背景
随着公司业务的高速发展以及数据爆炸式的增长,当前公司各产线都有关于搜索方面的需求,但是以前的搜索服务系统由于架构与业务上的设计,不能很好的满足各个业务线的期望,主要体现下面三个问题:
- 不能支持对语句级别的搜索,大量业务相关的属性根本无法实现
- 没有任何搜索相关的指标评价体系
- 扩展性与维护性特别差
基于现状,对行业内的搜索服务做出充分调研,确认使用ElasticSearch做底层索引存储,同时重新设计现有搜索服务,使其满足业务方对维护性、定制化搜索排序方面的需求。
整体技术架构
沪江搜索服务底层基于分布式搜索引擎ElasticSearch,ElasticSearch是一个基于Lucene构建的开源,分布式,Restful搜索引擎;能够达到近实时搜索,稳定,可靠,快速响应的要求。

搜索服务整体分为5个子系统
- 搜索服务(Search Server) : 提供搜索与查询的功能
- 更新服务(Index Server) : 提供增量更新与全量更新的功能
- Admin 控制台 : 提供UI界面,方便索引相关的维护操作
- ElasticSearch存储系统 : 底层索引数据存储服务
- 监控平台: 提供基于ELK日志与zabbix的监控
外部系统接口设计
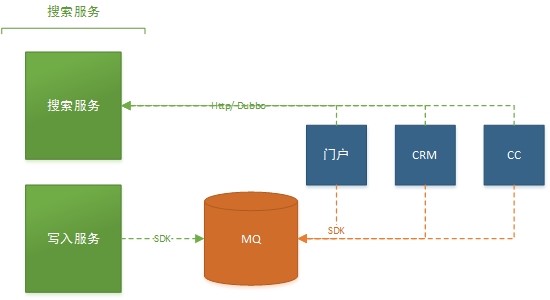
- 查询
- 查询接口提供http的调用方式,当出现跨机房访问的时候,请使用http接口,其余都可以使用dubbo RPC调用
- 增量更新
- 数据增量更新接口采用提供MQ的方式接入。当业务方出现数据更新的时候,只需将数据推送到对应的MQ通道中即可。更新服务会监听每个业务方通道,及时将数据更新到ElasticSearch中
- 全量索引
- 更新服务会调用业务方提供的全量Http接口(该接口需提供分页查询等功能)
全量更新
众所周知,全量更新的功能在搜索服务中是必不可少的一环。它主要能解决以下三个问题
- 业务方本身系统的故障,出现大量数据的丢失
- 业务高速发展产生增减字段或者修改分词算法等相关的需求
- 业务冷启动会有一次性导入大批量数据的需求
基于上面提到的问题,我们与业务方合作实现了全量索引。但是在这个过程中,我们也发现一个通用的问题。在进行全量更新的时候,其实增量更新也在同时进行,如果这两种更新同时在进行的话,就会有遇到少量增量更新的数据丢失。比如说下面这个场景
- 业务方发现自己搜索业务alias_A数据大量数据丢失,所以进行索引重建。其中alias_A是别名,就是我们通常说alias,但是底层真正的索引是index_201701011200(建议:索引里面包含时间属性,这样就能知道是什么创建的)
- 首先创建一个新的索引index_201706011200,然后从数据中拉出数据并插入ES中,并记录时间戳T1,最后索引完成的时间戳为T2,并切换搜索别名index_1指向index_201706011200。
- 索引创建成功之后的最新数据为T1这个时刻的,但是T1到T2这段时间的数据,并没有获取出来。同时index_201701011200老索引还在继续消费MQ中的数据,包括T1到T2时间内的缺少数据。
- 所以每次索引重建的时候,都会缺少T1到T2时间内的数据。
最后,针对上面这个场景,我们提出通过zookeeper分布式锁来暂停index consumer的消费,具体步骤如下
- 创建new_index
- 获取该index 对应的别名,来修改分布式锁的状态为stop
- index consumer监控stop状态,暂停索引数据的更新
- new_index索引数据创建完毕,更新分布式锁状态为start
- index consumer监控start状态,继续索引数据的更新
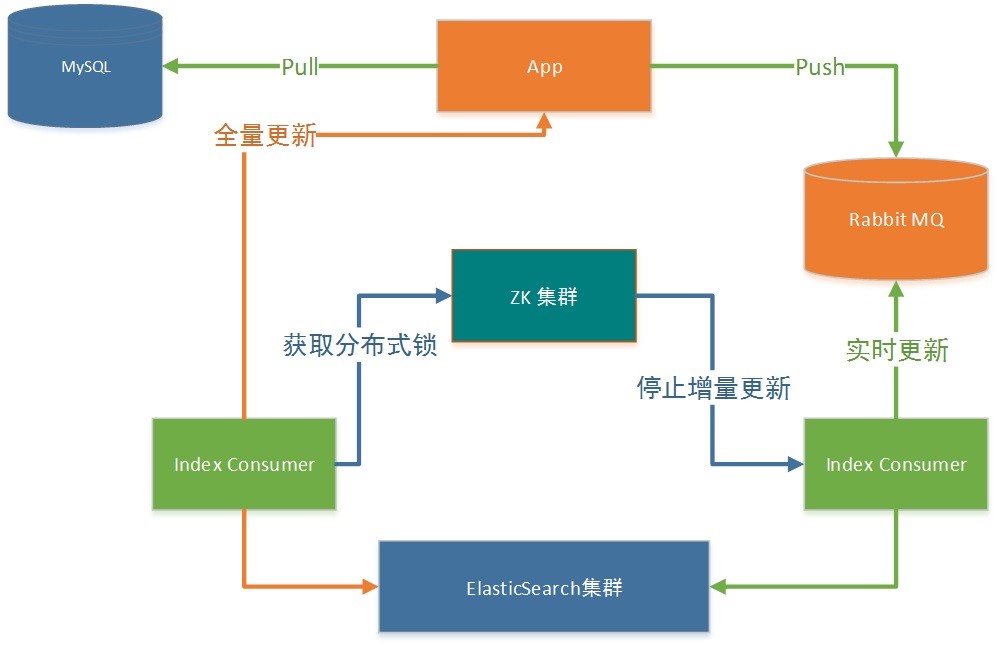
这样的话,我们就不用担心在创建索引的这段时间内,数据会有缺少的问题。相信大家对于这种方式解决全量与增量更新数据有所体会。
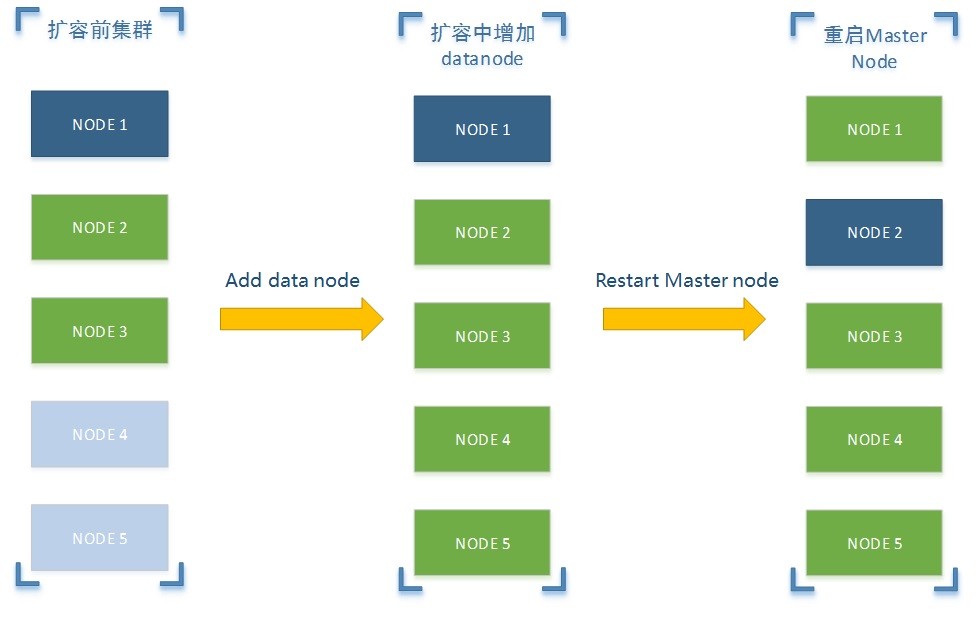
集群无缝扩容
数据量爆炸式的增加,导致我们ES集群最终还是遇到了容量不足的问题。在此背景下,同时结合ES本身提供的无缝扩容功能,我们最终决定对线上ES集群进行了在线的无缝扩容,将从原来的3台机器扩容为5台,具体步骤如下
- 扩容前准备
- 目前我们线上已经有3台机器正在运行着,其中node1为master节点,node2和node3为data节点,节点通信采用单播的形式而非广播的方式。
- 准备2台(node4与node5)机器,其中机器本身配置与ES配置参数需保持一致
- 扩容中增加节点
- 启动node4与node5(注意一个一个启动),启动完成之后,查看node1,2,3,4,5节点状态,正常情况下node1,2,3节点都已发现node4与node5,并且各节点之间状态应该是一致的
- 重启master node
- 修改node1,2,3节点配置与node4,5保持一致,然后顺序重启node2与node3,一定要优先重启data node,最后我们在重启node1(master node).到此为止,我们的线上ES集群就在线无缝的扩容完毕
部署优化
- 查询与更新服务分离
- 查询服务与更新服务在部署上进行物理隔离,这样可以隔离更新服务的不稳定对查询服务的影响
- 预留一半内存
- ES底层存储引擎是基于Lucene,Lucenede的倒排索引是先在内存中生成,然后定期以段的形式异步刷新到磁盘上,同时操作系统也会把这些段文件缓存起来,以便更快的访问。所以Lucene的性能取决于和OS的交互,如果你把所有的内存都分配给Elasticsearch,不留一点给Lucene,那你的全文检索性能会很差的。所有官方建议,预留一半以上内存给Lucene使用
- 内存不要超过32G
- 跨32G的时候,会出现一些现象使得内存使用率还不如低于32G,具体原因请参考官方提供的这篇文章 Don’t Cross 32 GB!
- 尽量避免使用wildcard
- 其实使用wildcard查询,有点类似于在数据库中使用左右通配符查询。(如:*foo*z这样的形式)
- 设置合理的刷新时间
- ES中默认index.refresh_interval参数为1s。对于大多数搜索场景来说,数据生效时间不需要这么及时,所以大家可以根据自己业务的容忍程度来调整
总结
本章主要介绍公司搜索服务的整体架构,重点对全量更新中数据一致性的问题,ES在线扩容做了一定的阐述,同时列举了一些公司在部署ES上做的一些优化。本文主要目的,希望大家通过阅读沪江搜索实践,能够给广大读者带来一些关于搭建一套通用搜索的建议。