
介绍
apache kafka是一个分布式流式处理平台,一个流式平台该有的三个关键能力:
- 发布、订阅流式数据。从这个角度讲类似消息队列或者企业消息系统;
- 容错的数据存储机制;
- 实时处理数据。
kafka的优点:
- 在系统、应用之间创建可靠的实时流式数据管道;
- 创建实时流式数据处理应用。
为了解kafka如何实现以上几点,我们深入探讨kafka能力。
首先是了解一些概念:
- kafka作为集群运行在一台或者多台服务器上
- kafka按分类存储数据(被称为topic)
- 每条数据由key,value,时间戳组成.
一些术语
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。 - Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。对于一个topic,3个分区,则同一组消费者数量应当<=3,否则有消费者接受不到数据; - Producer
负责发布消息到Kafka broker - Consumer
消息消费者,向Kafka broker读取消息的客户端。 - Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
kafka的四个核心api
- 生产者api
- 消费者api
- 流式处理api
- 连接api,将topic连接到现有的应用程序或数据系统。
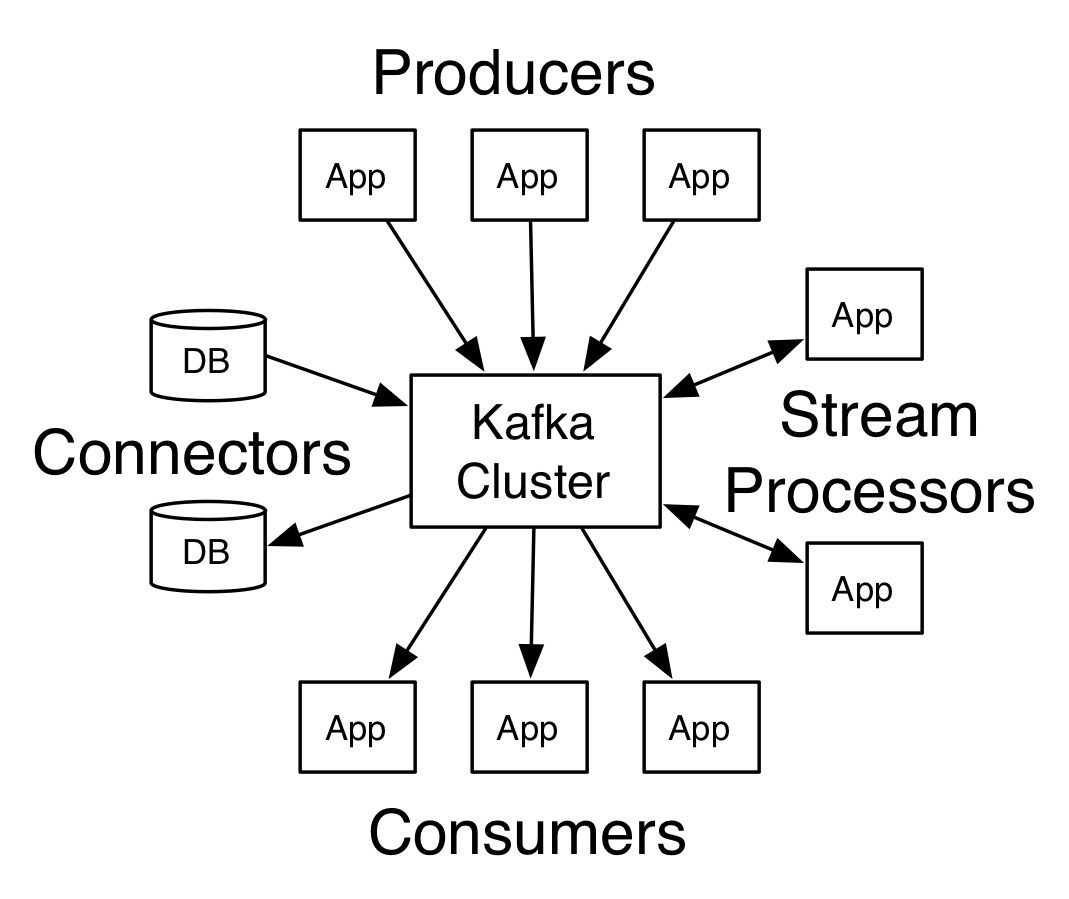
在kafka中连通服务器和客户端使用的是简单、高效、语言无关的tcp协议。目前的协议和旧版本协议兼容,我们提供java等多语言客户端。
Topics和Logs
topic就是消息分类,一个topic可以有0-n个消息订阅者。
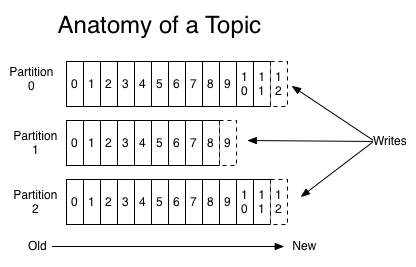
如图,每个分区是有序的数据连续不断的追加到日志文件结构末尾。分区中的记录被赋予一个分区内唯一的值,这个值被称作offset。
在kafka集群中保留所有发布的数据-无论是否被消费过-通过配置设置保留时间。比如,保留策略设置为两天,那么等记录分布两天内,这条数据是可消费的,之后数据将被删除以用来释放空间。kafka读写性能稳定和数据大小无关(这个是kafka牛逼的地方)。
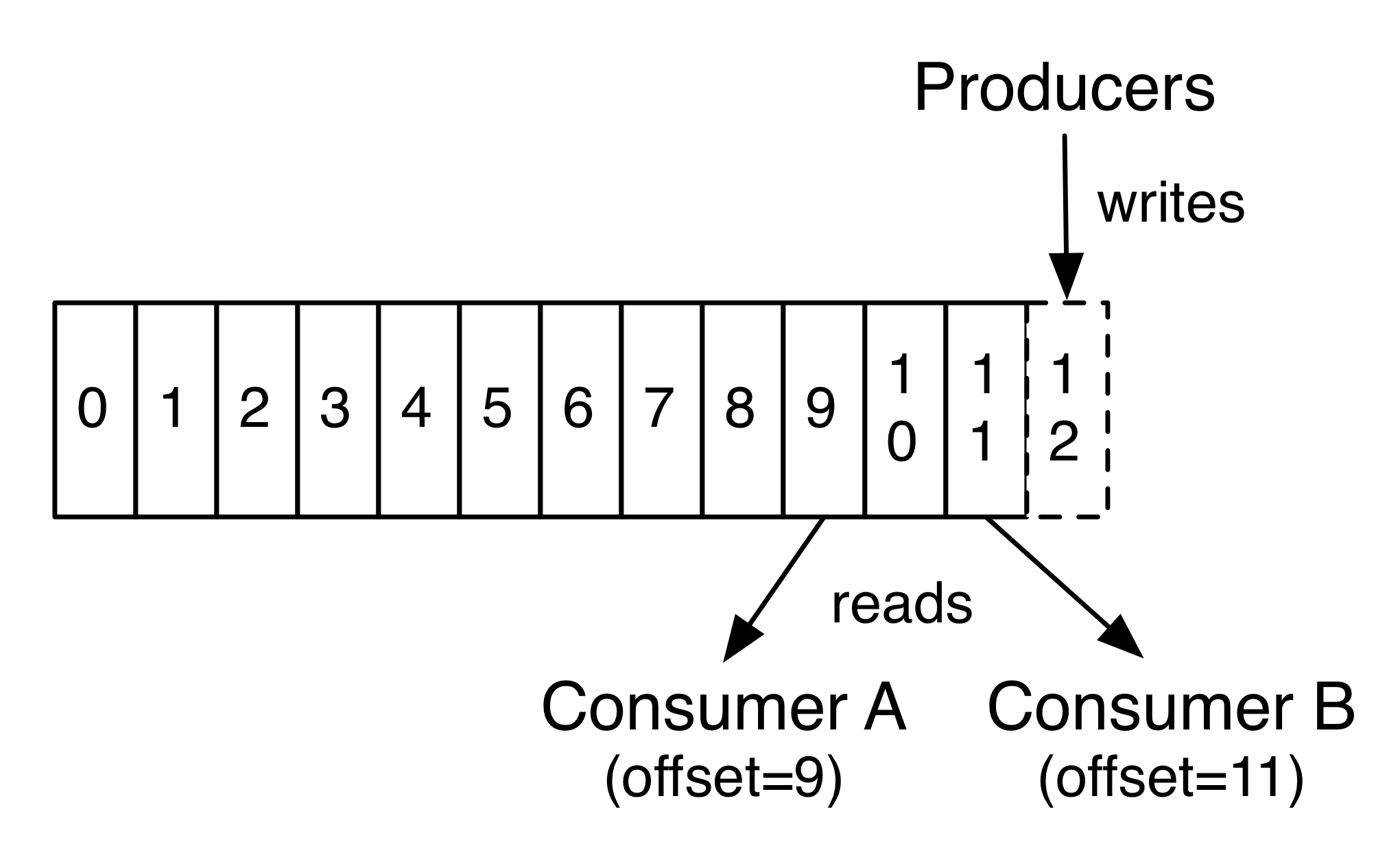
实际上,消费者保留的唯一元数据就是offset,通常offset由0线性增长,但是实际上因为这个值是消费者可控的,所以可以从0开始,也可以从最新一条数据的offset开始。
分布式
数据的分区被集群分布在kafka的多个服务器上,每个服务器处理它分到的分区,并向共同的分区请求数据。分区数通过配置文件设置,每个分区复制数据。(这就是所谓的容错机制,和hadoop优点像)
每个分区中有个服务器作为leader,其余0-n个服务器作为followers。leader处理所有的读写请求,其余的follow被动的复制leader的数据。如果leader服务器挂了,followers 中的一台服务器会被选举成新leader。一台服务器可能同时是一个分区的leader,另一个分区的follower。这样做到负载均衡,避免所有的请求都只让一台或少数几台服务器处理。
如果leader不挂,followers没有存在的意义。但lead挂了时,我们需要从followers节点中选出一个主。
note:一个topic可以有多个复制版本(replication-factor 指定具体broker数目),一个broker多个分区(partitions 数目),broker之间数据应该是相同的,而同一个broker每个分区数据应该是不一样的
broker-0
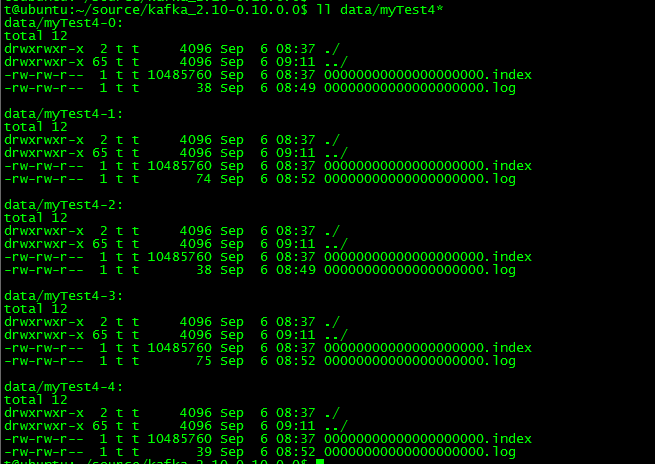
broker-1
brokerid=2
------------------------------------------------------------------------------------

生产者
生产者向自己指定的topic写数据,生产者的主要职责是选择发布到topic的哪个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。开发者负责如何选择分区的算法。
消费者
消费者以组名被标记,如果所有消费者共有一个消费者组名,那么记录将在消费者中高效平衡的均匀发布。如果所有消费者都使用不同的组名,那就是一个消息广播。
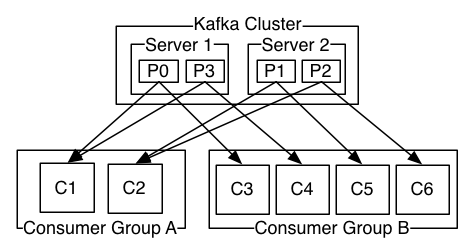
2个kafka集群托管4个分区(P0-P3),2个消费者组,消费组A有2个消费者实例,消费组B有4个。
正像传统的消息系统一样,Kafka保证消息的顺序不变。 再详细扯几句。传统的队列模型保持消息,并且保证它们的先后顺序不变。但是, 尽管服务器保证了消息的顺序,消息还是异步的发送给各个消费者,消费者收到消息的先后顺序不能保证了。这也意味着并行消费将不能保证消息的先后顺序。用过传统的消息系统的同学肯定清楚,消息的顺序处理很让人头痛。如果只让一个消费者处理消息,又违背了并行处理的初衷。 在这一点上Kafka做的更好,尽管并没有完全解决上述问题。 Kafka采用了一种分而治之的策略:分区。 因为Topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
保证
消息的发送顺序就是消息的保存顺序,也就是消费者接收消息的顺序。一个topic的 replication factor如果设置为n,那么即使n-1台服务器挂了,数据也不会丢失。
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能.一个持久化的队列可以构建在对一个文件的读和追加上,就像一般情况下的日志解决方案。尽管和B树相比,这种结构不能支持丰富的语义,但是它有一个优点,所有的操作都是常数时间,并且读写之间不会相互阻塞。这种设计具有极大的性能优势:最终系统性能和数据大小完全无关,服务器可以充分利用廉价的硬盘来提供高效的消息服务。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输
- 同时支持离线数据处理和实时数据处理
kefka可以作为消息系统,存储系统,流式处理系统。也可以把它们整合起来。
转载于:https://my.oschina.net/u/856051/blog/1529423