一、安装 scrapy
pip install scrapy
二、创建项目
scrapy startproject myproject
三、生成爬虫类
cd myproject
scrapy genspider baidu baidu.com
四、创建数据对象
修改 items.py,增加以下内容
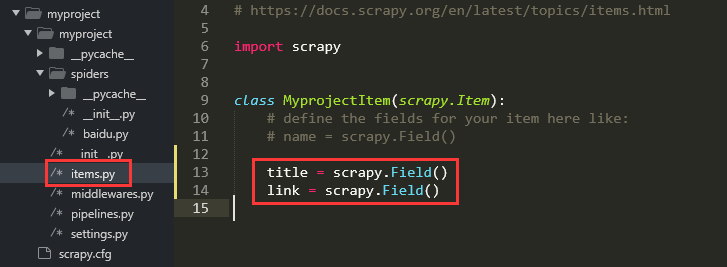
五、编写爬虫脚本
修改第三步生成的 baidu.py,编写处理响应数据的代码
import scrapy from myproject.items import MyprojectItem class BaiduSpider(scrapy.Spider): name = 'baidu' allowed_domains = ['baidu.com'] start_urls = ['http://baidu.com/'] def parse(self, response): hotsearch = response.css('.hotsearch-item') for li in hotsearch: item = MyprojectItem() item['name'] = li.css('.title-content-title::text').get() item['link'] = li.css('a::attr(href)').get() yield item
六、禁用 robots 规则

七、运行爬虫
scrapy crawl baidu -o hotsearch.csv
八、新建命令脚本
from scrapy import cmdline cmdline.execute('scrapy crawl baidu -o hotsearch.csv'.split())
注:现在就可以直接使用 python baidu.py 来启动爬虫,免去手动传参
九、集成 Selenium 中间件
import time import requests from pathlib import Path from selenium import webdriver from scrapy.http.response.html import HtmlResponse class SeleniumMiddlewares(object): def __init__(self): print('初始化浏览器') _driver = Path('./../drivers/chromedriver.exe') if _driver.exists() is False: print('异常:未找到浏览器驱动') print('提示:请下载对应版本的浏览器驱动,并放置于 %s/ 目录中' % str(_driver.parent)) print('chrome: https://chromedriver.storage.googleapis.com/index.html') return options = webdriver.ChromeOptions() options.add_argument('log-level=3') options.add_argument('--disable-blink-features') options.add_argument('--disable-blink-features=AutomationControlled') options.add_experimental_option('excludeSwitches', ['enable-logging', 'enable-automation']) options.add_experimental_option('useAutomationExtension', False) # proxy_url = requests.get('http://webapi.http.zhimacangku.com/getip?num=1&type=1&pro=&city=0&yys=0&port=1&pack=99172&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions=').text # print(proxy_url) # options.add_argument('--proxy-server=%s' % proxy_url) # 添加代理 self.driver = webdriver.Chrome(options=options, executable_path=str(_driver)) self.driver.maximize_window() def process_request(self, request, spider): self.driver.get(request.url) time.sleep(5) # 我们等待5秒钟,让其加载 source = self.driver.page_source # 获取页面的源码 # Response 对象用来描述一个HTTP响应 response = HtmlResponse(url=self.driver.current_url, body=source, request=request, encoding='utf-8') return response
十、官方文档
Command line tool — Scrapy 2.6.1 documentation
Items — Scrapy 2.6.1 documentation
Selectors — Scrapy 2.6.1 documentation