#准备数据
import sklearn
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
df = pd.read_csv('012-car.data',header=None)
dataset = df.values
# print(df.info())
# print(df.head()) #6个特征,1个标签,都是object类型,需要编码
encoder_list = [] #存放每一列的encoder #存放编码器
# print(dataset)
encoder_set = np.empty(dataset.shape)
for i in range(len(dataset[1])):
encoder = LabelEncoder()
encoder_set[:,i] = encoder.fit_transform(dataset[:,i])
encoder_list.append(encoder) #将编码器加入到
# print(encoder_set.shape)
#取出特征和标签并将fload转int类型
datasetX = encoder_set[:,:-1].astype(int)
datasetY = encoder_set[:,-1].astype(int)
train_X,test_X,train_Y,test_Y = train_test_split(datasetX,datasetY,test_size=0.2,random_state=30)
print(train_X.shape)
# 构建模型
#随机森林模型
from sklearn.ensemble import RandomForestClassifier
rf_regressor=RandomForestClassifier()
rf_regressor=RandomForestClassifier(n_estimators=1000,max_depth=10,min_samples_split=10)
rf_regressor.fit(train_X,train_Y) # 训练模型
# 使用测试集来评价该回归模型
predict_test_y=rf_regressor.predict(test_X)
# print(predict_test_y)
#精准率,精确率,召回率,F1
from sklearn.model_selection import cross_val_score
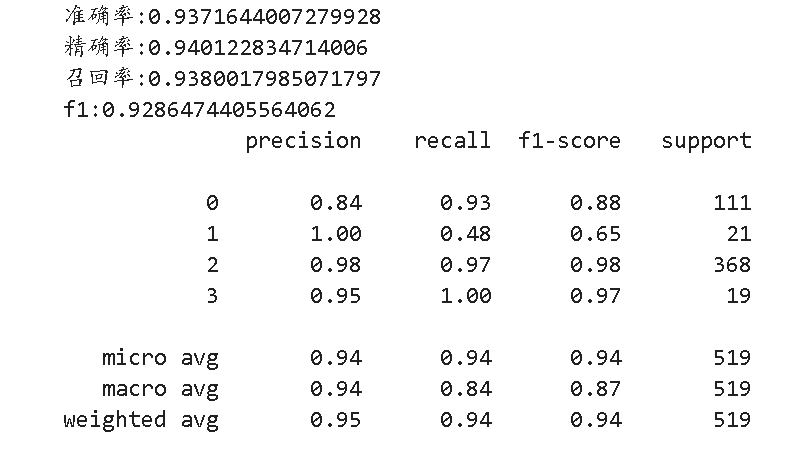
print('准确率:{}'.format(cross_val_score(rf_regressor,train_X,train_Y,scoring='accuracy',cv=6).mean()))
print('精确率:{}'.format(cross_val_score(rf_regressor,train_X,train_Y,scoring='precision_weighted',cv=6).mean()))
print('召回率:{}'.format(cross_val_score(rf_regressor,train_X,train_Y,scoring='recall_weighted',cv=6).mean()))
print('f1:{}'.format(cross_val_score(rf_regressor,train_X,train_Y,scoring='f1_weighted',cv=6).mean()))
from sklearn.metrics import classification_report
print(classification_report(y_pred=predict_test_y,y_true=test_Y))
#support:原数据类别个数
# 混合化矩阵
from matplotlib import pyplot as plt
%matplotlib inline
import numpy as np
import itertools
from sklearn.metrics import confusion_matrix
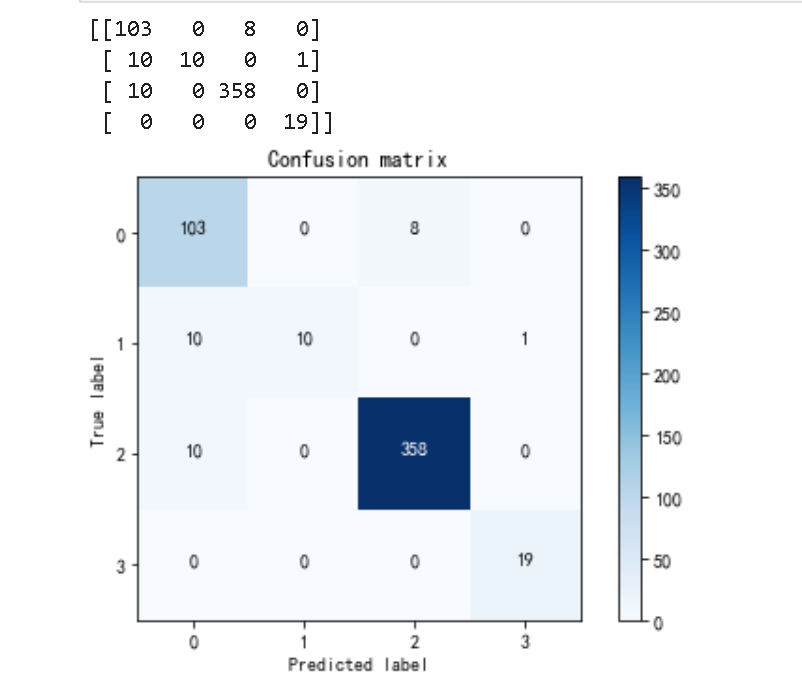
con_matrix = confusion_matrix(y_pred=predict_test_y,y_true=test_Y)
# print(y_pre.shape)
# print(dataset_y.shape)
print(con_matrix) #查看混淆矩阵
# 可视化混淆矩阵
def plot_confusion_matrix(confusion_mat):
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(confusion_mat.shape[0])
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
thresh = confusion_mat.max() / 2.
for i, j in itertools.product(range(confusion_mat.shape[0]), range(confusion_mat.shape[1])):
plt.text(j, i, confusion_mat[i, j],
horizontalalignment="center",
color="white" if confusion_mat[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
plot_confusion_matrix(con_matrix)
#构造数据
new_data = ['low','high','5more','4','big','high']
data_result = np.empty(np.array(new_data).shape)
# print(data_result)
for i,value in enumerate(new_data):
data_result[i] = encoder_list[i].transform([value]) #注意,不要fit
y_pre = rf_regressor.predict([data_result])
#解码
print(encoder_list[-1].inverse_transform(y_pre)) #解码也用原数据
# 模型调优
# 参数组合:验证曲线
#训集合大小:学习曲线
#模型调优,验证曲线
from sklearn.model_selection import validation_curve
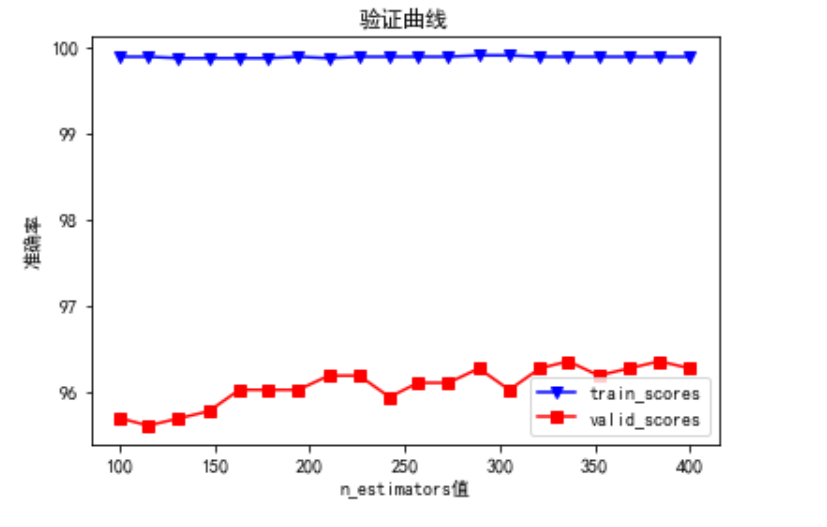
vc_classifer = RandomForestClassifier(n_estimators=140,max_depth=10,random_state=9)
#生成一组参数列表
param_grid = np.linspace(start=100,stop=400,num=20).astype(int)
# print(param_grid)
#获取训练得分和验证得分
train_score,validation_score = validation_curve(vc_classifer,train_X,train_Y,'n_estimators',param_grid,cv=6)
print(train_score)
print(validation_score)
# 定义一个绘图函数,绘制train scores 和valid scores
def plot_valid_curve(grid_arr,train_scores,valid_scores,
title=None,x_label=None,y_label=None):
'''plot train_scores and valid_scores into a line graph'''
assert train_scores.shape==valid_scores.shape,
'expect train_scores and valid_scores have same shape'
assert grid_arr.shape[0]==train_scores.shape[0],
'expect grid_arr has the same first dim with train_scores'
plt.figure()
plt.plot(grid_arr, 100*np.average(train_scores, axis=1),
color='blue',marker='v',label='train_scores')
plt.plot(grid_arr, 100*np.average(valid_scores, axis=1),
color='red',marker='s',label='valid_scores')
plt.title(title) if title is not None else None
plt.xlabel(x_label) if x_label is not None else None
plt.ylabel(y_label) if y_label is not None else None
plt.legend()
plt.show()
#调用函数
plot_valid_curve(param_grid,train_score,validation_score,'验证曲线','n_estimators值','准确率')
#学习曲线
from sklearn.model_selection import learning_curve
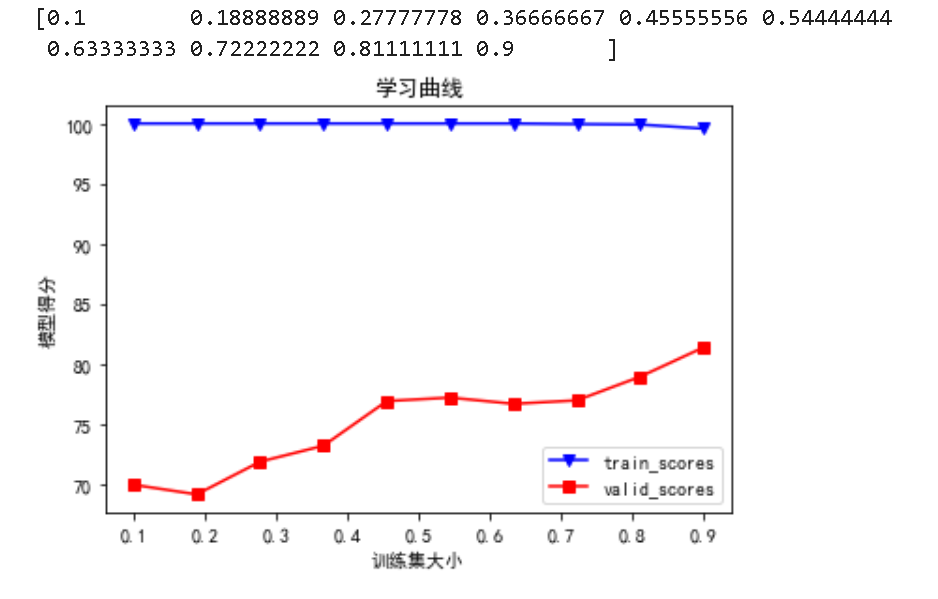
lc_classifer = RandomForestClassifier(n_estimators=140,max_depth=10,random_state=9)
param_spilit = np.linspace(start=0.1,stop=0.9,num=10)
print(param_spilit)
train_sizes,train_score,validation_score = learning_curve(lc_classifer,datasetX,datasetY,train_sizes=param_spilit,cv=6)
plot_valid_curve(param_spilit,train_score,validation_score,'学习曲线','训练集大小','模型得分')
# 最终模型
train_X,test_X,train_Y,test_Y = train_test_split(datasetX,datasetY,test_size=0.45,random_state=30)
lasthear = RandomForestClassifier(n_estimators=140,max_depth=10,min_samples_split=10)
lasthear.fit(train_X,train_Y)
from sklearn.model_selection import cross_val_score
print('准确率:{}'.format(cross_val_score(lasthear,train_X,train_Y,scoring='accuracy',cv=6).mean()))
print('精确率:{}'.format(cross_val_score(lasthear,train_X,train_Y,scoring='precision_weighted',cv=6).mean()))
print('召回率:{}'.format(cross_val_score(lasthear,train_X,train_Y,scoring='recall_weighted',cv=6).mean()))
print('f1:{}'.format(cross_val_score(lasthear,train_X,train_Y,scoring='f1_weighted',cv=6).mean()))
