import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import matplotlib
from sklearn import datasets
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
data=pd.read_csv('010-data_multivar.csv',header=None)
# print(data)
#拆分数据
dataset_X,dataset_y=data.iloc[:,:-1],data.iloc[:,-1]
dataset_X=dataset_X.values
dataset_y=dataset_y.values
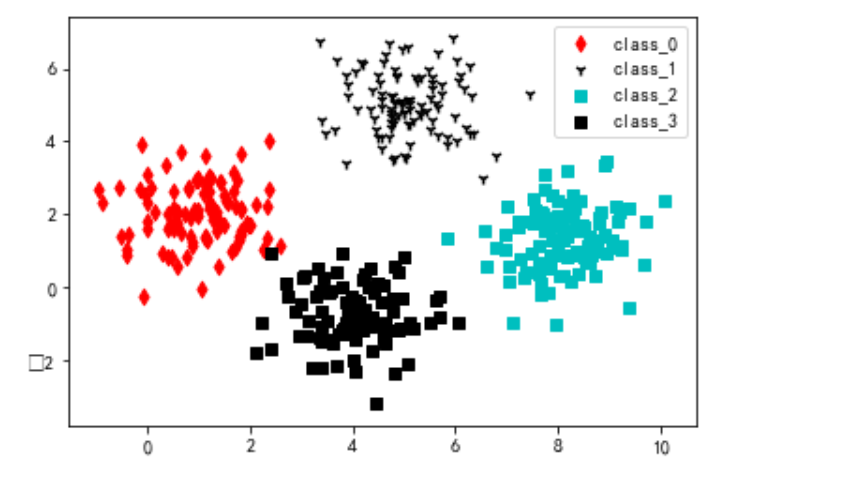
def visual_2D_dataset(dataset_X,dataset_y):
'''将二维数据集dataset_X和对应的类别dataset_y显示在散点图中'''
assert dataset_X.shape[1]==2,'only support dataset with 2 features'
plt.figure()
classes=list(set(dataset_y))
markers=['.',',','o','v','^','<','>','1','2','3','4','8'
,'s','p','*','h','H','+','x','D','d','|']
colors=['b','c','g','k','m','w','r','y']
for class_id in classes:
one_class=np.array([feature for (feature,label) in
zip(dataset_X,dataset_y) if label==class_id])
plt.scatter(one_class[:,0],one_class[:,1],marker=np.random.choice(markers,1)[0],
c=np.random.choice(colors,1)[0],label='class_'+str(class_id))
plt.legend()
visual_2D_dataset(dataset_X,dataset_y)
# 构造kmeans模型
from sklearn.cluster import KMeans
# init:初始化
kmeans = KMeans(init='k-means++',n_clusters=4,n_init=5,n_jobs=2)
kmeans.fit(dataset_X)
print(kmeans.cluster_centers_) # 质心点坐标

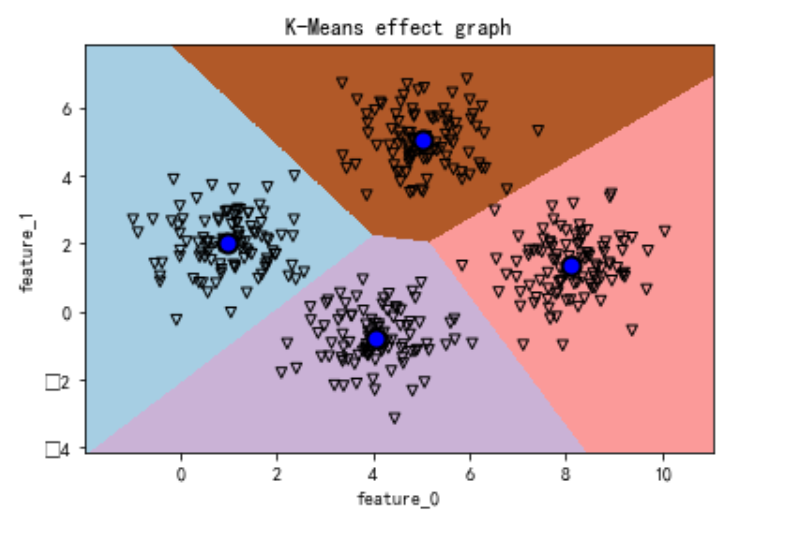
# 将dataset_X聚类效果可视化
def visual_kmeans_effect(k_means,dataset):
assert dataset.shape[1]==2,'only support dataset with 2 features'
X=dataset[:,0]
Y=dataset[:,1]
X_min,X_max=np.min(X)-1,np.max(X)+1
Y_min,Y_max=np.min(Y)-1,np.max(Y)+1
# meshgrid 生成网格点坐标矩阵
X_values,Y_values=np.meshgrid(np.arange(X_min,X_max,0.01),
np.arange(Y_min,Y_max,0.01))
# 预测网格点的标记
predict_labels=k_means.predict(np.c_[X_values.ravel(),Y_values.ravel()])
predict_labels=predict_labels.reshape(X_values.shape)
plt.figure()
plt.imshow(predict_labels,interpolation='nearest',
extent=(X_values.min(),X_values.max(),
Y_values.min(),Y_values.max()),
cmap=plt.cm.Paired,
aspect='auto',
origin='lower')
# 将数据集绘制到图表中
plt.scatter(X,Y,marker='v',facecolors='none',edgecolors='k',s=30)
# 将中心点绘制到图中
centroids=k_means.cluster_centers_
plt.scatter(centroids[:,0],centroids[:,1],marker='o',
s=100,linewidths=2,color='k',zorder=5,facecolors='b')
plt.title('K-Means effect graph')
plt.xlim(X_min,X_max)
plt.ylim(Y_min,Y_max)
plt.xlabel('feature_0')
plt.ylabel('feature_1')
plt.show()
visual_kmeans_effect(kmeans,dataset_X)
# 鸢尾花聚类
from sklearn.datasets import load_iris
datairis = load_iris()
dataset = datairis.data
from sklearn.cluster import KMeans
kmeans = KMeans(init='k-means++',n_clusters=3,n_init=11,n_jobs=2)
kmeans.fit(dataset)
print('聚类结果:
',kmeans.labels_)
print('原数据:
',datairis.target)
print(kmeans.labels_ == datairis.target) # 去除标签

