NoSQL HBase day-1
NoSQL
1.1 概念
是一种非关系型数据库
创建一个数据是没有依赖关系(相当于没有主外键)
解决:
不考虑数据的大小进行查询
实现:
可伸缩性:通过增加硬件提高性能(需要有分割文件的功能)
就
为什么使用NoSQL?(优势)
1)高存储量 2)增加硬件提升性能 3)高效率的读写处理 4)数据间无关系,易于切割、扩展
额外的知识点:事务(ACID)
原则性:保证两个事件一起并发(相当于存钱取钱)
一致性:完成了一个成功的事务,数据应处于一致的状态
隔离性:每个事务都应表现为独立执行
持久性:一个被完成的事务的效果应该是持久的
特点
允许有一定的弱质性,最终达到一致性
基于hdfs的查询文件,存储文件效率更高
kafka:是一个相对于缓冲数据的系统
### NoSQL(基本概念)
三大基石:
基石-1 CAP: (数据库最多支持以下的两个)
1)Consistency(一致性):完成了一个成功的事务,数据应处于一致的状态
2)Availability(可用性):对于客户端的请求返回值
3)Partition Tolerance(分区容错性):一定要满足可以分区和切割
基石-2 base:
Basically Availble(基本可以):允许部分分区失效
Soft-state(软状态):状态可以有一段时间不同步
达到最终一致性
!!!HBase基于hdfs文件系统,他是一个实时的文件
!!!写入很快,读取很快
NoSQL(分类)
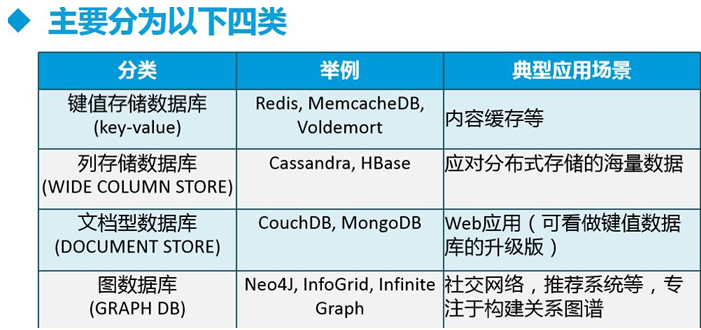
图数据库:点和点之间的关系
HBase(概述)
是一个面向列存储的数据库
他有读写的缓存,支持随机读写,
用zookeeper来保证他的安全性
HMaster的作用
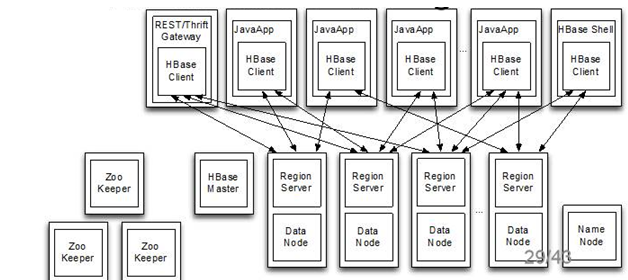
1)保证所有的RegionServer存储都差不多,
2)监控RegionServer保证数据不丢失
RegionServer
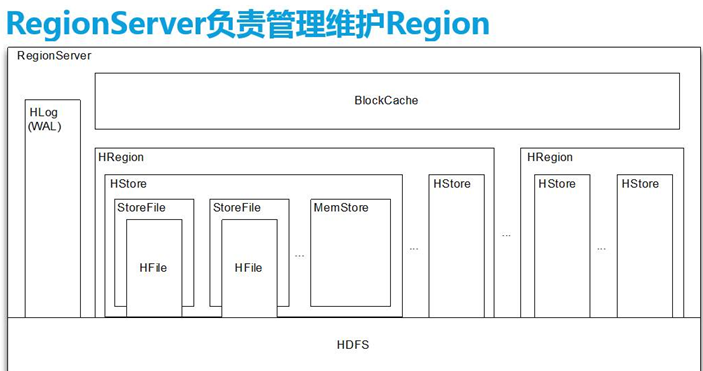
| menStore | 写缓存 |
|---|---|
| BlockCache | 读缓存 |
| HLog(WAL) | 相当于日志可以恢复和使用 |
先将数据存储在MenStore,溢出时会放入StoreFile
1)RegionServer存储不同的Region(Region:相对于startkey 和endkey)一个表当Region变大会发生自动分割生成下一个(region:存储一个列族)/
2)Region包含了多个存储区,每个存储区对应一个列族
3)master保证所有的RegionServer存储的均衡,监控RegionServer保证数据不丢失
4)zookeeper 帮助RegionServer选取master
思路二:
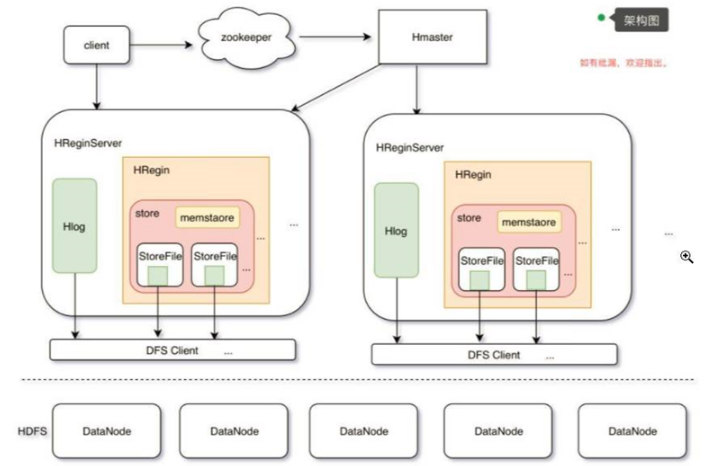
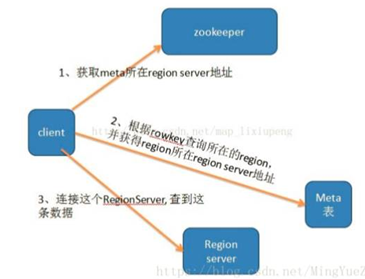
储存原始数据的地址在哪里
客户端找RegionServer而 Master会查询有没有空闲的RegionSercer,从而让他工作,找到region,
HBase逻辑架构-Row
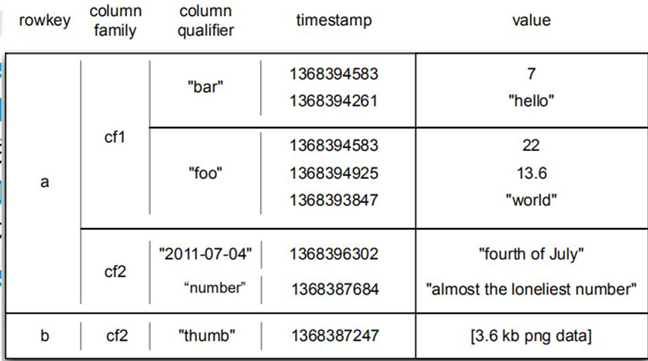
| “foo” | 列修饰符 |
|---|---|
| cf1 “foo” | 列键 |
| timestamp | 时间戳 |
| cf1 | 列族 |
rowkey+cf1+ “foo”+timestamp=value
列出所有的表:list
查看表:scan '表名' (hbase:meta 源数据表)
查找表格的命令:ls /hbase/table
找到元数据的region-server : get /habase/meta-region-server
!!!但我们再创建表格的时候如果指定了列族,及数据只可以添加到指定的列族中
create 'stu','info','info2'
插入数据下确定表名:put 'stu','rk001','info:name','jason'
create 'stu1',{NAME=>'info',VERSIONS=>'3'}
hbase zkcli
1)启动服务
在zookeeper中进入bin目录启动:./zkServer.sh start
2)启动客户端
zkCli.sh
启动:./ start-hbase.sh
再启动:hbase shell
启动hbase成功后: