一、分类、定位和检测
简单来说,分类、定位和检测的区别如下:
-
分类:是什么?
-
定位:在哪里?是什么?(单个目标)
-
检测:在哪里?分别是什么?(多个目标)
| |
|
|
|
(1)目标分类 |
(2)目标定位 |
(3)目标检测 |
二、目标定位:
1)案例1:在构建自动驾驶时,需要定位出照片中的行人、汽车、摩托车和背景,即四个类别。
输出:

1,2,3为要检测的行人、汽车、摩托车, Pc=1
4为背景, Pc=0
Pc:首先第一个元素pc=1表示有要定位的物体的概率,即是有1,2,3类的概率,否则pc=0表示只有背景第4类如上图的第二个图。
bx,by,bh,bw:这四个输出元素表示定位框的中心坐标bx,by和宽高bh,bw
c1,c2,c3:3个输出元素one-hot表示是三个类别(1,2,3)中的哪一类。
当第一个元素pc=0时表示是背景,然后就不需要考虑其他输出了
损失函数:
输出向量中有8个元素:故:
if y1 =1 ,L = (y'1-y1)2 + (y'2-y2)2 + ……+(y'8-y8)2
if y1 = 0,L = (y'1-y1)2
实际使用中pc使用逻辑回归,c1,c2,c3是用softmax激活然后用对数损失函数,位置信息是使用平方误差损失函数,然后将这些损失函数相加起来得到最终的代价函数。当标签y=0时,只考虑pc即可。
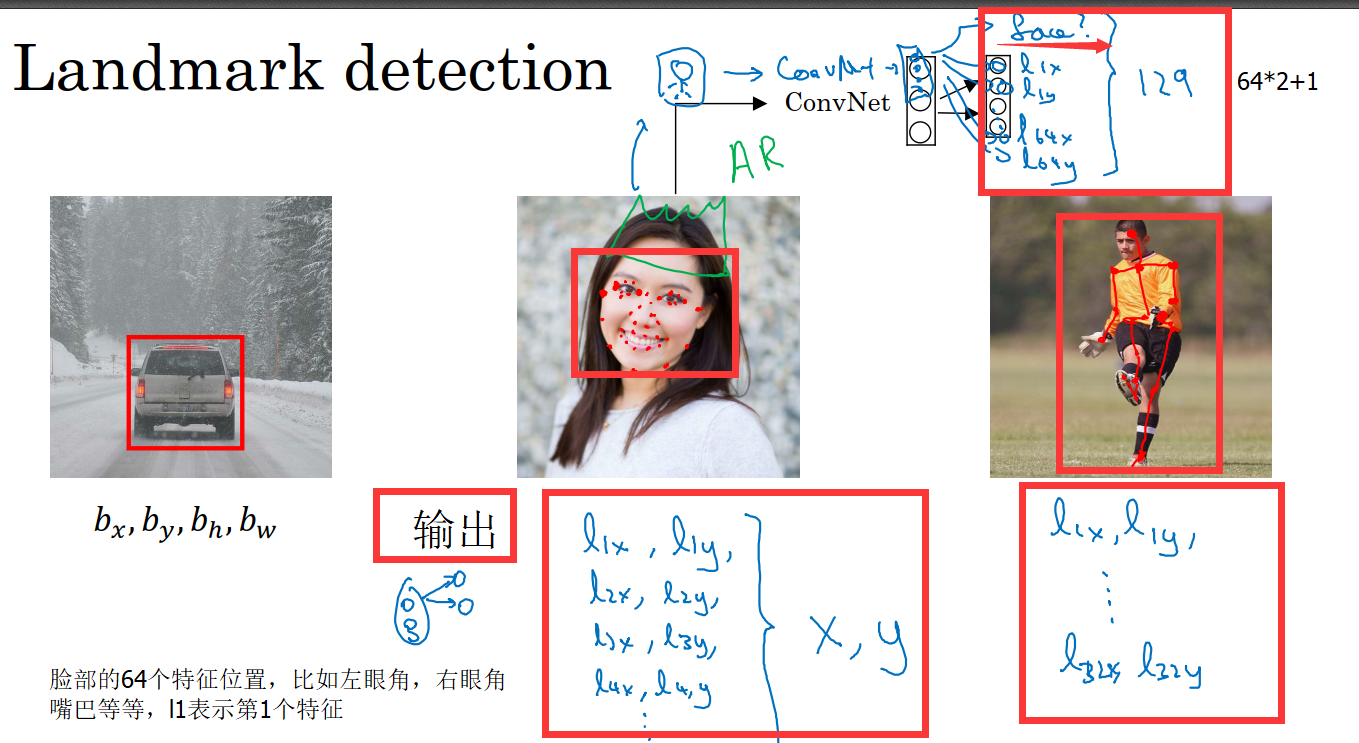
三、特征点检测:
特征点检测就是第一个单元输出1,表示有这个对象(如人脸),
然后如果在人脸上定义了64个特征点(如下图所示),每个特征点用(x,y)表示,那么网络将会有1+2*68=129个单元输出。
需要注意的一点是在标注样本时,所有标签在所有图片中务必保持一致,比如说,第5个特征点表示左眼的外眼角,那么所有图片的第五个特征点都应该是这个。
四、目标检测:滑动窗口、YOLO算法【更好解决边界】
https://www.cnblogs.com/ys99/p/9326637.html
传统的窗口滑动:将图片切割成很多小窗口,然后进行目标检测。直到某个小窗口检测到目标。
卷积的滑动窗口实现:在原输入补上边,在进行卷积操作,得到结果。
例如:
原输入是14*14*3,输出是1*1*4【4个分类】。传统的滑动窗口是将原输入切成4个,每个大小为12*12*3。经过重复4次卷积操作得到4个1*1*4。
卷积的滑动窗口:将原输入补成16*16*3,输出为2*2*4。只需要经过一次卷积操作就可以得到和4个1*1*4相同的结果2*2*4=2*2*(1*1*4)。
交并比函数是用来判断对象定位是否准确,IoU=(A∩B)/(A∪B),一般将交并比的值大于0.5看成是检测正确的,当然这个值可以根据实际情况来定。
转载于:https://www.cnblogs.com/Lee-yl/p/10015979.html