三大引擎:myisam(cms等)、innodb(商城等)、memory(临时存储在内存中)
一、数据类型
char:长度固定;最多255个字符;效率高,没有碎片,更新频繁的时候,方便数据文件指针的操作。
varchar:长度可变、灵活;最多65532( 65535-1-2)个字符,可变类型,一般保存字母、数字、特殊字符
tinytext:1字节,范围(-128~127)
text:65535个字符
boolean:1或者0
int:4字节,数字,范围(-2147483648~2147483647)
datetime:8字节,日期时间,格式:2014-09-18 08:42:30
bigint:8字节,范围(+-9.22*10的18次方)
smallint:2字节,范围(-32768~32767)
mediumint:3字节,范围(-8388608~8388607)
二、CRUD操作,增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete):
1.insert:增
“insert into” 增加 ,返回值为数字,没有操作是0。例如,insert into user(username,pwd)values("3131","12345678");在数据表末尾加入一行数据
2.DELETE:删 / truncate table '表名';
“delete from”删除,不加条件删除整个数据表。例如,DELETE FROM `user` WHERE id=25;删除id为25的数据 “in”多个删除,返回值为数字,没有操作是0。例如,DELETE * FROM `user` WHERE id in(3,5,7);删除id中为3、5、7的3个的数据
3.update:改,修改,必须加条件,返回值为数字,不能是0
update 表 set 字段名=新值,字段名=新值 where 。//例如,update user set username = '张三' where id = 8;将id=8处修改为..
4.SELECT:查(having-聚合后进行过滤,where-聚合前进行过滤(范围更小))
“=“等于 “<>”不等于//例如,SELECT * FROM `user` WHERE username<>"tom"; 不等于tom的 “<”小于 “>”大于//例如,SELECT * FROM `user` WHERE id>"5";id大于5的 “<=”小于等于 “>=”大于等于 “between..and..”之间 //例如,SELECT * FROM `user` WHERE id between 5 and 10;id为5-10之间的 “like ‘%..%’”模糊查询 //例如,SELECT * FROM `user` WHERE username like "%t%";“%”替代符,t之前或之后,有无字符都符合 “in(..)”指定数据 //例如,SELECT * FROM `user` WHERE id in(3,5,7);id中为3、5、7的3个的 “..and..”多个条件 //例如,SELECT * FROM `user` WHERE username="tom" and pwd="12";查询username为tom和pwd为12的,并的关系 “or()”或者.. //例如,SELECT * FROM `user` WHERE username="95" or pwd="12";查询username为95或pwd为12的,或的关系 “order by..descend(降)、ascend(升)”排序 //SELECT * FROM `user` order by id desc; “limit”对结果进行限制输出 //例如,SELECT * FROM `user` order by id desc limit 0,5;“0,5”id降序输出id当前页的第一个数据开始的5个数据 “is null”为null “is not null”不为null
is null在查询中的简单使用:

“group by”用于结合合计(sum)等函数,根据一个或多个列对结果集进行分组。//select sum(kucun_num) from h_goods_kucun where hid = 60 and ks_id = 43 GROUP BY g_code;查询每个g_code的kucun_num合计后的总数。
与group by结合统计的函数:
Count 统计数量,参数是要统计的字段名(可选)
Max 获取最大值,参数是要统计的字段名(必须)
Min 获取最小值,参数是要统计的字段名(必须)
Avg 获取平均值,参数是要统计的字段名(必须)
Sum 获取总分,参数是要统计的字段名(必须)

“distinct”将表中的记录去掉重复后显示出来 //例如,select distinct ks_id from h_check;将h_check表的字段ks_id中去除重复数据后,显示出来 “聚合”进行一些汇总操作,比如统计整个公司的人数或者统计每个部门的人 //例如,select ks_id,count(0) from h_check group by ks_id with rollup;查出ks_id的每个数据的条数 //例如,select ks_id,count(1) from h_check group by ks_id having count(1)>1;统计大于1的数据

5.子查询:关键字主要包括 in、not in、=、!=、exists、not exists 等
“in” //例如,select * from emp where deptno in(select deptno from dept); “=”子查询记录数唯一时 //例如,select * from emp where deptno = (select deptno from dept); //例如,select * from emp where deptno = (select deptno from dept limit 1); 子查询转为表连接: select * from emp where deptno in(select deptno from dept); ===》select emp.* from emp ,dept where emp.deptno=dept.deptno;
6.多表查询:
user as u:为user表取别名u;例如:select u.username,v.money from user as u,vip as v 运用"Id_P"相等,将两个表Persons和Orders联系起来,获取数据。SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons, Orders WHERE Persons.Id_P = Orders.Id_P
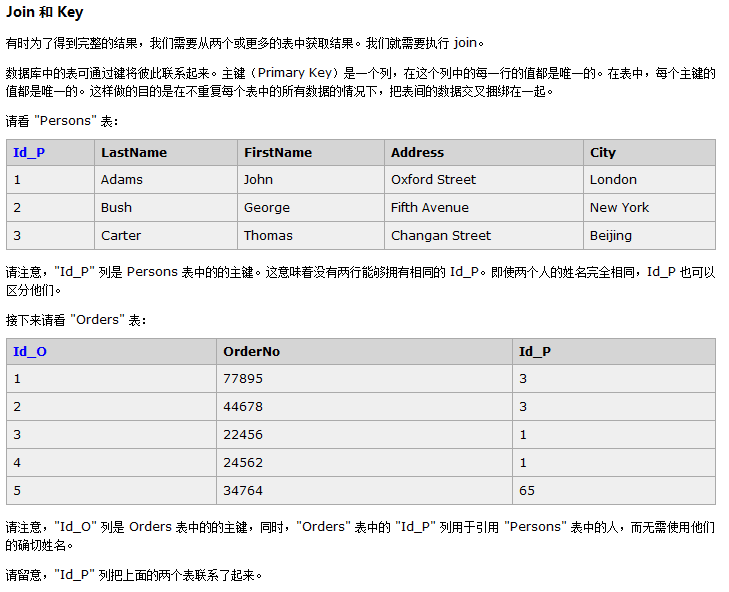
使用Join关键词来从两个表中获取数据:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons INNER JOIN Orders ON Persons.Id_P = Orders.Id_P ORDER BY Persons.LastName;
INNER JOIN:内连接
JOIN: 如果表中有至少一个匹配,则返回行
LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
FULL JOIN: 只要其中一个表中存在匹配,就返回行
连接:
交叉连接:又叫笛卡尔积,它是指不使用任何条件,直接将一个表的所有记录和另一个表中的所有记录一一匹配。
内连接:是只有条件的交叉连接,根据某个条件筛选出符合条件的记录,不符合条件的记录不会出现在结果集中,即内连接只连接匹配的行。
外连接:结果集中不仅包含符合连接条件的行,而且还会包括左表、右表或两个表中的所有数据行,这三种情况依次称之为左外连接,右外连接,和全外连接。
左外连接:也称左连接,左表为主表,左表中的所有记录都会出现在结果集中,对于那些在右表中并没有匹配的记录,仍然要显示,右边对应的那些字段值以 NULL 来填充。
右外连接:也称右连接,右表为主表,右表中的所有记录都会出现在结果集中。
全外连接:左连接和右连接可以互换,MySQL 目前还不支持全外连接。
Union使用:进行一次distinct,会列出所有不重复的字符。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。(并且union只会列出不同的字符)
Union ALL使用:结果集直接合并在一起。
单个字段查询:
SELECT username FROM user。查询user表中的username
多个字段查询:
SELECT username,pwd FROM `user`。查询user表中的username、pwd
所有字段查询(*):
SELECT * FROM `user`。“*”通配符,代表所有字段,返回一张临时的表(结果集)
条件查询(where):这里需要注意与having的区别!where是在查询的时候进行结果过滤,having是对查询后的结果进行过滤,切记!切记!切记!!!
SELECT * FROM `user` WHERE username="tom"。查询user表中的所有username为tom的
三、数据库结构操作
创建数据库:
1.create database member; //简单创建member数据库 2.create database member default character set utf8 collate utf8_general_ci; //default character set utf8,默认utf8字符集;collate utf8_general_ci,在utf8中默认大小写不敏感 3.create database if not wxists member default character set utf8 collate utf8_general_ci; //如果数据库不存在,就创建数据库并设置字符集
删除数据库:
drop database member;//删除member数据库
创建数据表:
1.create table member.javascript(id int); //在数据库member中创建数据表javascript,添加单个字段 2.create table if not exists member.javascript(id int); //如果不存在数据表,就创建javascript,并添加字段id 3.create table vip(id int not null auto_increment,money int,primary key(id)); //创建vip表,并设置id和money属性 3.create table if not exists member.javascript(id int auto_increment,username varchar(130),pwd varchar(32), email varchar(132),regTime datetime,primary key(id),unique key(username), key (pwd),fulltext key (email)); //添加多个字段, primary key(id)把id设为主键,auto_increment自动增加
删除数据表:
"drop table member.javascript; //在数据库member中删除数据表javascript"
在数据表存在时,添加字段:
alter table javascript add address varchar(130);
在数据表存在时,修改字段:
alter table javascript change address newadd int(130);
在数据表存在时,删除字段:
alter table javascript drop newadd;
修改字段为不可重复:
ALTER TABLE dbname.table ADD UNIQUE (fieldname);
查看数据库表结构、列及其注释:
select * from information_schema.columns where table_schema = 'db' #表所在数据库 and table_name = 'tablename' ; #你要查的表
查看数据库结构表及其注释:
select table_name,table_comment from information_schema.tables where table_schema = 'db' and table_name ='tablename';
查看数据库中所有数据表名:
show tables;
查看数据库名:
select database();
索引操作:
创建索引(可以非常快速定位我们需要找到的信息。):
主键索引:alter table 表名 add primary key [索引名称(可填可不填)] (id);
唯一索引:alter table 表名 add unique key [索引名称(可填可不填)](id);
普通索引:alter table 表名 add key [索引名称(可填可不填)] (id);
全文索引:alter table 表名 add fulltext key [索引名称(可填可不填)] (id);
全文索引(目前只有5.6以上版本innodb支持,myisam则全部支持):
创建:alter table 表名 add fulltext key [索引名称(可填可不填)] (id); 使用:select * from 表名 where match(字段名) against('内容'); 注意:
①普通的模糊查找是不会用到全文索引!! ②目前只有5.6以上版本innodb支持,myisam则全部支持 ③字段类型varchar、char、text支持 ④现阶段只支持英文,中文须使用第三方软件sphinx ⑤mysql的全文索引会自作聪明,对关键字的收录有自己的考虑,例如:生活常用单词、频繁使用的单词
复合全文索引:
创建:alter table 表名 add fulltext key [索引名称(可填可不填)] (字段A,字段B); 使用:select * from 表名 where match(字段A,字段B) against('内容A,内容B');
创建复合索引:
alter table 表名 add key [索引名称(可填可不填] (字段A,字段B,....);
创建前缀索引:
alter table 表名 add key (字段名(前n位位数)); select count(distinct substring(字段名,开始位置,长度n)) from emp;//获取前几位适合做前缀索引
创建自增特性:
alter table 表名 modify id int(11)unsigned auto_increment comment '主键';
删除非主键索引和主键索引:
alter table 表名 drop key 索引名称;//非主键索引删除 alter table 表名 modify id int(11)unsigned not null comment '主键';//删除主键索引前须去掉自增特性 alter table 表名 drop primary key;//主键索引删除
四、函数
rowCount();数据总记录数
current_time() 日期时间函数返回当前本地时间。
date_format(datetime, format)用于格式化日期,如:select date_format(now(),'%Y%m%d');
group_concat() 会计算哪些行属于同一组,将属于同一组的列显示出来。
UNIX_TIMESTAMP() mysql中表示当前时间戳
FROM_UNIXTIME() mysql中把时间戳转化成格式化时间
字符串函数:
concat(s1,s2,s3,...) --把传入的参数连接成为一个字符串。
select concat('aaa','bbb','ccc'),concat('aaa',null);任何字符串与 NULL 进行连接的结果都将是 NULL
INSERT(str ,x,y,instr) --将字符串 str 从第 x 位置开始,y 个字符长的子串替换为字符串 instr。
select insert('beijing2008you',12,3,'me')
LOWER(str)和 UPPER(str) --把字符串转换成小写或大写
select lower('BEIJING');select upper('beijing');
LEFT(str,x)和 RIGHT(str,x) --分别返回字符串最左边的 x 个字符和最右边的 x 个字符。
select left('qwertasd',1);select right('qwertasd',1);如果第二个参数是 NULL,那么将不返回任何字符串。
LPAD(str,n ,pad)和 RPAD(str,n ,pad) --用字符串 pad 对 str 最左边和最右边进行填充,直到长度为 n 个字符长度。
select lpad('2008',20,'beijing');select rpad('2008',20,'beijing')
LTRIM(str)和 RTRIM(str) --去掉字符串 str 左侧和右侧空格。
select ltrim(' |beijing');select rtrim('beijing| ');
REPEAT(str,x) --返回 str 重复 x 次的结果。
select repeat('mysql',3);
REPLACE(str,a,b) --用字符串 b 替换字符串 str 中所有出现的字符串 a。
select replace('beijing_2012','_2012','2008');
STRCMP(s1,s2) --比较字符串 s1 和 s2 的 ASCII 码值的大小。如果 s1 比 s2 小,那么返回-1;如果 s1 与 s2 相等,那么返回 0;如果 s1 比 s2 大,那么返回 1。
select strcmp('a','b'),strcmp('b','b'),strcmp('c','b');
TRIM(str) --去掉目标字符串的开头和结尾的空格。
select trim(' $ beijing2008 $ ');
SUBSTRING(str,x,y) --返回从字符串 str 中的第 x 位置起 y 个字符长度的字串。
select substring('beijing2008',8,4),substring('beijing2008',1,7);
数值函数:
ABS(x) --返回 x 的绝对值。
select abs(-0.8);
CEIL(x) --返回大于 x 的最大整数。
select ceil(-0.4);select ceil(0.4);
FLOOR(x) --返回小于 x 的最大整数,和 CEIL 的用法刚好相反。
select floor(0.4);
MOD(x,y) --返回 x/y 的模。和 x%y 的结果相同,模数和被模数任何一个为 NULL 结果都为 NULL。
select MOD(15,10),MOD(1,11),MOD(NULL,10);
RAND() --返回 0 到 1 内的随机值。每次执行结果都不一样。
select RAND(),RAND(); select ceil(100*rand()),ceil(100*rand());
"ROUND(x,y) --返回参数 x 的四舍五入的有 y 位小数的值。如果是整数,将会保留 y 位数量的 0;如果不写 y,则默认 y 为 0,即将 x 四舍五入后取整。
适合于将所有数字保留同样小数位的情况。"
select ROUND(1.1),ROUND(1.136,2),ROUND(1,2);
TRUNCATE(x,y) --返回数字 x 截断为 y 位小数的结果。
select ROUND(1.235,2),TRUNCATE(1.235,2);
日期和时间函数:
CURDATE() --返回当前日期,只包含年月日。
select CURDATE();
CURTIME() --返回当前时间,只包含时分秒。
select CURTIME();
NOW() --返回当前的日期和时间,年月日时分秒全都包含。
select NOW();
UNIX_TIMESTAMP(date) --返回日期 date 的 UNIX 时间戳。
select UNIX_TIMESTAMP(now());
FROM_UNIXTIME(unixtime) --返回UNIXTIME时间戳的日期值。
select FROM_UNIXTIME(1184134516);
WEEK(DATE)和 YEAR(DATE) --前者返回所给的日期是一年中的第几周,后者返回所
给的日期是哪一年。
select WEEK(now()),YEAR(now());
HOUR(time)和 MINUTE(time) --前者返回所给时间的小时,后者返回所给时间的分钟。
select HOUR(CURTIME()),MINUTE(CURTIME());
MONTHNAME(date) --返回 date 的英文月份名称。
select MONTHNAME(now());
DATE_FORMAT(date,fmt) --按字符串 fmt 格式化日期 date 值。
select DATE_FORMAT(now(),'%M,%D,%Y');
DATE_ADD(date,INTERVAL expr type) --返回与所给日期 date 相差 INTERVAL 时间段的日期。
select now() current,date_add(now(),INTERVAL 31 day) after31days,date_add(now(),INTERVAL '1_2' year_month) after_oneyear_twomonth;"
DATEDIFF(date1,date2) --用来计算两个日期之间相差的天数。
select DATEDIFF('2008-08-08',now());
流程函数:
IF(value,t f) --如果 value 是真,返回 t;否则返回 f。
select if(salary>2000,'high','low') from salary;
IFNULL(value1,value2) --如果 value1 不为空返回 value1,否则返回 value2。
select ifnull(salary,0) from salary;
CASE WHEN [value1] THEN[result1]…ELSE[default]END --如果 value1 是真,返回 result1,否则返回 default。
select case when salary<=2000 then 'low' else 'high' end from salary;
CASE [expr] WHEN [value1] THEN[result1]…ELSE[default]END --如果 expr 等于 value1,返回 result1,否则返回 default。
select case salary when 1000 then 'low' when 2000 then 'mid' else 'high' end from salary;
其他函数:
DATABASE() --返回当前数据库名。
VERSION() --返回当前数据库版本。
USER() --返回当前登录用户名。
INET_ATON(IP) --返回 IP 地址的网络字节序表示。
INET_NTOA(num) --返回网络字节序代表的 IP 地址。
PASSWORD(str) --返回字符串 str 的加密版本,一个 41 位长的字符串。(只可用于密码)
MD5(str) --返回字符串 str 的 MD5 值,常用来对应用中的数据进行加密。
五、位运算:(将十进制数转化为二进制,再一位一位的比较)
select 6&1 ===》0110&0001 = 0000 = 0; select 6&2 ===》0110&0010 = 0010 = 1; select 8|4 ===》1000|0100 = 1100 = 12; select 12|4 ===》1100|0100 = 1100 = 12; select 12^4 ===》1100^100 = 1000 = 8; select 2^3 ===》10^11 = 01 = 1; select 100>>3 ===>1100100右移3位,左边补零 = 1100 = 12; select 100<<3 ===>1100100左移3位,右边补零 = 1100100000 = 800;
六、PDO应用
1.停止
exit("hello");//输出hello,下面内容停止执行。类似于return fasle
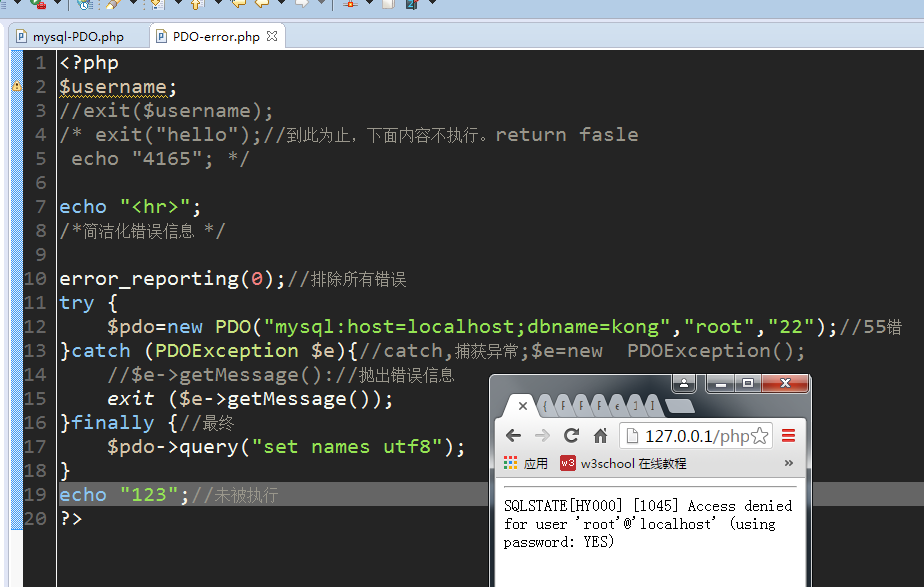
2.简洁化错误信息
error_reporting(0);//排除所有错误 exit ($e->getMessage());抛出错误信息,并停止执行下面内容 (PDOException $e){//catch,捕获异常;$e=new PDOException();
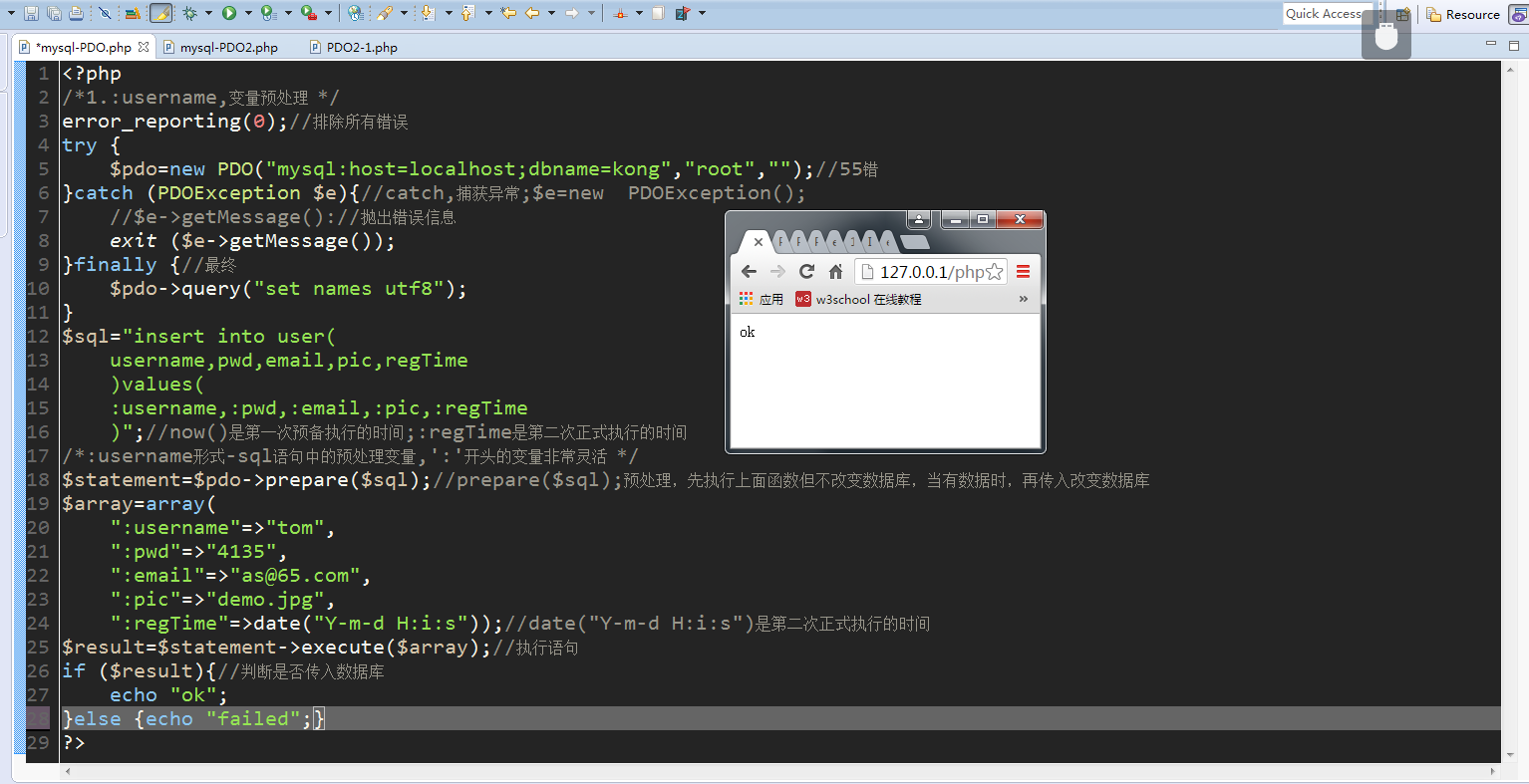
3.变量的预处理:执行两次,先执行上面没有参数的函数但不改变数据库,当有数据时,再传入改变数据库。更加灵活,减少服务器负担
:username方式 :username形式-sql语句中的预处理变量,':'开头的变量非常灵活 now()是第一次预备执行的时间;:regTime是第二次正式执行的时间 prepare($sql);预处理 execute($array);执行,运行的是int类型 ?方式:有顺序问题,可直接传值或参数,同样执行两次 bindValue();绑定值 bindParam();绑定参数,需先创建变量
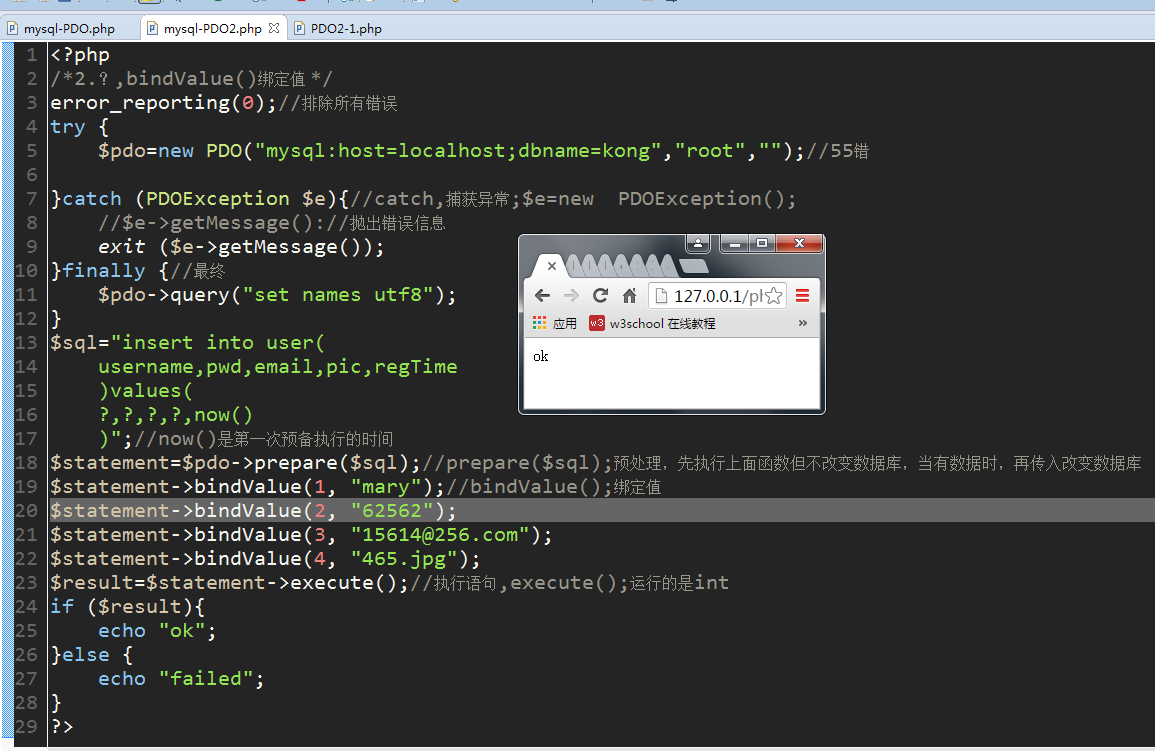
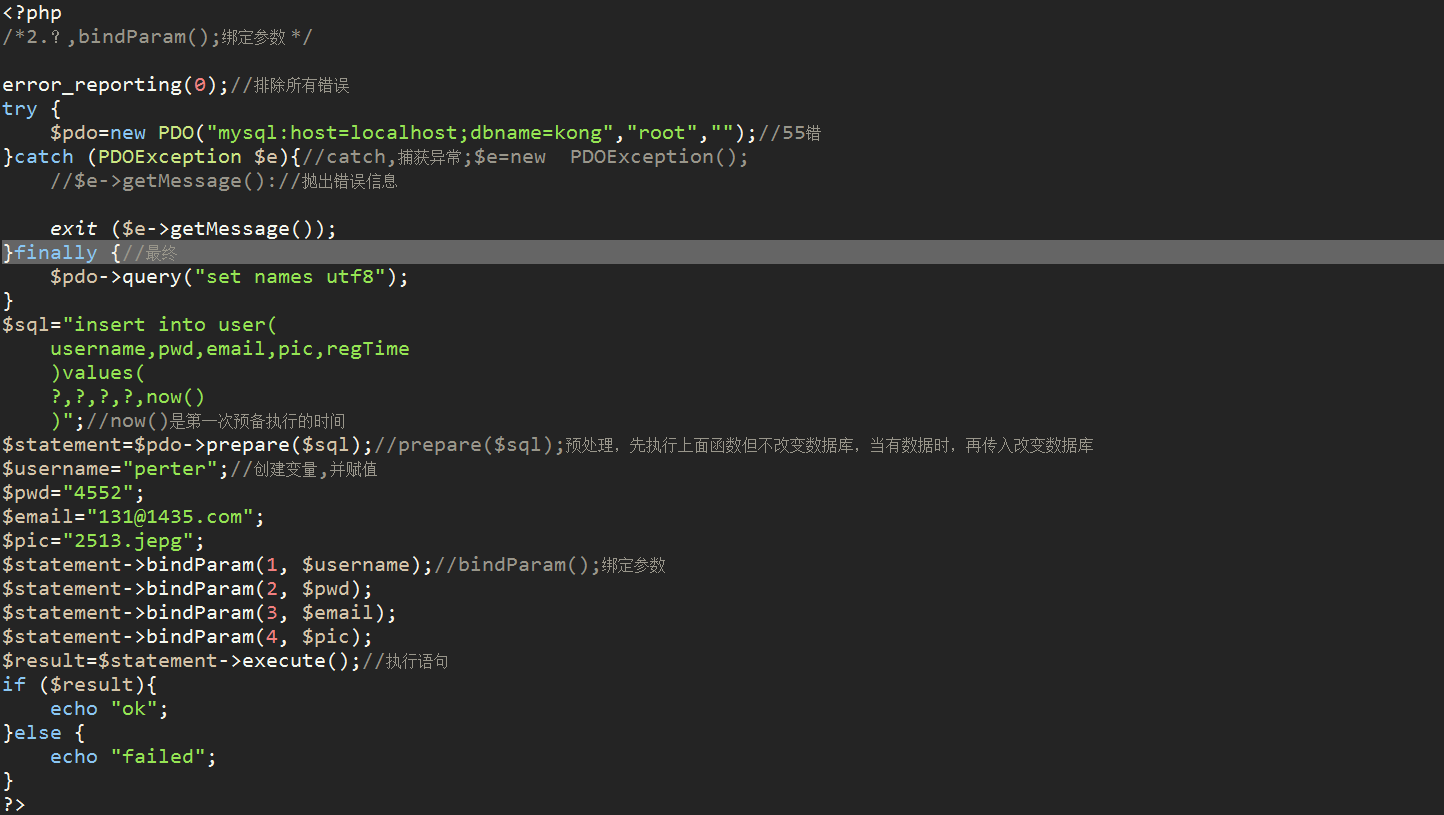
4.pdo的执行事务(transaction):作为一个单元的一组有序的数据库操作。
先禁止‘0’pdo的自动影响数据库 $pdo->setAttribute(PDO::ATTR_AUTOCOMMIT, 0); 再开启交易$pdo->beginTransaction(); 执行交易;$pdo->exec($sql); 如果出错,回滚(回到交易的开始状态)$pdo->rollBack(); 手动影响数据库$pdo->commit();
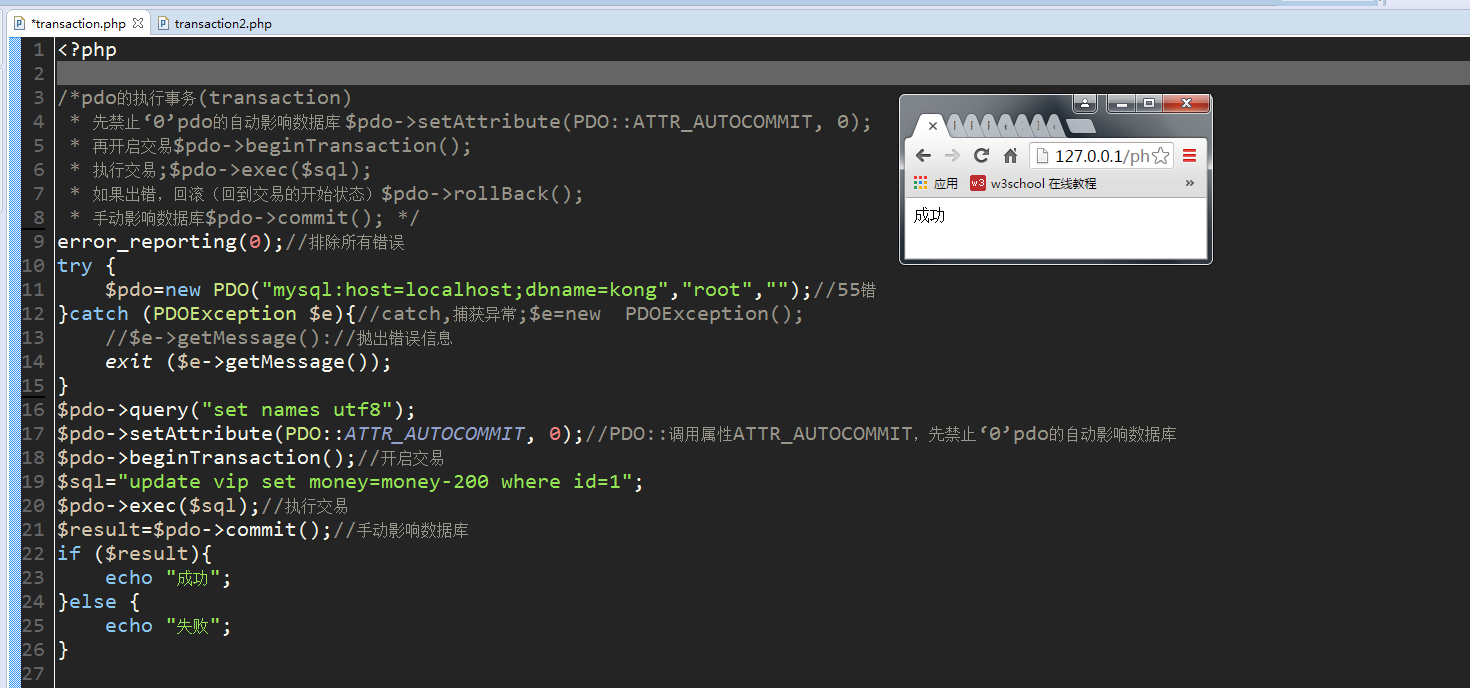
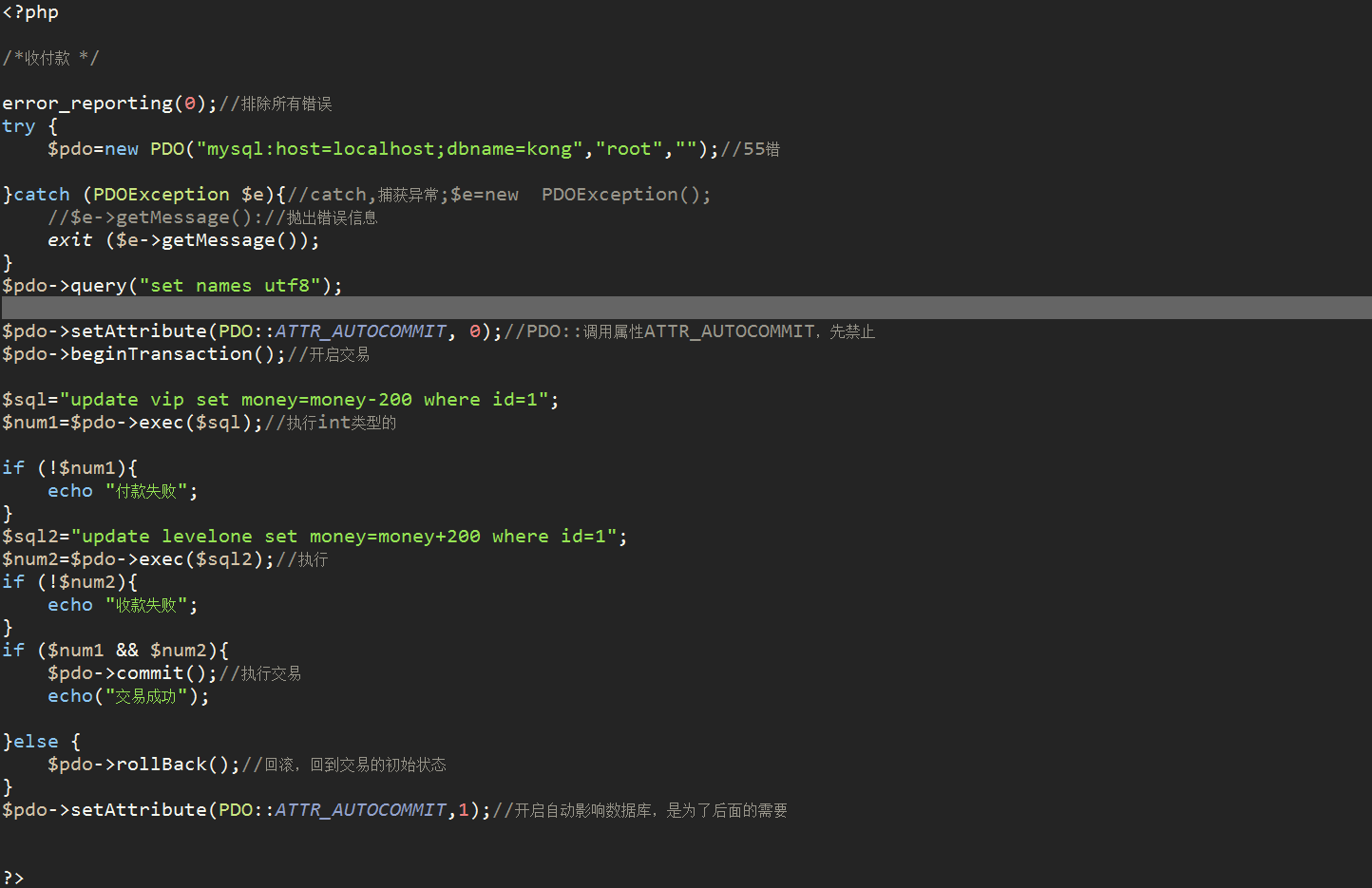
一个事务的小实例,收付款
之前都是放在excel文件中,每次用就添加一些,所以有点多。
但是有的时候不用了,岂不是就忘了!?所以还是做好记录比较好。
耐心、耐心、耐心,耐心就好