DMA适用于
- 本地SQLServer向Azure SQL Database迁移
- 两台不同的数据库服务器之间迁移
- 高版本->低版本 或 低版本->高版本
本文以两台不同服务器的低版本(SQLServer 2014)转向高版本(SQLServer 2019)
点此下载安装DMA。注意,建议DMA不要安装在SQLServer所在主机上,否则后续共享文件设置可能有问题。建议安装在自己的客户端电脑上
PS:一般低版本升级到高版本基本不会有兼容问题,但是高版本降级到低版本就得先运行评估(Assessment)。具体操作比迁移简单太多了,按提示写,没啥坑的。最后评估会给你结果这样迁移是否可行,有问题也会具体指出的。
设置共享文件夹
在需要进行迁移的两台服务器上都设置一个共享文件夹,用来拷贝数据库备份文件。
随便找个盘新建文件夹,随便命名,我是命名为share,然后右键属性,共享。添加Everyone读写则是允许匿名访问
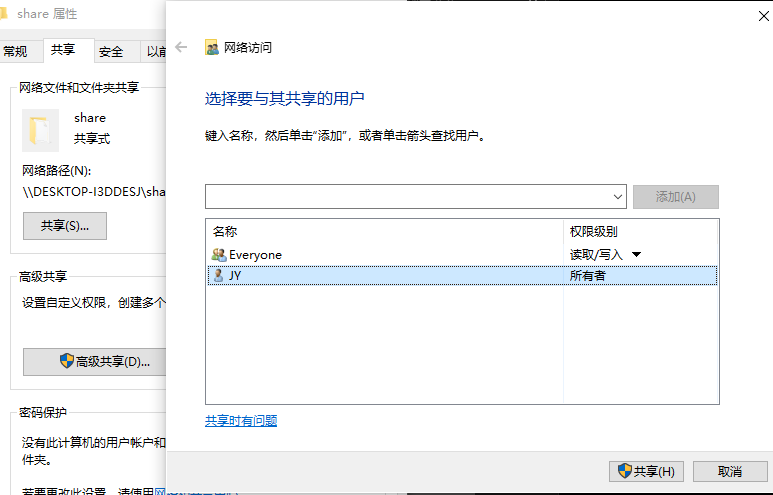
然后在自己电脑打开网络路径,确保能正常访问。
在源服务器和目标服务器上都创建和共享这么个文件夹,记录下网络路径,稍后会用到。
等迁移结束了就可以把这俩文件夹删了
开始迁移
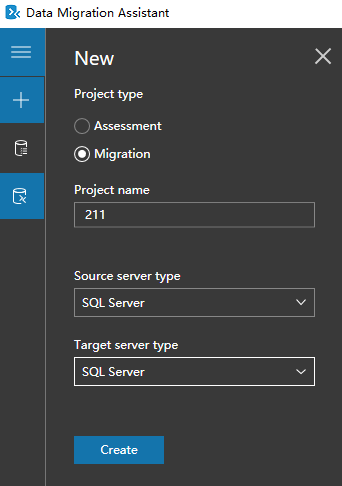
安装完毕点击+号,选择迁移(Migration),随便输入个项目名(Project name)
然后源服务器类型(Source server type)和目标服务器类型(Target server type)都选择SQL Server,最后点击创建(Create)
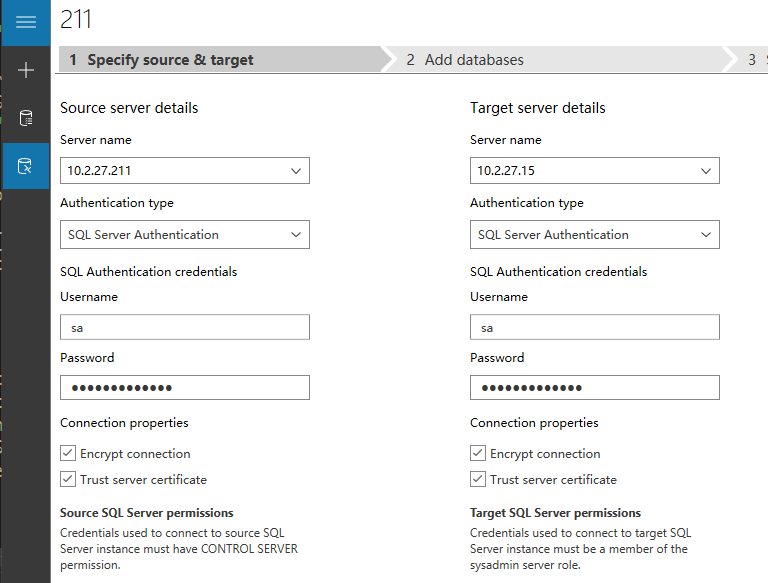
左边是源服务器信息,右边是目标服务器信息。
分别填如服务器名称或IP(server name),验证方式(Authentication type)选SQLServer 验证,输入sqlserver用户名和密码,加密连接(Encrypt connect)可以不勾,但信任服务器证书(Trust server certificate)一定要勾。然后点击下一步(Next)
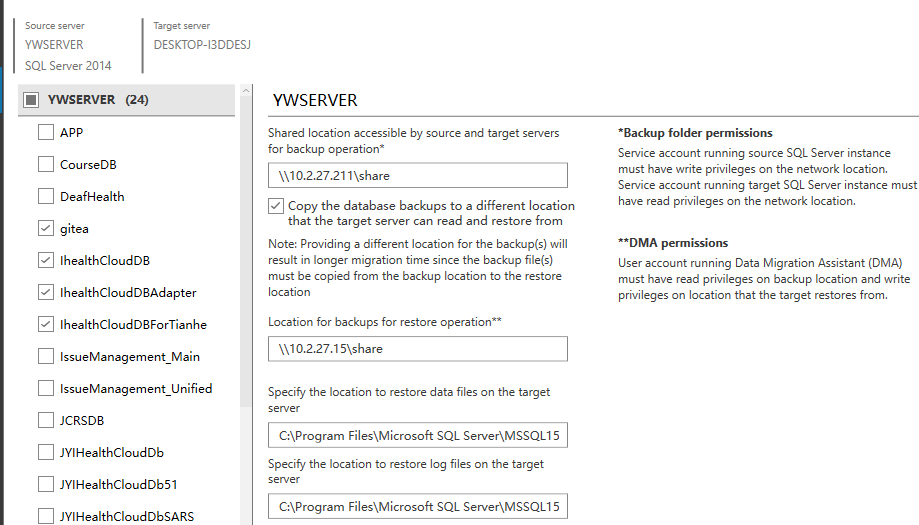
重头戏来了。左边勾选需要进行迁移的数据库。第一个输入框里填源服务器的共享网络路径,勾选从不通地方复制备份文件(Copy the database backups to...)就会出第二个输入框,还原操作的路径(Location for backups for restore operation),填入目标服务器的共享路径。
下边两个是mdf文件和ldf文件存放的路径,可以修改。
如果点击左边源服务器名字的,就是选数据库的上方那里,则右边设置是全局生效的。如果点击指定数据库名,则设置是对指定数据库生效的。所以如果不同数据库的存放路径不同的话可以单独进行设置。然后点击下一步(Next)
选择要同步的登录名(Login)。这个就酌情选择了。所以这个工具可以用来只同步登录名。点击开始迁移(Start Migration)就正式开始迁移了

几分钟后
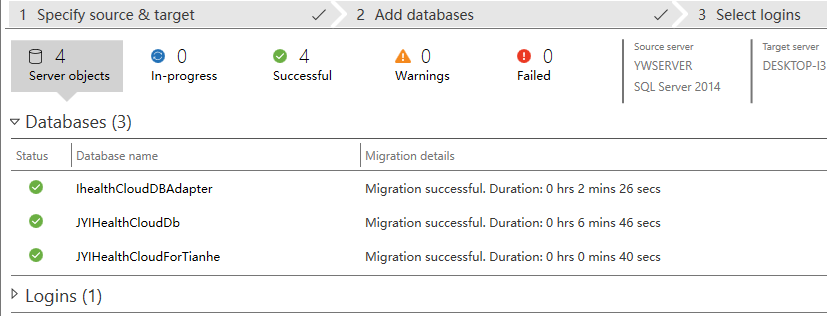
中间耗时6min 46s的那个数据库是20G+
哎呀,千兆网络就是快(逃
迁移完了记得要取消共享,删除文件夹哦