要植入与业务无关代码。所以默认情况下,我们提供基于hjframework公共组件的方案,实现跟踪系统对业务无感知。同时如果需要显示使用这个标签功能的话,我们同样提供出来,由业务方自行决定是否使用标签。
技术选型
| 公司 | 选项 | 是否开源 | 优缺点 |
|---|---|---|---|
| 淘宝 | EagleEye | 否 | 主要基于内部HSF实现,HSF没有开源,故鹰眼也没有开源 |
| Zipkin | 是 | 基于Http实现,支持语言较多,比较适合我们公司业务 | |
| 点评 | CAT | 是 | 自定义改造难度大,代码比较复杂,侵入代码,需要埋点 |
| 京东 | Hydra | 是 | 主要基于Dubbo实现,不适合公司Http请求为主的场景 |
综上所述,最终我们觉得采用Zipkin的方式来实现,比较适合公司目前以Http请求为主的场景。虽然采用第三方开源产品,但是客户端依赖的SDK,仍需我们开发集成到HJFramewor中。针对Node和JS,Zipkin同样提供对应的前端SDK,我们集成好之后,就能正常使用。
系统设计
整体架构图及说明
基于Zipkin的基础上,我们对其架构进行了扩展,基于Google Dapper的概念,设计一套基于Http的分布式跟踪系统。其种涵盖了信息的收集,处理和展现。
整体架构如下图所示,主要由四个部分构成:收集器、数据传输、数据存储、查询及web界面
收集器
业务方之间依赖我们提供的SDK,进行数据收集。其中SDK主要采用Spring Cloud中分布式跟踪模块是Spring Cloud Sleuth。该模块主要用于收集Spring boot系统中数据,发送至缓冲队列Kafka中。同时官方提供了针对Node、Python等一些常用的客户端SDK
数据传输
我们在SDK与后端服务之间加了一层Kafka,这样做既可以实现两边工程的解耦,又可以实现数据的延迟消费。我们不希望因为瞬时QPS过高而导致数据丢失,当然为此也付出了一些实效性上的代价。
数据存储
默认存储采用ElasticSearch 来保证数据,考虑到数据量的规模,先期只保存最近1个月的数据
查询及Web界面
查询主要用来向其他服务提供数据查询的能力,而Web服务是官方默认提供的图形化界面,我们会重写这块页面,使之与沪江内部平台结合起来。
SDK分析
调用链跟踪:把同一个TraceID和SpanID收集起来,按时间排序Timeline,把ParentID串起来就是调用栈。