参考链接:https://blog.csdn.net/u010454030/article/details/71762838
ES group分组聚合的坑
原来知道Elasticsearch在分组聚合时有一些坑但没有细究,今天又看了遍顺便做个笔记和大家分享一下。
我们都知道Elasticsearch是一个分布式的搜索引擎,每个索引都可以有多个分片,用来将一份大索引的数据切分成多个小的物理索引,解决单个索引数据量过大导致的性能问题,另外每个shard还可以配置多个副本,来保证高可靠以及更好的抗并发的能力。
将一个索引切分成多个shard,大多数时候是没有问题的,但是在es里面如果索引被切分成多个shard,在使用group进行聚合时,可能会出现问题,这个在官网文档里,描述也非常清楚
下面就针对官网的例子,描述下,group count如果有多个shard可能会出现的问题
假设我们现在,我们有一份商品的索引数据,它有3个shard,每个shard的数据如下所示:
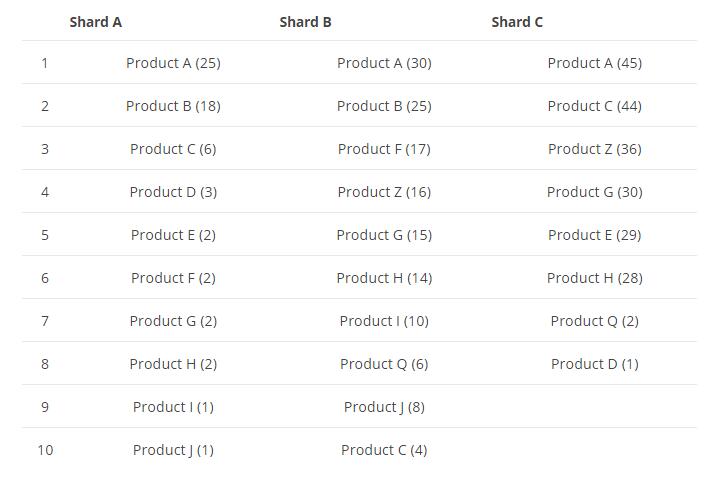
现在我们的需求是,按商品分组求top5的商品,es收到这个请求后,会去搜索这三个shard,然后子每个shard上面取top5,数据如下图所示:
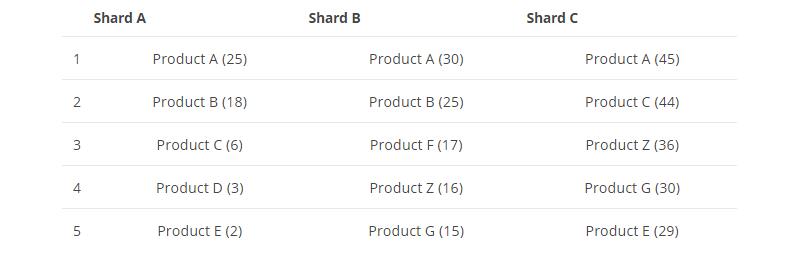
最后,将三个shard的top5的数据,最后做一下汇聚然后最终排序取top5结果如下图:
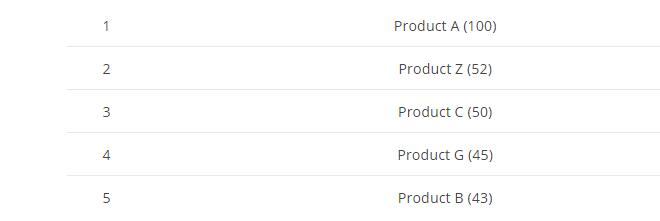
最后我们发现这个top5的结果,并不是100%精确的,只是一个近似精确的结果值:
Product A在所有top5的shard数据里面都存在,所以它的结果是精确的, Product C仅仅返回了 shard A 和 C里面的top5的数据,所以这里显示50是不精确的, Product C在shard B里面也存在,但是它在 top5里面没有出现,所以group后的结果实际上是有误差的,再来看下 Product Z仅仅返回了2个shards的数据 因为第三个里面不存在,所以它的结果是准确的,最后我们注意下 Product H实际上它的总数是44,横跨三个shard 但是它在每个shard的top5里面并没有出现,所以最终的top5里面也没有这条数据,这样看来最终的top5的值并不是100% 准确的,这一点在设计和使用es的时候需要特别注意。
虽然我们可以调大返回size的个数来提高精确度,但是size个数的提升,也意味着有更多的数据会被返回,从而会导致检索性能的下降,这一点是需要找到平衡点的。
那么有没有方法避免这种不精确的统计的呢?
答案是有的,es官网文档里面也提到,总共有2种:
第一种:
聚合操作在单个shard时是精确的,也就是说我们索引的数据全部插入到一个shard的时候 它的聚合统计结果是准确的。
第二种:
在索引数据的时候,使用route路由字段,将所有聚合的数据分布到同一个shard即可,这样再聚合时也是精确的。
上面的两种办法都是可以解决的,第一种适合数据量不大的场景下,我们直接把数据放在一份索引里面,第二种办法适合数据量比较大的场景下,我们通过业务字段将相同属性的数据路由在同一个shard里面即可,具体使用哪个需要和具体的业务场景相结合。
总结:
es虽然很强大,但是在一些场景下也是有局限的,比如上面提到的聚合分组的这个情况,或者聚合分组+分页的情况,此外min,max,sum这些函数在多个shard中聚合结果是准确的,count是近似准确的,但是es能保证top 前几的数据是精确的,这也是为什么搜索引擎一般都返回top n数据作为最终的返回结果,当然上面提到那个例子,如果聚合的key本来就很少,那么它的聚合结果也是准确的,比如按性别,月份聚合,因为这些返回的key,都是有限的,所以结果没问题,但是一旦对分组的个数没法确定,这种情况下出现问题的几率就比较大,跨表或者跨分片聚合其实在任何db系统里面都会存在这种问题,所以我们应该尽量在设计业务时就考虑到这种特殊情况,然后最终做特殊处理。