C++11多线程简单使用
开篇介绍
C++11中引入了多线程头文件<thread>,让我们能更方便的使用多线程进行编程
void TestThread(int index)
{
std::cout << "Child Thread" << index << " id " << std::this_thread::get_id() << std::endl;
std::cout << "Child Thread" << index << "Stop" << std::endl;
}
int main()
{
std::thread newThread1(TestThread, 1);
std::thread newThread2(TestThread, 2);
std::cout << "Main Thread id " << std::this_thread::get_id() << std::endl;
std::cout << "Main Thread Stop" << std::endl;
if (newThread1.joinable())
newThread1.join();
if (newThread2.joinable())
newThread2.join();
}
众所周知,线程具有异步性,也就是说这道程序的推进的方向是不确定的,而事实也正是如此
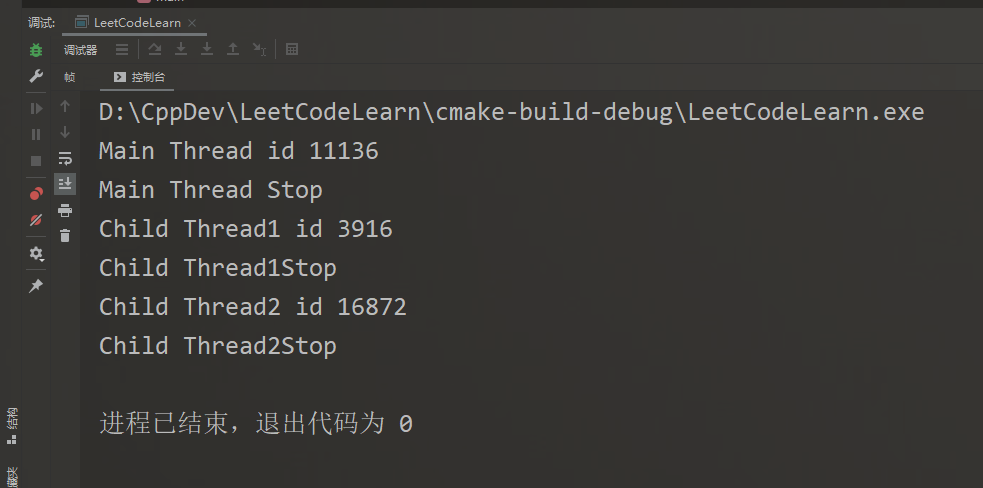
有两句话说得好,汇总一下就是:join()和detach()总要调用一个,并且调用之前最好是要进行joinable()检查
Never call join() or detach() on std::thread object with no associated executing thread
Never forget to call either join or detach on a std::thread object with associated executing thread
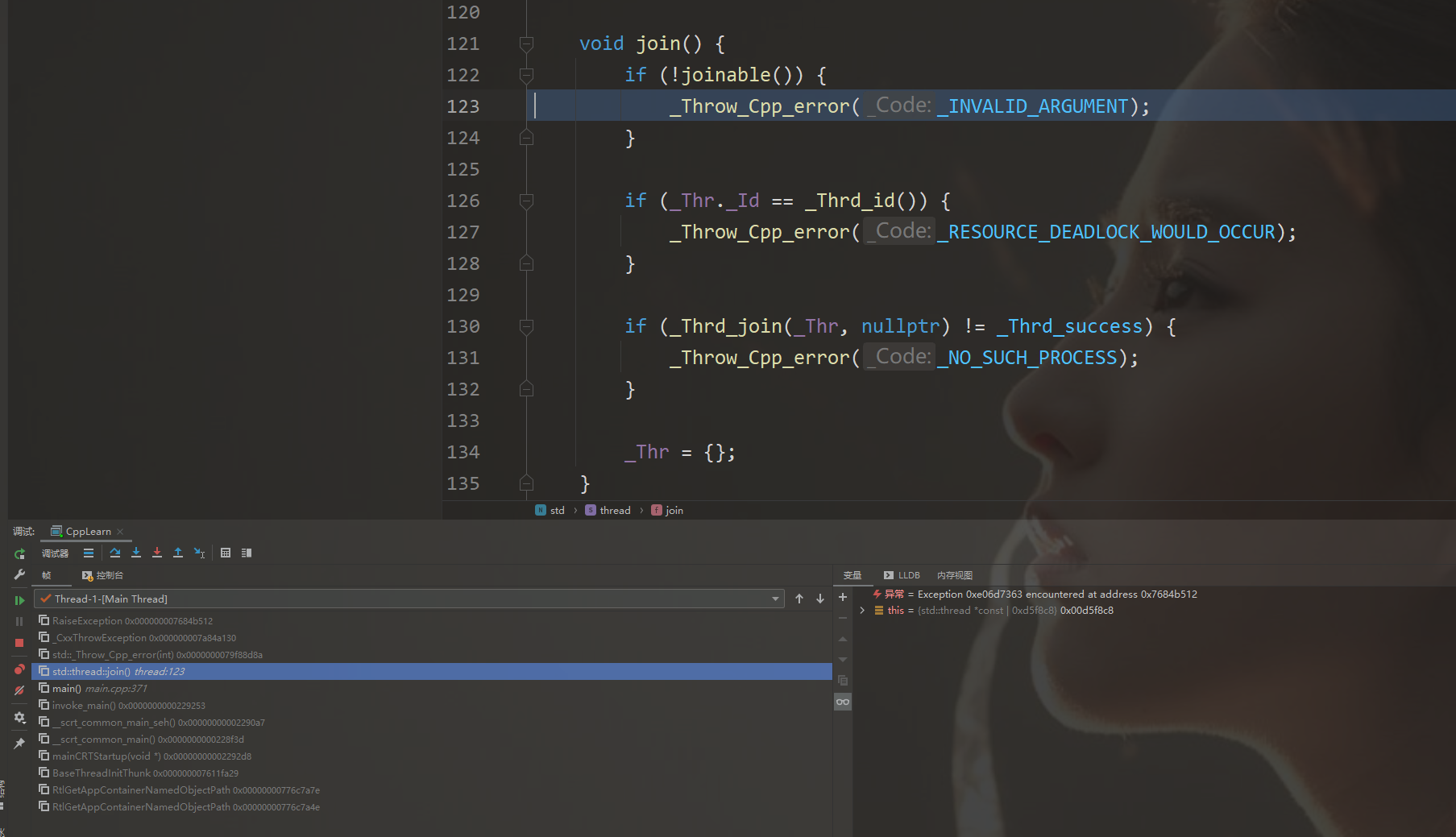
如果对一个子线程执行两次join()操作,那么会抛出异常
void TestThread(int index)
{
std::cout << "Child Thread" << index << " id " << std::this_thread::get_id() << std::endl;
std::cout << "Child Thread" << index << "Stop" << std::endl;
}
int main()
{
std::thread newThread(TestThread, 1);
newThread.join();
newThread.join();
}
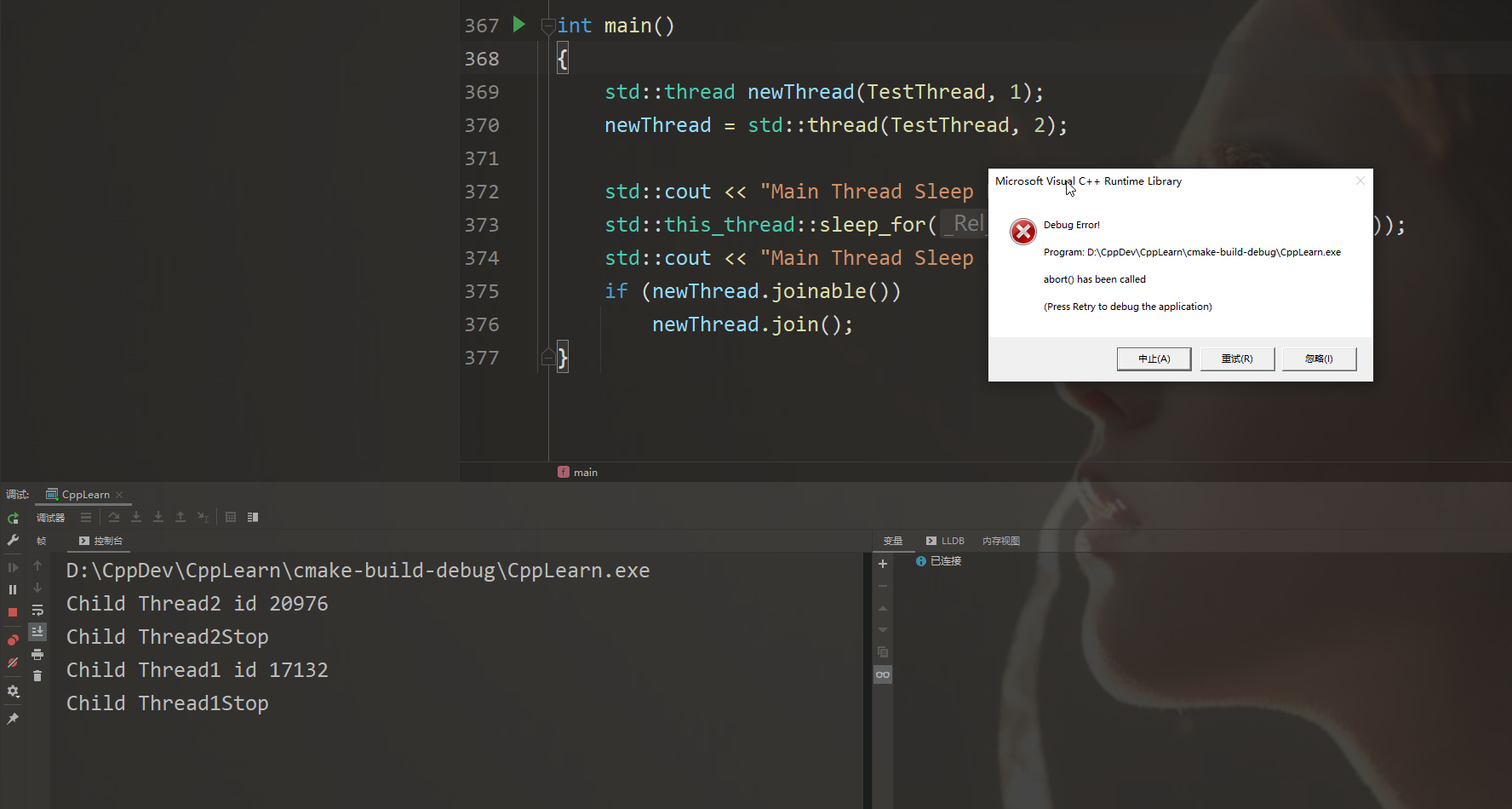
cppreference中提到,当joinable()的线程被赋值或析构的时候,会调用std::terminate(),而一般std::terminate()意味着std::abort(),也就是说如果对一个线程既不执行join()操作也不执行detach()操作,而它却被析构了,那么“it will cause the program to Terminate(终止)”

void TestThread(int index)
{
std::cout << "Child Thread" << index << " id " << std::this_thread::get_id() << std::endl;
std::cout << "Child Thread" << index << "Stop" << std::endl;
}
int main()
{
std::thread newThread(TestThread, 1);
newThread = std::thread(TestThread, 2);
std::cout << "Main Thread Sleep Begin" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << "Main Thread Sleep End" << std::endl;
if (newThread.joinable())
newThread.join();
}
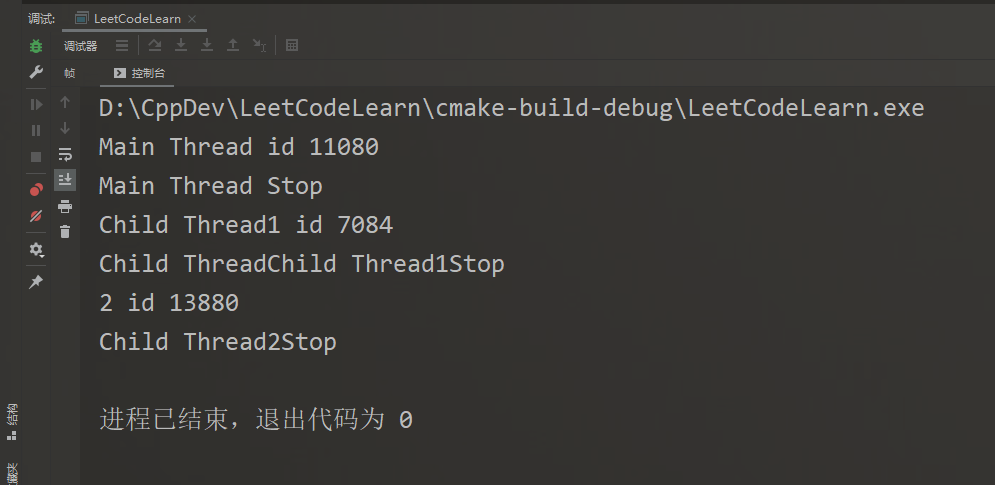
抛开Bug不谈,由于线程的异步性,谁也说不清是先输出Thread1还是输出Thread2
针对这个Bug,可以这么理解:线程1由对象newThread管理,当C++底层告知操作系统去创建一个新线程并给它分配一些任务后,却马上创建了一个线程2交给newThread,这样子产生了一个覆盖操作,导致线程1被析构,而它又是可结合的,所以程序被terminate
正确的做法是
int main()
{
std::thread newThread(TestThread, 1);
if (newThread.joinable())
newThread.join();
newThread = std::thread(TestThread, 2);
if (newThread.joinable())
newThread.join();
}
线程的构造
通过前文中的示范,我们了解到可以通过传入一个函数指针来给一个线程分配它的“任务”
除了函数指针外,还可以通过lambda表达式,std::function,std::bind,仿函数对象等来解决
struct Handle
{
void operator()(int data) { std::cout << data << std::endl; }
};
int main()
{
std::thread t(Handle(), 10);
if (t.joinable())
t.join();
}
join与detach
newThread.join()操作代表当前线程将阻塞,直到newThread完成它的任务newThread.detach()操作代表newThread与当前线程分开(即当前线程结束销毁后并不会同时销毁newThread),但是程序结束后newThread仍会被终止(即使它还没运行完,也会被操作系统强行叫停,这也可能会导致资源没有正确的释放)
class TestClass
{
public:
TestClass() { cout << "create" << endl; }
TestClass(const TestClass& t) { cout << "copy" << endl; }
void print(int num)
{
for (int i = 0; i < num; i++)
cout << i << ends;
cout << endl;
}
};
void Func2()
{
cout << "start" << endl;
TestClass t;
std::thread newThread(&TestClass::print, &t, 10);
// 让当前线程等待newThread完成
newThread.join();
cout << "end" << endl;
}
int main()
{
std::thread t(Func2);
if (t.joinable())
t.join();
return 0;
}
程序的执行结果为
void repeat1000(int index, int time)
{
for (int i = 0; i < time; i++)
cout << index;
}
void detach_test()
{
thread newThread(repeat1000, 1, 100000);
newThread.detach();
newThread = thread(repeat1000, 2, 1000);
newThread.join();
}
int main()
{
{
thread t(detach_test);
t.join();
}
cout << endl << "start wait" << endl;
this_thread::sleep_for(chrono::seconds(5));
return 0;
}
我认为这是一个很好的解释join()和detach()的例子,下面来分析一下
- 首先创建了线程
t,给它分配了detach_test()任务 - 主线程阻塞 等待
t完成它的任务 - 同时操作系统完成了对
t的分配,开始执行detach_test() t进程再创建子线程newThread,并给他分配(repeat1000, 1, 100000)任务- 操作系统在分配
newThread的“同时”,t线程将其和newThread分离 - 此时
(repeat1000, 1, 100000)仍然在运行,同时t线程给newThread赋了一个新线程,任务为(repeat1000, 2, 1000) newThread调用join()操作,t进程阻塞,等待newThread的(repeat1000, 2, 1000)工作完成newThread的(repeat1000, 2, 1000)完成,也意味着t进程的任务完成,此时主线程不再受到阻塞t线程离开作用域,遭到销毁。但此时(repeat1000, 1, 100000)操作因为比较耗时所以仍然还在运行- 主程序输出"start wait"后开始休眠5秒钟,此时线程
(repeat1000, 1, 100000)仍然在运行 - 最后程序结束,各种线程被操作系统销毁(即可能
(repeat1000, 1, 100000)执行到第八万次的时候就突然被终止了)
在一般情况下,为了避免detach或join使用不当造成的程序错误,可以创建一个线程类,使用析构函数执行线程的分离或合并(join)
线程传参时应该避免的操作
应该避免传入栈上对象的指针
void newThreadCallback(int* p)
{
std::cout << "Inside Thread: " << *p << std::endl;
// 等一秒钟 让startNewThread()执行结束 使i的内存空间被回收
std::this_thread::sleep_for(std::chrono::seconds(1));
// 抛出异常
*p = 19;
}
void startNewThread()
{
int i = 10;
std::cout << "Inside Main Thread: " << i << std::endl;
std::thread t(newThreadCallback, &i);
t.detach();
std::cout << "Inside Main Thread: " << i << std::endl;
}
int main()
{
startNewThread();
// 等两秒钟 让所有线程和方法都执行完毕再结束程序
std::this_thread::sleep_for(std::chrono::seconds(2));
return 0;
}
堆上的数据同理
因为一般堆对象需要使用delete来销毁,所以也无法确定别的线程访问到指针的时候,它所指的内存是否有效
线程的引用传参
使用std::ref或者std::cref,使用方法几乎和std::bind中使一致的,所以不再赘述
多线程中的竞争
操作系统应该学过,竞争就是多个线程同时访问一块内存区域,导致不可预估的结果
class Wallet
{
int money;
public:
Wallet() : money(0) {}
int getMoney() const { return money; }
void addMoney(int increase) {
for (int i = 0; i < increase; ++i)
money++;
}
};
int testMultiThreadWallet()
{
Wallet walletObject;
std::vector<std::thread> threads;
// 创建五条线程异步访问Wallet "理应"得到的结果为5000
threads.reserve(5);
// reserve对应_back而resize对应[i]
for (int i = 0; i < 5; ++i)
threads.emplace_back(&Wallet::addMoney, &walletObject, 1000);
// 等所有线程执行完再结束
for (auto& thread : threads)
thread.join();
return walletObject.getMoney();
}
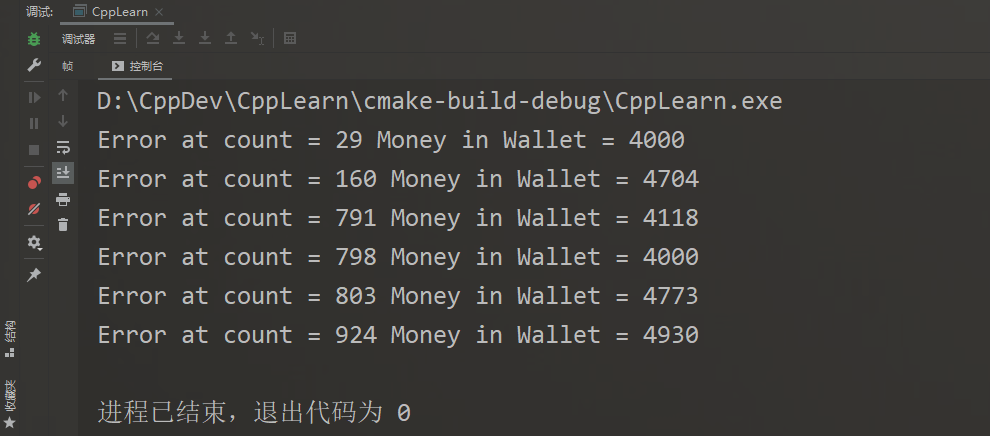
int main()
{
int val = 0;
for (int k = 0; k < 1000; k++)
if ((val = testMultiThreadWallet()) != 5000)
std::cout << "Error at count = " << k << " Money in Wallet = " << val << std::endl;
return 0;
}
某次程序执行的结果为,这种结果是不确定的,可能1000次实验,一次都不会出错,也可能出现多至十多次错误
这一行短短的代码其实发生了三件事
money++;
- 将
money的值加载进寄存器中 - 在寄存器中进行计算,即++操作
- 将寄存器中的结果存回
money所在的内存中
而当由于线程具有异步性,在不加锁的情况下我们无法控制多条线程对money的访问顺序,那么就可能出现以下这种情况

- 假设money的初始值是43
- money的值被线程1取出放入寄存器1中
- money的值被线程2取出放入寄存器2中
- 寄存器1进行计算得到结果44
- 寄存器2进行计算得到结果44
- 寄存器1将结果放入money所在内存中,money为44
- 寄存器2将结果放入money所在内存中,money为44
解决线程中的竞争
操作系统中的PV操作与之类似,关键就是加锁
std::mutex
使用互斥锁解锁上文中的钱包问题
#include<mutex>
class Wallet
{
int money;
mutex mutexLock;
public:
Wallet() : money(0) {}
int getMoney() const { return money; }
void addMoney(int increase) {
mutexLock.lock();
for (int i = 0; i < increase; ++i)
money++;
mutexLock.unlock();
}
};
但是如果一个线程在加锁后并没有解锁,那么所有其他线程将会一直等待,导致程序无法结束(当使用join的情况下)
相反的,如果没上锁就解锁
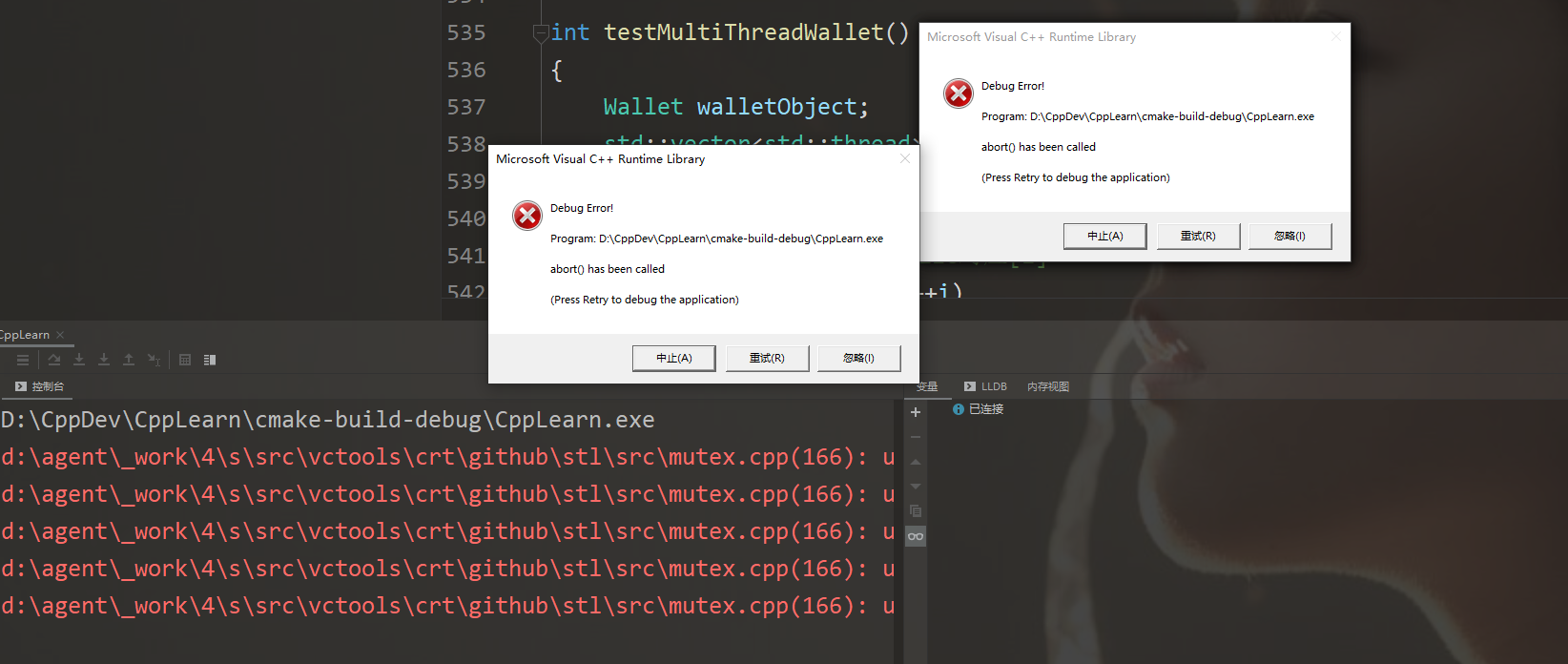
因此可以在此基础上做一层简单的封装
class SmartMutex
{
private:
mutex mutexLock;
public:
void AutoLock(const function<void()>& func)
{
mutexLock.lock();
func();
mutexLock.unlock();
}
};
class Wallet
{
int money;
SmartMutex smartMutex;
public:
Wallet() : money(0) {}
int getMoney() const { return money; }
void addMoney(int increase)
{
smartMutex.AutoLock([this, &increase]() {
for (int i = 0; i < increase; ++i)
this->money++;
});
}
};
或者可以使用std::lock_guard
std::lock_guard
std::lock_guard有点像一个智能指针,在它的作用域结束后,会调用析构函数,完成对互斥锁的解锁操作
class Wallet
{
int money;
mutex mutexLock;
public:
Wallet() : money(0) {}
int getMoney() const { return money; }
void addMoney(int increase)
{
// 在lockGuard的构造函数中会自动上锁
lock_guard<mutex> lockGuard(mutexLock);
for (int i = 0; i < increase; ++i)
this->money++;
// 离开作用域 lockGuard析构函数调用 自动解锁
}
};
线程同步
操作系统中又学习过,进程1和进程2可以并行处理某些任务,但是进程2的继续推进可能需要依赖进程1生产出一些资源。即
void p1() {
// create something
V();
}
void p2() {
P();
// do something;
}
全局bool变量法
下面使用一个全局的bool变量来模拟线程同步
class TestThreadSynchronization
{
private:
mutex mutexLock;
bool isFinished;
public:
TestThreadSynchronization() : isFinished(false) {}
void createResource()
{
// 模拟生产资源花费2秒钟
cout << "creating resources" << endl;
this_thread::sleep_for(chrono::seconds(2));
lock_guard<mutex> lockGuard(mutexLock);
cout << "create done" << endl;
isFinished = true;
}
void mainWork()
{
// 模拟做某些事情花费1秒钟
cout << "doing main work" << endl;
this_thread::sleep_for(chrono::seconds(1));
// 进入等待状态 等待"资源"产出
mutexLock.lock();
while (isFinished == false)
{
mutexLock.unlock();
// 给别的线程留时间改写
this_thread::sleep_for(chrono::milliseconds(100));
mutexLock.lock();
}
mutexLock.unlock();
cout << "using new create resource to do something" << endl; }
};
int main()
{
TestThreadSynchronization t;
thread t1(&TestThreadSynchronization::mainWork, &t);
thread t2(&TestThreadSynchronization::createResource, &t);
t1.join();
t2.join();
}
这样的写法很不优美,在mainWork()中为了访问一个变量而重复上锁解锁,同时还需要给别的线程留下100ms时间来改写变量(虽然可以不用等待,但是为了保险起见)。这样的方式不仅维护起来困难,性能也低
std::condition_variable
std::unique_lock与std::lock_guard
上文中介绍了std::lock_guard,它只能在作用域结束的时候自动释放锁,本身并没有任何API可以调用;而std::unique_lock可以在使用途中手动上锁或解锁
{
// 构造函数中自动上锁
std::unique_lock<std::mutex> uniqueLock(mutexLock);
// 手动解锁
uniqueLock.unlock();
// 手动上锁
uniqueLock.lock();
// 离开作用域 检测到仍是上锁状态 自动解锁
}
condition_variable中的wait操作需要解锁和上锁操作,所以是搭配std::unique_lock使用的
示例
使用“信号量”机制进行线程同步,这种做法和操作系统中的PV操作十分相似了
class TestCondition
{
private:
std::mutex mutexLock;
std::condition_variable condition;
std::deque<int> deque;
public:
void consumeFunc(int id)
{
while (true)
{
std::unique_lock<std::mutex> uniqueLock(mutexLock);
// 如果资源不足 则等待
if (deque.empty())
condition.wait(uniqueLock);
int data = deque.back();
std::cout << "thread" << id << " take " << data << std::endl;
deque.pop_back();
}
}
void producerFunc()
{
while (true)
{
// 模拟一秒生产一个资源
std::this_thread::sleep_for(std::chrono::seconds(1));
std::unique_lock<std::mutex> lck(mutexLock);
if (deque.empty())
{
std::cout << "create 1 resources" << std::endl;
deque.push_back(1);
condition.notify_one();
}
}
}
};
int main()
{
TestCondition testCondition;
std::vector<std::thread> consumeThreads;
for (int i = 0; i < 1; i++)
consumeThreads.emplace_back(&TestCondition::consumeFunc, &testCondition, i);
std::thread producerThread(&TestCondition::producerFunc, &testCondition);
for (auto& consumeThread : consumeThreads)
{
if (consumeThread.joinable())
consumeThread.join();
}
if (producerThread.joinable())
producerThread.join();
return 0;
}
虚假唤醒
以上演示的是单个消费者进程,以及生产者进程执行单个唤醒notify_one的情况;但当有多个线程并且全部唤醒(notify_all)时,可能会出现虚假唤醒的情况(本例中虽然是多个消费者,但由于是单个唤醒因此并不会导致虚假唤醒)
虚假唤醒:当一个线程需要的资源被满足时,它将被唤醒,而当它唤醒后资源被其他线程使用了,导致一个无资源可用的线程的运行,可能会导致异常的抛出等问题
void consumeFunc(int id)
{
while (true)
{
std::unique_lock<std::mutex> uniqueLock(mutexLock);
// 如果资源不足 则等待
if (deque.empty())
condition.wait(uniqueLock);
int data = deque.back();
std::cout << "thread" << id << " take " << data << std::endl;
deque.pop_back();
uniqueLock.unlock();
}
}
void producerFunc()
{
while (true)
{
// 模拟一秒生产一个资源
std::this_thread::sleep_for(std::chrono::seconds(1));
std::unique_lock<std::mutex> lck(mutexLock);
if (deque.empty())
{
std::cout << "create 1 resources" << std::endl;
deque.push_back(1);
condition.notify_all();
}
}
}
以上代码在运行后会崩溃,原因是访问了一个empty deque
原因在于线程当判断无法获得资源时,它将被阻塞在condition.wait(uniqueLock);处,当重新唤醒时并不会再次进行资源有效性的判断,导致和其他线程之间存在竞争操作(两个线程被唤醒,而只有一个资源,其中一个线程拿走后另一个线程便是虚假唤醒),正确做法是
while (deque.empty())
condition.wait(uniqueLock);
// 或者
// condition.wait(uniqueLock, [this]() { return !deque.empty(); });
条件变量的tricky
class TestCondition {
private:
std::mutex mutexLock;
std::condition_variable condition;
std::deque<int> deque;
public:
void consumeFunc(int id) {
while (true) {
std::unique_lock<std::mutex> uniqueLock(mutexLock);
// 如果资源不足 则等待
while (deque.empty())
condition.wait(uniqueLock);
// 获取资源成功
int data = deque.back();
std::cout << "thread" << id << " take" << data << std::endl;
deque.pop_back();
// 拿走资源后 手动释放锁 让其他生产者进程能够获取资源
uniqueLock.unlock();
// 模拟资源的处理时间需要三秒
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << "thread" << id << " finish " << data << std::endl;
}
}
void producerFunc() {
while (true) {
// 模拟100毫秒生产一个资源
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::unique_lock<std::mutex> lck(mutexLock);
// 只有队列为空的时候才会产生资源
if (deque.empty()) {
std::cout << "create 1 resources" << std::endl;
deque.push_back(1);
condition.notify_all();
}
}
}
};

条件变量与线程同步
设想有这样的工作场景:有一个线程用来分发工作,有两个线程用来处理工作,其中2号线程需要1号线程执行第结果,即需要线程同步
此例中任务的执行效率其实和单线程是一致的,主要是为了体现进程之间的同步
class ComplexCondition
{
private:
int phase_index;
std::atomic<int> task_id;
std::mutex mutex;
std::condition_variable cv;
public:
ComplexCondition() : task_id(0), phase_index(0) {}
void phase1()
{
// while there is still a task
while (task_id != -1)
{
std::unique_lock<std::mutex> lk(mutex);
// 等待流程为1 无任务可执行时会在这里挂起
cv.wait(lk, [this]() { return phase_index == 1; });
// 双重检测
bool is_finish = task_id == -1;
if (!is_finish)
std::cout << "Processing phase 1 for task_id" << task_id.load() << std::endl;
else
std::cout << "Finish phase 1 thread" << std::endl;
// 执行第二步操作
phase_index = 2;
cv.notify_all();
lk.unlock();
if (is_finish)
return;
}
}
void phase2()
{
// while there is still a task
while (task_id != -1)
{
std::unique_lock<std::mutex> lk(mutex);
// 等待流程为2 流程1未完成时会在这里挂起
cv.wait(lk, [this]() { return phase_index == 2; });
bool is_finished = task_id == -1;
if (!is_finished)
std::cout << "Processing phase 2 for task id" << task_id.load() << std::endl;
else
std::cout << "Finish phase 2 thread" << std::endl;
// 当前task全部操作执行完 信号位置为-1
phase_index = -1;
lk.unlock();
cv.notify_all();
if (is_finished)
return;
}
}
void task_sender()
{
// 开启两个执行任务线程
std::thread p1(&ComplexCondition::phase1, this);
std::thread p2(&ComplexCondition::phase2, this);
// 主线程颁发任务
for (int i = 0; i < 50; i++)
{
std::cout << "Starting task" << i << std::endl;
{
std::unique_lock<std::mutex> lk(mutex);
task_id = i; // 第i号任务
phase_index = 1; // 首先执行第一步操作
cv.notify_all();
}
// 模拟任务准备需要300ms 多线程使其能在准备新任务的同时执行旧任务
std::this_thread::sleep_for(std::chrono::milliseconds(300));
{
// 等待操作执行完毕 才能发放新的任务
std::unique_lock<std::mutex> lk(mutex);
cv.wait(lk, [this]() { return phase_index == -1; });
std::cout << "Task" << i << " has finished" << std::endl;
}
}
// 所有任务执行完毕
task_id = -1;
// 重置信号位让操作线程结束
phase_index = 1;
cv.notify_all();
p1.join();
p2.join();
}
};
int main()
{
ComplexCondition c;
c.task_sender();
}
在线程中获取“返回值”
使用std::future和std::promise
std::future代表一个未来的值,可以通过与之绑定的std::promise来设置std::future对象的值,而当它的值未被设定却使用了.get()时,调用这个API的线程将会被阻塞
std::promise可以和一个std::future对象绑定,然后在线程间以指针的方式传递,当数据准备就绪时可以使用set_value来设置与之绑定的std::future对象的值
#include<future>
void test_future(std::promise<int>* p)
{
// 模拟数据的准备
std::this_thread::sleep_for(std::chrono::seconds(2));
p->set_value(43);
}
int main()
{
std::promise<int> p;
std::future<int> data = p.get_future();
std::thread newThread(test_future, &p);
cout << "waiting for data" << endl;
// 越等待两秒后 数据得到输出
cout << data.get() << endl;
if (newThread.joinable())
newThread.join();
}
使用std::async执行异步操作
上文中提到了使用std::future和std::promise来获取线程中的“返回值”
std::async中其实自动为你创建了一个新线程和一个std::promise对象,同时返回一个std::function
- It automatically creates a thread (Or picks from internal thread pool) and a promise object for us.
- Then passes the std::promise object to thread function and returns the associated std::future object.
- When our passed argument function exits then its value will be set in this promise object, so eventually return value will be available in std::future object.
struct GetDataFromDB
{
inline string operator()(const string& str)
{
std::this_thread::sleep_for(std::chrono::seconds(3));
return "From DB " + str;
}
};
string GetDataFromFile(const string& str)
{
std::this_thread::sleep_for(std::chrono::seconds(3));
return "From File " + str;
}
int main()
{
auto startTime = std::chrono::system_clock::now();
std::future<string> dbStr = std::async(launch::async, GetDataFromDB(), "Mike");
std::string fileStr = GetDataFromFile("Jelly");
std::cout << dbStr.get() << std::endl << fileStr << std::endl;
auto endTime = std::chrono::system_clock::now();
std::cout << "takes " << std::chrono::duration_cast<std::chrono::seconds>(endTime - startTime).count() << " second" << std::endl;
}
std::async的第一个参数代表启动参数
launch::async:使用异步运行,会创建一个新的线程launch::deferred:同步执行,只有当返回的std::future对象被.get()时才会执行- 默认不填:程序根据系统负载自动选择异步或同步
下面演示不使用std::async的做法,可以在没有任何包装(不论是库的包装还是自己的包装)的情况下是非常麻烦的
struct GetDataFromDB
{
inline void operator()(std::promise<string>& p, const string& str)
{
std::this_thread::sleep_for(std::chrono::seconds(3));
p.set_value("From DB " + str);
}
};
string GetDataFromFile(const string& str)
{
std::this_thread::sleep_for(std::chrono::seconds(3));
return "From File " + str;
}
int main()
{
auto startTime = std::chrono::system_clock::now();
// 获取DB中的数据
std::promise<string> promiseObj;
std::future<string> dbStr = promiseObj.get_future();
std::thread newThead(GetDataFromDB(), std::ref(promiseObj), "Mike");
// 获取文件中的数据
std::string fileStr = GetDataFromFile("Jelly");
// 输出
std::cout << dbStr.get() << std::endl << fileStr << std::endl;
auto endTime = std::chrono::system_clock::now();
std::cout << "takes " << std::chrono::duration_cast<std::chrono::seconds>(endTime - startTime).count() << " second" << std::endl;
if (newThead.joinable())
newThead.join();
}
std::this_thread::yield
设想这么一种情况:在单核的机器上,有一个双线程的进程,其中一个线程占有CPU并处理完自己的工作后等待另一个线程的结果,此等待使用了busy waiting。那么由于是单核心CPU,因此在时间片用完执行进程调度的时候,由于线程的busy waiting导致CPU占有率高,使得CPU的调度策略仍会执行此busy wating的线程,那么会导致一方忙等一方饥饿的死锁局面。这个时候我们可以使用std::this_thread::yield()来让当前线程主动放弃处理机占有权
在busy waiting或无锁编程的等待之前使用一次std::this_thread::yield(),它会减少可能的等待时间。
而使用std::mutex的情况下并不需要使用std::this_thread::yield(),因为由于锁的存在,线程将会被挂起,而不是“空转”
std::recursive_mutex
递归锁,当我们需要在一个线程中重复对一个锁上锁时,应该使用std::recursive_mutex
class TestMutex {
private:
std::mutex lock;
std::string name;
public:
void generate_name() {
std::unique_lock<decltype(lock)> u(lock);
name = "Jelly";
}
std::string& get_name() {
std::unique_lock<decltype(lock)> u(lock);
generate_name();
return name;
}
};
以上代码在执行get_name时会抛出异常,因为在同一线程中对std::mutex执行了两次上锁,正确的做法是
private:
std::recursive_mutex lock;
std::string name;
原子操作
最初人们使用互斥锁来解决线程竞争访问临界区资源的问题,但是对于一些“小个体而言”,使用互斥锁的开销太大了,因此引入了原子操作。
// 控制台显示耗时4s
int main()
{
inTime time;
int count = 0;
std::vector<std::thread> threadVec;
threadVec.reserve(500);
std::mutex mutexLock;
for (int i = 0; i < 100; i++)
{
threadVec.emplace_back([&]()
{
for (int j = 0; j < 1000000; j++)
{
mutexLock.lock();
count++;
mutexLock.unlock();
}
});
}
for (auto& t : threadVec)
if (t.joinable())
t.join();
std::cout << count << std::endl;
}
// 控制台显示耗时1.7s
int main()
{
inTime time;
std::atomic<int> count{0};
std::vector<std::thread> threadVec;
threadVec.reserve(500);
for (int i = 0; i < 100; i++)
{
threadVec.emplace_back([&]()
{
for (int j = 0; j < 1000000; j++)
count++;
});
}
for (auto& t : threadVec)
if (t.joinable())
t.join();
std::cout << count << std::endl;
}
对于自定类型(必须是内置类型的组合),可通过::is_lock_free来检测是否支持原子操作
struct TestAtomic
{
int age;
double* pScore;
};
int main()
{
std::atomic<TestAtomic> temp;
// 根据API查看此结构是否支持原子操作
cout << boolalpha << temp.is_lock_free() << endl; // true
}
对原子操作的支持,取决于CPU的结构和该结构是否满足该结构对内存对齐条件的要求(什么规律我还没摸清)
肯定的一点是,带有非内置类型的结构体/类不是原子类型,比如携带std::string的结构体
使用原子变量分发任务
std::atomic_fetch_add操作会返回执行加操作前的t_number值(线程安全),本例中的+1操作代表计算进度推进一次
以某一个线程为例,设共有8个线程,当前线程正在计算数55,那么当本次计算结束进入新一轮时,由于任务是并行的,那么它下一次就可能拿到数据61(在此期间有5个线程也完成了计算)。因此t_number的值是唯一的,会在0-expected_index中增长,每个线程拿到的值必然不相等,也以此达到了并行的功能
class AtomicSender {
private:
std::atomic<std::uint64_t> prime_count;
std::atomic<std::uint64_t> cur_number;
std::uint64_t expected_index;
void find_prime() {
std::uint64_t t_number = 0;
do {
// std::atomic_fetch_add will return old data
t_number = std::atomic_fetch_add(&cur_number, 1);
if (!(t_number <= expected_index))
break;
bool is_prime = true;
for (std::uint64_t i = 2; i * i <= t_number; ++i) {
if (t_number % i == 0) {
is_prime = false;
break;
}
}
if (is_prime)
std::atomic_fetch_add(&prime_count, 1);
} while (t_number <= expected_index);
}
public:
AtomicSender() : prime_count(0), cur_number(2), expected_index(0) {}
void multi_thread_find_prime() {
std::cin >> expected_index;
std::cout << "Find the prime number count less than" << expected_index << std::endl;
std::size_t threadMaxAmount = std::thread::hardware_concurrency();
SimpleThreadPool threadPool(threadMaxAmount);
for (std::size_t i = 0; i < threadMaxAmount; i++)
threadPool.add(&AtomicSender::find_prime, this);
threadPool.join_all();
std::cout << prime_count.load() << std::endl;
}
};
内存顺序
C++中的并行算法库
Thread Local Storage
俗称TLS,意思是线程本地储存,可以看到,我建立了一个pContext在三个线程中分别是三个不同的值,他们只是使用了相同的名称,实际储存的数据是不相同的(指针的地址以及指针的指向都是thread local的)
struct Context {
std::vector<int> container;
explicit Context(std::vector<int> data) : container(std::move(data)) {}
};
thread_local Context* pContext;
void thread_fuc(const std::vector<int> &data) {
pContext = new Context(data);
print_container_space(pContext->container);
delete pContext;
}
int main()
{
std::vector<int> mainVec{100, 100, 100, 100};
std::vector<int> vec1{1, 2, 3 ,4 ,5};
std::vector<int> vec2{6, 7, 8, 9, 10};
pContext = new Context(mainVec);
std::thread t1(thread_fuc, std::ref(vec1));
std::thread t2(thread_fuc, std::ref(vec2));
t1.join();
t2.join();
print_container_space(pContext->container);
delete pContext;
}
thread local是不需要同步的,每个线程都有一份

Modern Concurrent
概要
成熟的框架
- C++标准
- OpenMP
- Boost
- Inter TBB
- Coroutine
并行计算的主要模式
- 计算密集:大量数据并行处理
- 任务密集:如游戏中多线程处理不同模块的任务,如音频,网络,渲染
并行计算中的难点
- 同步:计算依赖,内存依赖
- 调试困难:死锁,饥饿,资源竞争,问题的不可复现性
- IO
线程与进程
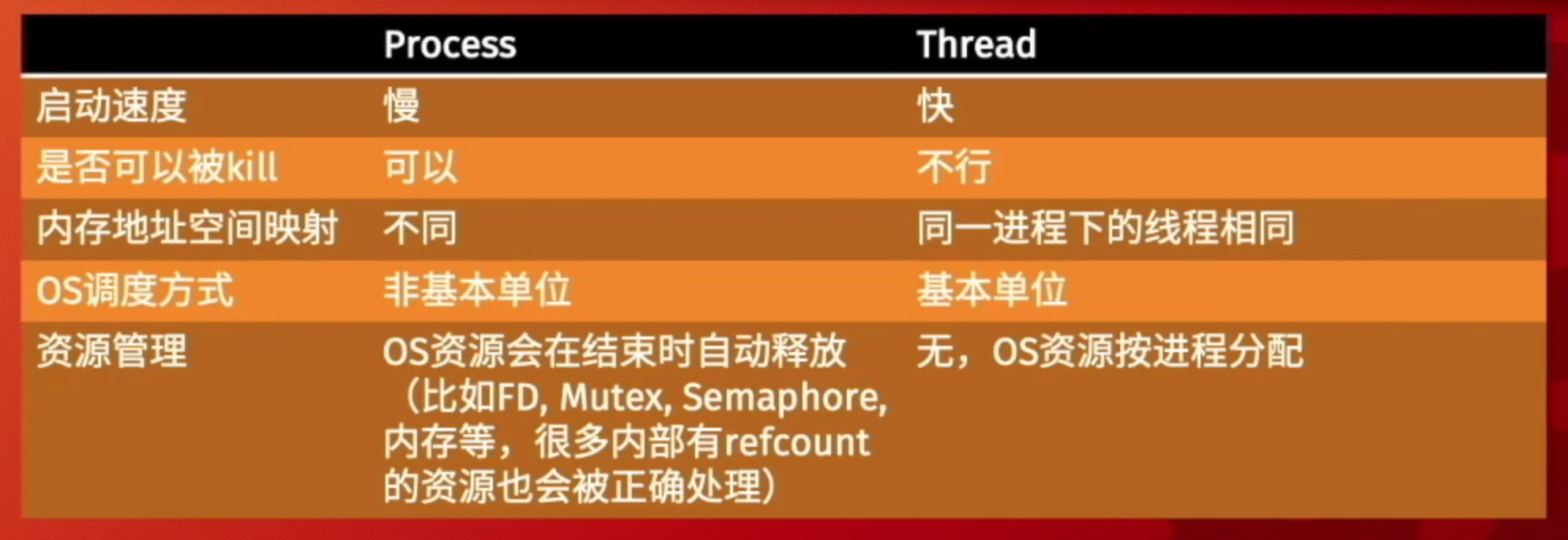
-
线程是调度的基本单位,而进程是资源分配的基本单位。所以很多数据在线程中止后可能会出现“泄露”的情况,在进程终止后才会被操作系统回收
-
Thread不能被Kill的意思是:程序员们在编程时尽可能地不要使用操作系统底层的API去杀死一个线程(经验之谈)。因为系统的资源是以进程为单位分配的,当我们Kill掉一个线程的时候,因为我们无法有作用域或析构函数来释放它所占有的资源,同时操作系统也无法回收,例如当一个线程被杀死时,它的mutex并不能被释放,那么也就可能导致另一个线程一直处于等待阶段,造成了死锁的发生
-
内存映射:不同的进程即使有一串相同的地址,它们映射到的实际物理地址仍然是不同的;而在不同的线程中,同一串地址总是能映射到同一片数据上,因此共享数据时非常方便,没有多余的overhead
CPU Cache
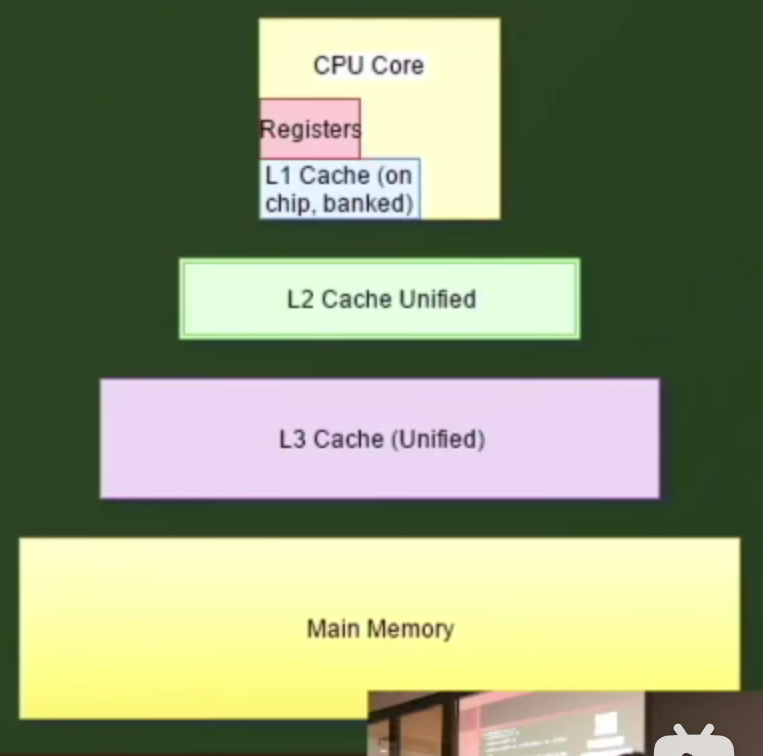
- Registers(寄存器)和L1级Cache是每个CPU核心有一份的,而L2,L3和内存是多核心共享的
- 举个例子,当一个核心计算了数据后,并没有reflush到L2或者L3这种共享区,那么其他核心就不能获取到新计算的结果,而Cache对程序是透明的
- 对内存进行+1并不是原子操作,同理,不要对很多基本操作做原子操作假设。比如最基本的修改一个整数的操作,就包含了load和write
多线程查找数列中的最大值
volatile
volatile和多线程间的同步并无关系
volatile实际上是一个compiler的关键字,它对Cache是没有影响的,也一定不会引起Cache的reflush
例如在一段C代码中
{
int a = 10;
a *= 5;
// 对a进行一系列操作
}
那么编译器可能会这么优化,在进行以上作用域计算时,不会在每步操作后将a写回内存,而是将a一直存放在寄存器中计算,完成全部操作后再放回内存
volatile关键字会避免以上的问题,它阻止了编译器优化,每次对a的读写操作,都会从内存中read和write
Use std::atomic for concurrency, volatile for special memory
核心问题分析
- 读取和写入非原子操作导致不加保护的多线程程序会出现结果不一致的情况
- 若将读写操作转变为原子操作,那么多线程将会失去并发性,编程串行计算
代码展示
template<template<typename> typename Container, typename Element>
Element find_max_num_multi_thread(const Container<Element> &vec)
{
std::size_t threadAmount = std::thread::hardware_concurrency();
std::size_t handleLength = vec.size() / threadAmount;
std::vector<std::thread> threadVec;
std::vector<Element> maxVec(threadAmount);
for (std::size_t i = 0; i < threadAmount; i++)
threadVec.emplace_back([&maxVec, &vec, handleLength](std::size_t index) {
maxVec[index] = *std::max_element(vec.begin() + index * handleLength, vec.begin() + (index + 1) * handleLength - 1);
}, i);
for (auto& t : threadVec)
if (t.joinable())
t.join();
return *std::max_element(maxVec.begin(), maxVec.end());
}
void test_find_max_num()
{
auto vec = generate_random_container_multi_thread<std::vector>(10000000, 0, 100000000);
InTime it;
std::cout << find_max_num_single_thread<std::vector>(vec) << std::endl;
it.Stop();
it.ReStart();
std::cout << find_max_num_multi_thread<std::vector>(vec) << std::endl;
it.Stop();
}
多线程排序
首先实现一个非常简单的不具有线程安全的线程池(只允许单线程add)
class SimpleThreadPool
{
private:
std::vector<std::thread> pool;
public:
SimpleThreadPool() = default;
SimpleThreadPool(std::size_t amount) {
pool.reserve(amount);
}
~SimpleThreadPool() {
join_all();
}
template<typename... T>
void add(T&&... args) {
pool.emplace_back(std::forward<T>(args)...);
}
void join_all() {
for (auto& t : pool)
if (t.joinable())
t.join();
}
void clear()
{
pool.clear();
}
};
然后实现一个快速排序和归并排序,由于快排中使用了类似do while的结构,因此会有index为-1的情况,因此只能使用std::int64_t
template<typename T>
void quick_sort(T& vec, std::int64_t l, std::int64_t r)
{
if (l >= r) return;
std::int64_t i = l - 1, j = r + 1, x = vec[l];
while (i < j) {
while (vec[++i] < x);
while (vec[--j] > x);
if (i < j)
std::swap(vec[i], vec[j]);
}
quick_sort(vec, l, j);
quick_sort(vec, j + 1, r);
}
template<typename T>
void merge(T &vec, const T &cached, const std::tuple<std::size_t, std::size_t, std::size_t>& t) {
const auto&[l, mid, r] = t;
if (l >= r)
return;
std::size_t i = l, j = mid + 1, resultIndex = l;
while (i <= mid && j <= r) {
if (cached[i] <= cached[j])
vec[resultIndex++] = cached[i++];
else
vec[resultIndex++] = cached[j++];
}
while (i <= mid)
vec[resultIndex++] = cached[i++];
while (j <= r)
vec[resultIndex++] = cached[j++];
}
最后是重头戏,多线程排序。目前已知该排序存在两个Bug。读者可以根据自己的情况修复这两个问题
- 由于是获取系统中的线程数,因此当线程数不能被2除尽时,排序结果出错(12 / 2 / 2 = 3,不能被除尽)
- 当排序的数组容量小于线程数时,程序出错
// 多线程快排
template<typename T>
void multi_thread_quick_sort(T &vec) {
// 获取当前最大可用的线程数量
std::size_t threadAmount = std::thread::hardware_concurrency();
SimpleThreadPool threadPool(threadAmount);
// 记录快排区间
std::vector<std::pair<std::size_t, std::size_t>> sortArea;
sortArea.reserve(threadAmount);
// 多线程分组快排
for (std::size_t i = 0; i < threadAmount; i++) {
std::size_t lengthPerThread = vec.size() / threadAmount;
sortArea.emplace_back(i * lengthPerThread, (i + 1) * lengthPerThread - 1);
// 对结果进行特殊处理
if (i == threadAmount - 1)
sortArea.back().second = vec.size() - 1;
threadPool.add(quick_sort<T>, std::ref(vec), sortArea.back().first, sortArea.back().second);
}
threadPool.join_all();
// 开始归并操作
for (threadAmount /= 2; threadAmount != 0; threadAmount /= 2) {
T result(vec.size());
threadPool.clear();
// 处理归并所需要的线程数量
// 每条线程应该处理的数据数量
for (std::size_t j = 0; j < threadAmount; j++) {
std::size_t startIndex = j * sortArea.size() / threadAmount;
std::size_t endIndex = (j + 1) * sortArea.size() / threadAmount - 1;
auto start = sortArea[startIndex].first;
auto mid = sortArea[(startIndex + endIndex) / 2].second;
auto end = sortArea[endIndex].second;
threadPool.add(merge<T>, std::ref(result), std::ref(vec), std::make_tuple(start, mid, end));
}
threadPool.join_all();
vec = std::move(result);
}
}
测试代码为
void test_multi_sort() {
auto vec1 = generate_random_container_single_thread<std::vector>(12452, 0, 1000000);
auto vec2 = vec1;
single_thread_quick_sort(vec1);
std::cout << std::endl;
multi_thread_quick_sort(vec2);
std::cout << std::boolalpha << std::equal(vec1.begin(), vec1.end(), vec2.begin(), vec2.end());
}
多线程设计原则
- 尽量不等待(让不同的线程负责不同模块的功能),尽量不读写同一块资源(如果是多线程同时读一块空间,那么不会出现问题)
- 尽量不要使用busy waiting(即在线程中使用
while循环卡住某条件,会占用CPU执行一些没有用的操作),长时间的等待应该使用mutex - 现成的任务不能太少,因为启动线程会有代价(启动一条线程大概需要1000条汇编指令);同时每个线程分配的任务应该尽可能均衡。一开始就新建多条线程,有任务来就执行,没有任务来就挂起,也就是线程池
- 锁的粒度应该越小越好,锁的粒度过大性能会趋向于串行计算
mutex与semaphore
-
mutex是二元信号量(互斥锁,0和1代表资源的有无),而semaphore是多元的,也就是说最多可以有N个线程同时进入acquire状态(比如系统现在只能分配4个核心出来解决网络事件,但是某一时刻的网络事件数量可能远远大于4)
-
C++11中的std::mutex只能在单进程中使用(用来同步不同的线程),但是OS中的互斥锁是可以用来同步不同进程的,如boost库中的name_mutex
-
强行杀死一个进程,被他lock的mutex会被释放。因为mutex也属于操作系统的资源,就像内存一样,在进程退出的时候会被操作系统自动回收。相反,强行杀死一个线程的话mutex不会被释放
-
mutex会影响cache。mutex lock会引起cache的flush,所以在lock之后读入的全局变量是当前最新的;mutex unlock也会有cache的flush,保证了在unlock之后写入的全局变量会立马被其他的线程看到
-
mutex进入lock后其他线程会被阻塞,不会占用CPU时间(类似于sleep)。但是mutex导致的线程挂起以及恢复都会有用户态到核心态的切换,所以特别短的等待时间不建议使用mutex,它至少会有上百条指令的代价
OpenMP
OMP的使用可以说是非常简单了,它会自动帮我们调用系统中可用的线程来执行指定的代码,相比于std::thread而言,它更适合做数据处理的功能。OMP处理的线程会默认在作用域后join
需要包含<omp.h>,在VS中还需要在项目属性中开启OMP。只需要掌握两条OMP的简单语句
#pragma omp parallel
让系统中可用的线程都执行下方作用域中的代码
#pragma omp parallel
{
std::cout << "Hello world from " << omp_get_thread_num() << std::endl;
}
std::cout << "end" << std::endl;
本测试机器为8线程,因此会输出八次Hello world和一次end,其中Hello world由于线程的异步性多次输出会有多次不同的结果
#pragma omp parallel for
假设我们要使用OMP去利用多线程去加速一个取最大值的算法,那么我们可能会这么写
std::vector<int> vec(100000);
std::iota(vec.begin(), vec.end(), 1);
int maxNum = vec[0];
#pragma omp parallel for
for (auto i = 0; i < vec.size(); i++)
maxNum = std::max(maxNum, vec[i]);
std::cout << maxNum << std::endl;
std::vector<int> vec(100000);
std::iota(vec.begin(), vec.end(), 1);
volatile int maxNum = vec[0];
#pragma omp parallel for
for (auto i = 0; i < vec.size(); i++)
maxNum = maxNum > vec[i] ? maxNum : vec[i];
std::cout << maxNum << std::endl;
std::vector<int> vec(100000);
std::iota(vec.begin(), vec.end(), 1);
std::atomic<int> max = vec[0];
#pragma omp parallel for
for (auto i = 0; i < vec.size(); i++)
max = max.load() > vec[i] ? max.load() : vec[i];
std::cout << max << std::endl;
当你实际运行的时候,你会发现到上面的结果都是错误的,甚至下面两种写法会错的更离谱
因为volatile只是确保每次读写都会从内存中操作,和线程同步没有关系;而std::atomic中显式的load出了它存储的数据,再赋值的时候它可能已经被别的线程所修改了。
正确的做法是加锁,CAS以及分段处理。加锁这里就不介绍了
// 使用CAS
std::vector<int> vec(100000);
std::iota(vec.begin(), vec.end(), 1);
std::atomic<int> maxNum = vec[0];
#pragma omp parallel for
for (auto i = 0; i < vec.size(); i++)
{
int data = maxNum.load(), maxData = vec[0];
// 由于数据可能被更新 所以需要使用do while
do
maxData = data > vec[i] ? data : vec[i];
while (!std::atomic_compare_exchange_weak(&maxNum, &data, maxData));
}
std::cout << maxNum << std::endl;
// 分段处理
std::vector<int> vec(100000);
std::iota(vec.begin(), vec.end(), 1);
std::vector<int> thread_kocal_max_vec(omp_get_max_threads(), vec[0]);
auto vec_total_count = vec.size();
const int* p = vec.data();
#pragma omp parallel
{
// 本机器有8线程 假设程序全部调度
auto total_thread_count = omp_get_num_threads();
// 那么线程编号为0-7
auto thread_id = omp_get_thread_num();
std::size_t start = thread_id * vec_total_count / total_thread_count;
std::size_t end = (thread_id + 1) * vec_total_count / total_thread_count;
if (thread_id + 1 == total_thread_count)
end = vec_total_count;
// 本例中 任务被切分为0-12500|12500-25000| ... |87500-100000共八个部分
if (end > start)
{
int local_max = p[start];
for (std::size_t i = start + 1; i < end; i++)
local_max = std::max(local_max, p[i]);
thread_kocal_max_vec[thread_id] = local_max;
}
}
std::cout << *std::max_element(thread_kocal_max_vec.begin(), thread_kocal_max_vec.end()) << std::endl;
无锁编程
lock free
lock free:没有系统mutex/semaphore,核心实现是使用std::atomic,最重要的是使用CAS
lock free的特点
- 给一段很长的时间,程序总是会计算出结果(即总会有一个线程在执行有用的任务)
- 程序不会发生死锁
- 可能会由于busy waiting而导致资源的浪费
- 注意cache的问题
什么时候应该使用lock free
- 当多线程程序具有明显的性能问题时(一般这种现象是频繁上锁解锁导致的,或锁的粒度过大)(因为上锁解锁可能会导致线程阻塞挂起或恢复运行,而一旦发生线程调度,那么就会出现操作系统在两态之间切换的情况)
- 当不需要长时间等待的时候可以考虑使用lock free(因为长时间的等待,即busy wating会一直占有CPU,利用率下降)
CAS:Compare And Swap
CAS
先来看一段CAS的伪代码
bool atomic_compare_exchange_strong(obj, expected, desired)
{
if (*obj == *expected)
{
*obj = desired;
return true;
}
else
{
*expected = *obj;
return false;
}
}
试想这么一种情况,我们需要维护一个线程安全的链栈。那么当有新数据push时,我们需要生成一个新的节点,然后将节点的next指向当前的head,然后再将新数据设置为head
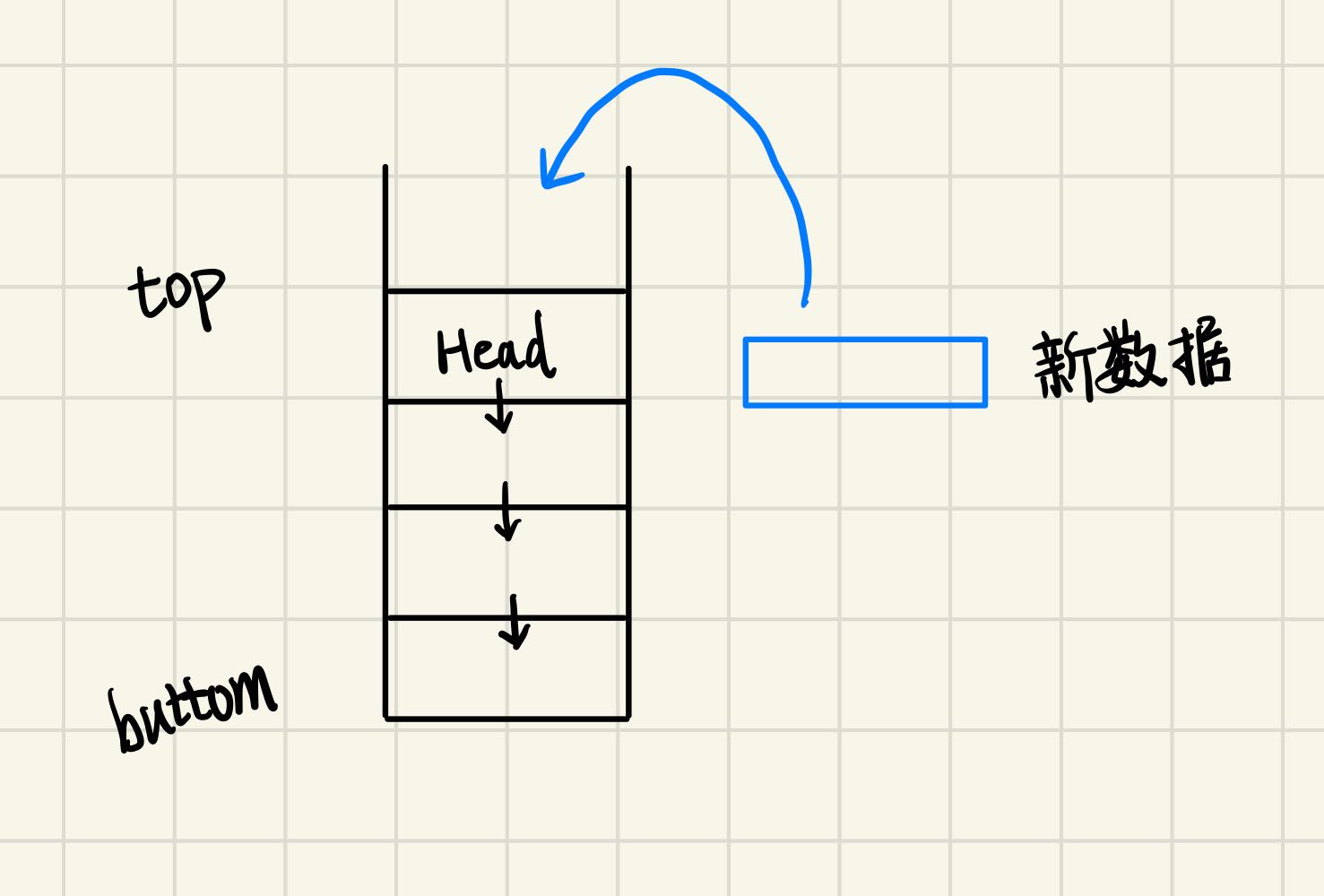
但是仔细想一下,以上的push操作并不是原子的,但是head是多个线程间共享的数据,那么这个数据结构就不是线程安全的。首先想到的解决方案是上锁,每次push之前上锁,结束后解锁,但是我们每次push的时间是非常短暂的,而在如此短暂的情境下使用锁,会导致多余的开销很大。此时CAS便派上用场了
template<typename T>
class stack
{
std::atomic<node<T>*> head;
public:
void push(const T& data)
{
// 创建一个新的节点
node<T>* new_node = new node<T>(data);
// 新节点的next指向当前头部
new_node->next = head.load();
// 利用CAS可以防止在这上下两行代码间隔的时间内 head被其他线程修改
// 利用CAS检测当前的头部是否与缓存的头部相等 相等则设置新节点为头部
while(!std::atomic_compare_exchange_weak(&head, &new_node->next, new_node));
}
};
上述CAS很巧妙的一点在于,它会while循环让new_node->next取值为新的头部(即可能被别的线程修改后的新头部),然后在下一次操作中完成赋值(如果又被别的线程抢先了那么会一直while循环)。同时传入的是new_node->next的地址,说明在函数内部修改的将会是指针本身
CAS操作会引发cache flush,所以执行CAS操作后写入的变量会立马被其他线程所看到
综上,当我们需要对load出来的原子变量进行修改时,CAS可以在兼顾性能的同时保证线程安全,如果以上代码修改如下,那么将是线程不安全的
void push(const T& data)
{
node<T>* new_node = new node<T>(data);
new_node->next = head.load();
head.load() = new_node;
}
虽然有了CAS后,我们可以实现复杂的无锁容器,但是为了确保稳定性还是建议使用Boost库中已经实现好的Concurrent Containers
总结
- 避免等待,特别是busy waiting
- 避免访问公共资源
- 永远不要kill thread,虽然有相关的WinAPI,但这是一个非常糟糕的想法
- 无锁只读的对象尽量使用简单的结构,比如尽量不要访问
std::vector,而是访问由data()返回的指针 - 任何类在没有特别说明的情况下应该默认为线程不安全
- 线程间内存资源多使用smart pointer管理
- 给不同线程分配的任务应该越均衡越好
- 多线程编程中操作的顺序非常重要,一些关键的代码最好使用已知的模板
- 尽量使用一些标准中的多线程容器
- 对性能要求非常高的地方应该考虑使用无锁编程,无锁编程一般会使用
do while+std::atomic_compare_exchange_weak