一种使用CNN来提取特征的模型,通过CNN的filter的大小来获得不同的n-gram的信息,模型的结构如下所示:
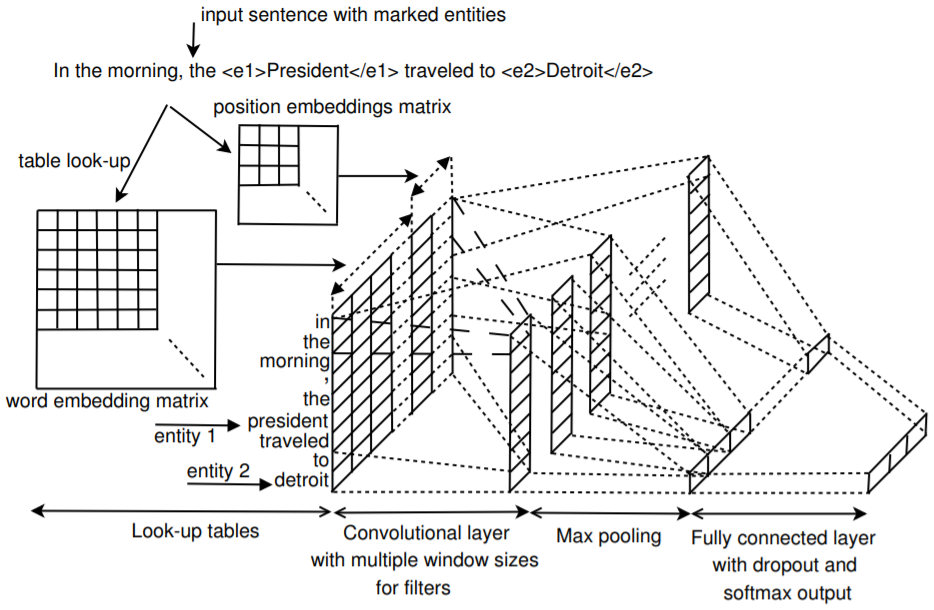
输入
输入使用word2vec的50维词向量,加上 position embedding。 position embedding 是一句话的每个单词距离两个entity的距离,比如:
In the morning, the <e1>President</e1> traveled to <e2>Detroit</e2>
句子的长度为n,那么对于第i个单词,他的distance就是i-n, 所以distance的范围是 -n + 1 ~ n -1,position embedding是一个 ((2n-1) * m_d) 的矩阵,(m_d)是embedding的维度。一句话中有两个entity,所以每个单词要计算两次distance。最后将word embedding 、position embedding拼接起来作为模型的输入,输入数据的shape是 ((m_e + 2m_d) * n), (m_e)是embedding的维度, (m_d)是 position embedding的维度。
卷积
采用多个卷积核捕获更多的特征。如果卷积核的大小是 w, 那么,会有权重矩阵 (mathbf{f}=left[mathbf{f}_{1}, mathbf{f}_{2}, ldots, mathbf{f}_{w} ight]), f是卷积核,(f_i)是大小和(x_i)一致的weight。
模型中会有多个不同大小的卷积核, 每种卷积核最后会经过max pooling,最后得到的向量再输入到linear层中
s是一个大小为w的卷积核在一句话上经过卷积得到的各个位置的score, 池化操作就是找到这句话中的最大的score。往往同样大小的卷积核会有n个,那么这些卷积核的池化结果就是长度为n的张量。也就是输出的size是(batch, n),如果有m种大小不同的卷积核,则把所有卷积核的输出拼到一起。也就是(batch, n * m)
分类
最后接入到全连接层进行分类