索引
创建并使用正确的索引【减少数据访问】
优点:加快检索速度、唯一索引保证每条数据唯一性等等,对生产系统的性能有质的提升;
缺点:索引会大大增加表记录的DML开销;
拓展:索引对DML(INSERT,UPDATE,DELETE)附加的开销有多少?
这个没有固定的比例,与每个表记录的大小及索引字段大小密切相关,以下是一个普通表测试数据,仅供参考:
索引对于Insert性能降低56%
索引对于Update性能降低47%
索引对于Delete性能降低29%
因此对于写IO压力比较大的系统,表的索引需要仔细评估必要性,另外索引也会占用一定的存储空间。
正确的索引可以让性能提升100,1000倍以上,不合理的索引也可能会让性能下降100倍,因此在一个表中创建什么样的索引需要平衡各种业务需求。
类别
主键索引(聚集索引)、唯一索引、普通索引、组合索引、全文索引
主键索引(聚集索引):primary key
例子:
ALTER TABLE `test_a` ADD INDEX `primary_key` (`id` ASC);
唯一索引:unique index
例子:
create unique index name_season_unique on test_a(name, season);
或者:
ALTER TABLE `test_a` ADD UNIQUE INDEX `name_season_unique` (`name` ASC, `season` ASC);
建议:尽量不用UNIQUE,由程序保证约束
普通索引:index
常用于
- 搜索时经常使用到的字段
- 用于连接其它表的字段
- 用于外键字段
- 高选中性的字段
- order by子句中使用到的字段
- xml类型
不适用于:
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件,例如性别
更新非常频繁的字段不适合创建索引,例如登录次数,最后登录时间
不会出现在 where 子句中的字段不该创建索引
例子:
create index name_index on test_a(name);
或者:
ALTER TABLE `test_a` ADD INDEX `name_index` (`name` ASC);
组合索引(也叫复合索引、多列索引)
类似于普通索引,只是索引是放在多个列名上,例如字典表中部首+笔画的组合索引
create index name_no_index on test_a(name, season);
全文索引:fulltext index
create fulltext index name_fulltext_index on test_a(name); -- 创建用于展示效果的数据 INSERT INTO `test_a` (`id`, `name`, `season`) VALUES ('6', '不知水果', '不知季度'); -- 展示效果 select match(name) against('不知水果') from test_a where id in(1, 6); drop index name_fulltext_index on test_a;
0表示没有匹配到,或者你的词是停止词,是不会建立索引的.
使用全文索引,不能使用like语句,如果使用like这样就不会使用到全文索引了
在建表的时候建立唯一键、普通索引、唯一索引的方式如下:
PRIMARY KEY (`id`), UNIQUE KEY `name_season_unique` (`name`,`season`), KEY `name_index` (`name`)
拓展:
删除索引
DROP INDEX index_name ON table_name;
或者:
ALTER TABLE `table_name` DROP INDEX `index_name`;
查看索引:
show index from table_name;
修改索引
我们一般是先删除再重新创建,也可以直接进行修改
索引注意点
- 索引并不是越多越好,要根据查询有针对性的创建,考虑在WHERE和ORDER BY命令上涉及的列建立索引,可根据EXPLAIN来查看是否用了索引还是全表扫描
- 应尽量避免在WHERE子句中对字段进行NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描
- 值分布很稀少的字段不适合建索引,例如”性别”这种只有两三个值的字段
- 字符字段只建前缀索引
- 字符字段最好不要做主键
- 不用外键,由程序保证约束
- 使用多列索引时主意顺序和查询条件保持一致,同时删除不必要的单列索引
- 查询要建立索引最重要的条件是查询条件中需要使用索引
- 如果MySQL估计使用全表扫描要比使用索引快,则不使用索引
SQL什么条件会使用索引?
当字段上建有索引时,通常以下情况会使用索引:
- INDEX_COLUMN = ?
- INDEX_COLUMN > ?
- INDEX_COLUMN >= ?
- INDEX_COLUMN < ?
- INDEX_COLUMN <= ?
- INDEX_COLUMN between ? and ?
- INDEX_COLUMN in (?,?,...,?)
- INDEX_COLUMN like ?||'%'(后导模糊查询)
- T1. INDEX_COLUMN=T2. COLUMN1(两个表通过索引字段关联)
SQL什么条件建了索引但不会使用索引?
|
查询条件 |
不能使用索引原因 |
示例 |
|
INDEX_COLUMN <> ? INDEX_COLUMN not in (?,?,...,?) |
不等于操作不能使用索引 |
|
|
function(INDEX_COLUMN) = ? INDEX_COLUMN + 1 = ? INDEX_COLUMN || 'a' = ? |
经过普通运算或函数运算后的索引字段不能使用索引 |
|
|
INDEX_COLUMN like '%'||? INDEX_COLUMN like '%'||?||'%' |
含前导模糊查询的Like语法不能使用索引 |
对于使用like的查询,'aaa%' 会使用到索引,查询如果是'%aaa'不会使用到索引。 explain select * from dept where name like '研发部%'; -- 不会使用索引 explain select * from dept where name like '%研发部'; |
|
INDEX_COLUMN is null |
B-TREE索引里不保存字段为NULL值记录,因此IS NULL不能使用索引 |
|
|
NUMBER_INDEX_COLUMN='12345' CHAR_INDEX_COLUMN=12345 |
在做数值比较时需要将两边的数据转换成同一种数据类型,如果两边数据类型不同时会对字段值隐式转换,相当于加了一层函数处理,所以不能使用索引。 |
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。(添加时,字符串必须'') -- 会应用索引 explain select * from dept where name = '研发部'; -- 不会使用索引并且报错 explain select * from dept where name = 研发部; |
|
a.INDEX_COLUMN=a.COLUMN_1 |
给索引查询的值应是已知数据,不能是未知字段值。 |
|
|
对于创建的组合索引,只要查询条件使用了最左边的列,索引一般就会被使用,不是使用的第一部分,则不会使用索引 |
组合索引都是从第一个字段开始找起,看第一个条件字段是否是组合索引的第一个字段,如果是则使用索引,否则不使用 |
alter table dept add index name_loc (name, loc); explain select * from dept where name = '研发部'; explain select * from dept where name = '研发部' and loc = '大厦10楼1001'; -- 不会使用索引 explain select * from dept where loc = '大厦10楼1001'; |
|
如果条件中有or,即使其中有条件带索引也不会使用。 |
-- 我们把组合索引删除,然后只在name上加入索引 alter table dept drop index name_loc; alter table dept add index name_index (name); -- 使用了索引 explain select * from dept where name = '研发部'; -- key为NULL explain select * from dept where name = '研发部' or loc = '大厦10楼1001'; |
|
|
注: 经过函数运算的字段要使用索引可以使用函数索引,这种需求建议与DBA沟通。 |
||
我们一般在什么字段上建索引?
这是一个非常复杂的话题,需要对业务及数据充分分析后再能得出结果。主键及外键通常都要有索引,其它需要建索引的字段应满足以下条件:
1、字段出现在查询条件中,并且查询条件可以使用索引;
2、语句执行频率高,一天会有几千次以上;
3、通过字段条件可筛选的记录集很小,那数据筛选比例是多少才适合?
这个没有固定值,需要根据表数据量来评估,以下是经验公式,可用于快速评估:
小表(记录数小于10000行的表):筛选比例<10%;
大表:(筛选返回记录数)<(表总记录数*单条记录长度)/10000/16
单条记录长度≈字段平均内容长度之和+字段数*2
例如:emp表中有600万的数据,单条记录长度 ≈ (7+6+6+3+8+4+1+10+7+6) + 11 * 2 = 70
筛选返回记录数就需要小于 6000000 * 70 / 10000 / 16 = 3625 左右即可
在emp的name字段中添加了索引,查看索引筛选比例如下,351小于预期值3625,说明在这个字段上建立索引是非常合理的

如何知道SQL是否使用了正确的索引?
简单SQL可以根据索引使用语法规则判断,复杂的SQL不好办,判断SQL的响应时间是一种策略,但是这会受到数据量、主机负载及缓存等因素的影响,有时数据全在缓存里,可能全表访问的时间比索引访问时间还少。要准确知道索引是否正确使用,需要到数据库中查看SQL真实的执行计划。
只通过索引访问数据
有些时候,我们只是访问表中的几个字段,并且字段内容较少,我们可以为这几个字段单独建立一个组合索引,这样就可以直接只通过访问索引就能得到数据,一般索引占用的磁盘空间比表小很多,所以这种方式可以大大减少磁盘IO开销。
如:select id,name from company where type='2';
如果这个SQL经常使用,我们可以在type,id,name上创建组合索引
create index my_comb_index on company(type,id,name);
有了这个组合索引后,SQL就可以直接通过my_comb_index索引返回数据,不需要访问company表。
切记,性能优化是无止境的,当性能可以满足需求时即可,不要过度优化。在实际数据库中我们不可能把每个SQL请求的字段都建在索引里,所以这种只通过索引访问数据的方法一般只用于核心应用,也就是那种对核心表访问量最高且查询字段数据量很少的查询。
优化SQL执行计划
SQL执行计划是关系型数据库最核心的技术之一,它表示SQL执行时的数据访问算法。由于业务需求越来越复杂,表数据量也越来越大,程序员越来越懒惰,SQL也需要支持非常复杂的业务逻辑,但SQL的性能还需要提高,因此,优秀的关系型数据库除了需要支持复杂的SQL语法及更多函数外,还需要有一套优秀的算法库来提高SQL性能。
目前ORACLE有SQL执行计划的算法约300种,而且一直在增加,所以SQL执行计划是一个非常复杂的课题,一个普通DBA能掌握50种就很不错了,就算是资深DBA也不可能把每个执行计划的算法描述清楚。虽然有这么多种算法,但并不表示我们无法优化执行计划,因为我们常用的SQL执行计划算法也就十几个,如果一个程序员能把这十几个算法搞清楚,那就掌握了80%的SQL执行计划调优知识。
查看索引的使用情况
show status like 'Handler_read%';
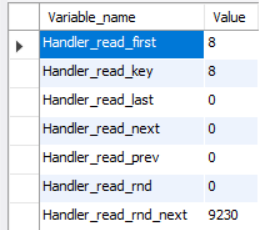
大家可以注意:
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询低效。
这时我们会看到handler_read_rnd_next值很高,这是因为我们前面没有加索引的时候,做过多次查询的原因.
定时清除不需要的数据,定时整理索引锁片
当创建了索引并且索引正常的工作,但性能仍然不好,那就可能是产生了索引碎片,需要进行索引碎片处理。
optimize table table_name;