0.对内存磁盘的简单理解
还是对之前那个简单计算机的思考
一个计算机的基本功能 输入 + 运算 + 输出
但是这里还有个问题,如果我想重复计算 想一个小时之后把之前的运算再做一次,这样是不是需要计算机找个地方存数据啊
计算机存数据的地方大概分几种 cpu寄存器,Cache高速缓存,主存,磁盘
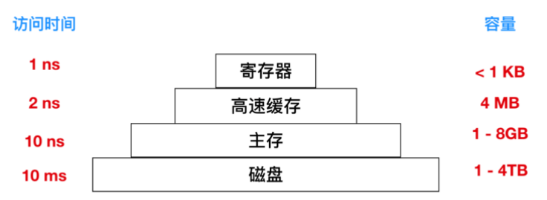
从图中看就能看明白个大概,寄存器这东西就是cpu自带的一点点空间,速度最快 ns级别,
主存就是我们常说的内存,空间大概1-8G,速度大约比寄存器慢十倍,
高速缓冲存储器Cache主要是为了解决CPU和主存速度不匹配而设计的。 (它的存取速度接近CPU,它比主存的优先级高,CPU存取信息时优先访问Cache,找不到的话再去主存中找,同时把信息周围的数据块从主存复制到Cache中。)
最后是磁盘,空间最大,我们就可以理解为计算机乱七八糟的东西都可以存在这 但是访问速度下降一大个级别,没关系 比如很可能你某盘的某些资源不会访问的很频繁(狗头)
最后说一下就是 作为一个本分朴实的java程序员,我们大概率的优化都在搞内存和磁盘的优化,包括一些框架,一些中间件的设计也是基于这两点和IO在搞优化
1.啥是虚拟内存
这个之前有写过,简单的说就是实际的物理内存就4个G那么大,我开了一个LoL应用那内存不就占满了 连挂个QQ都不让了
实际上无论是LoL还是QQ都对于持有计算机内存的概念都是虚拟内存,这东西就很虚了,计算机说我给你LoL分配了4个G的虚拟内存,其实实际物理内存可能就1G 可能还包括点磁盘空间 还画点大饼,
计算机估计一下给你那么多实际内存太浪费了,其实你省着点用1G就够用了,能省则省原则。假如LoL跑着跑着突然想访问一页数据,说好了应该在内存里的 现实却是还在磁盘上,
咋整呢 当虚拟地址映射找不到这块地址页马上CPU缺页中断,通过地址变换 将磁盘地址页加载到内存 再给LoL拿去玩
所以实际上让LOL感觉自己占了4G内存,其实是和其他几个小伙伴忽悠来一起用的这4G空间,只不过被虚拟内存连忽悠带骗,拆了东墙补西墙凑上的。
比喻的有点蛋疼,, 还是看原文吧 虚拟内存与Linux层级结构
2.空闲内存管理
操作系统在动态分配内存时(malloc,new),对空间内存进行管理。一般两种方式:位图和空闲链表。
位图:
内存可能被划分为小到几个字或大到几千字节的分配单元。每个分配单元对应于位图中的一位,0 表示空闲, 1 表示占用
这就好比把一块固定大小的地皮分成多少个小块,根据商家的需要,每个小块或者几个小块租给一个商家。
位图提供了一种简单的方法在固定大小的内存中跟踪内存的使用情况,因为位图的大小取决于内存和分配单元的大小。所以就会有一个问题,当有一个商家想租连续的十块那么大的地皮,你就得在位图中
给他找连续0的十块地皮,这是很耗时的操作,类似于杂乱无章的数组中找到连续的一块空闲元素。
空闲链表:
维护一个链表,这个链表记录了已分配的内存段和空闲的内存段
当按照地址的顺序在链表中存放已分配内存段(进程)和空闲区时,有几种新分配内存的算法 (当新创建的进程或者从磁盘中换入的进程)
-
首次适配算法:在链表中进行搜索,直到找到最初的一个足够大的空闲区,将其分配。除非进程大小和空间区大小恰好相同,否则会将产生内存碎片(多出来的那一部分)。该方法是速度很快的算法,因为索引链表结点的个数较少。
-
下次适配算法:工作方式与首次适配算法相同,但每次找到新的空闲区位置后都记录当前位置,下次寻找空闲区从上次结束的地方开始搜索,而不是与首次适配一样从头开始(尽量减少碎片呗)
-
最佳适配算法:搜索整个链表,找出能够容纳进程分配的最小的空闲区。这样存在的问题是,尽管可以保证为进程找到一个最为合适的空闲区进行分配,但大多数情况下,这样也会产生碎片,但估计碎片不大 肯定比首次适配算法强点
-
最差适配算法:与最佳适配算法相反,每次分配搜索最大的空闲区进行分配,从而可以使得空闲区拆分得到的新的空闲区可以更好的被进行利用。(尽量干掉碎片呗)
3.啥是页面置换算法?
在地址映射过程中,如果在页面中发现所要访问的页面不在内存中,那么就会产生一条缺页中断。当发生缺页中断时,如果操作系统内存中没有空闲页面,那么操作系统必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。
而用来选择淘汰哪一页的规则叫做页面置换算法。
说白了就是 页面淘汰算法,类比说Redis的内存淘汰策略 (技术的本质总是惊人的相似)
4.磁盘长啥样?

扒了张图,这玩意看起来就像是老式唱片机那个打碟 (技术的本质总是惊人的相似)
我们说在磁盘上存的东西,就以字节的形式存在磁盘盘片上,那明白了 就是转这个传动手臂,靠着这个读写磁头读盘片上的数据呗
由于单一盘片容量有限,一般硬盘都有两张以上的盘片,每个盘片有两面,都可记录信息,所以一张盘片对应着两个磁头。
盘片被分为许多扇形的区域,每个区域叫一个扇区,硬盘中每个扇区的大小固定为512字节。盘片表面上以盘片中心为圆心,不同半径的同心圆称为磁道,不同盘片相同半径的磁道所组成的圆柱称为柱面。
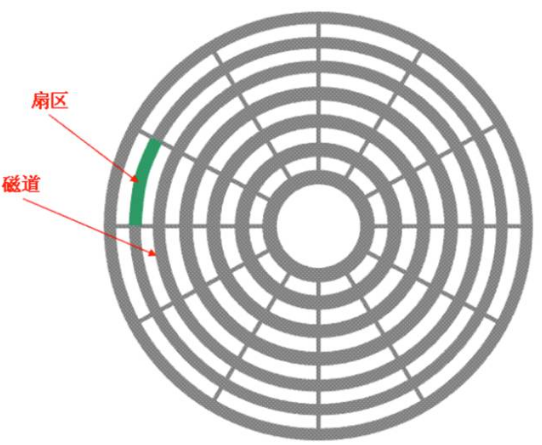
扇区,磁道,柱面其实有图挺好理解的 (至于磁道和柱面其实说的都是一圈一圈那个圈圈,区别就在于磁道指的是对一个盘片来说,柱面指的是多个盘片立体的那一圈圈)
早期的磁盘虽然 由于大小圆的半径不同扇区面积不同,但是每个扇区存放的字节数是相同的 这样的缺点就是外磁道的扇区 密度会小,比较浪费
此时由磁盘基本参数可以计算出硬盘的容量 存储容量=磁头数*磁道(柱面)数*每道扇区数*每扇区字节数
如今的磁盘使用ZBR(Zoned Bit Recording,区位记录)
盘片表面由里向外划分为数个区域,不同区域的磁道扇区数目不同,同一区域内各磁道扇区数相同,盘片外圈区域磁道长扇区数目较多,内圈区域磁道短扇区数目较少,大体实现了等密度,从而获得了更多的存储空间。
5.什么影响磁盘IO的性能?
它由寻道时间、旋转延迟和数据传输时间三部分构成。
寻道时间:指的是磁头在盘片上找到正确磁道的这一过程, 一般主要的性能消耗都在这了
旋转延迟:指盘片转转转 让磁头在磁道上找到正确的扇区,这个延迟主要取决于磁盘转速了 (7200rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms,而转速为15000rpm的磁盘其平均旋转延迟为2ms。)
数据传输时间:这个时间通常远小于前两者,计算时姑且忽略掉
机械硬盘的连续读写性能很好,但随机读写性能很差,这主要是因为磁头移动到正确的磁道上需要时间,随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上,所以性能不高。
6.操作系统层在磁盘IO的优化
操作系统是如何操作硬盘的
Linux系统中对于磁盘的一次读请求在核心空间中所要经历的层次模型

对于磁盘的一次读请求,首先经过虚拟文件系统层(VFS Layer),其次是具体的文件系统层(例如Ext2),接下来是Cache层(Page Cache Layer)、
通用块层(Generic Block Layer)、I/O调度层(I/O Scheduler Layer)、块设备驱动层(Block Device Driver Layer),最后是物理块设备层(Block Device Layer)。
Ext2文件系统:
操作系统读取硬盘的时候,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。这种由多个扇区组成的“块”,是文件存取的最小单位。“块”的大小,最常见的是4KB
硬盘分区被分为一个个Block块,每个Block大小一样,多个Block聚集一起分为Block Group块组,每个块组包含等量的物理块
每个块组都有一个块组描述符GDT(Group Descriptor Table),存储一个块组的描述信息,例如在这个块组中从哪里开始是Inode表,从哪里开始是数据块等等。
每个Block内最多只能够放置一个文件的数据,如果文件大于Block的大小,则一个文件会占用多个Block;如果文件小于Block,则该Block的剩余容量就不能够再被使用了,空间会浪费
Inode有点类似于索引,储存文件的“元信息”,比如文件的创建者、文件的创建日期、文件的大小等等 ,每个文件都有对应的一个Inode
Page Cache层:
引入Cache层的目的是为了提高Linux操作系统对磁盘访问的性能。Cache层在内存中缓存了磁盘上的部分数据。
类比于 开发中redis 和 mysql的应用,请求的数据回家先查Cache,未命中则再访问磁盘
在Linux的实现中,文件Cache分为两个层面,一是Page Cache,另一个Buffer Cache,每一个Page Cache包含若干Buffer Cache。
Page Cache主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有read/write操作的时候。Buffer Cache则主要是设计用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。
磁盘Cache有两大功能:预读和回写。
预读—— 对于每个文件的第一个读请求,系统读入所请求的页面并读入紧随其后的少数几个页面(通常是三个页面),这时的预读称为同步预读。
对于第二次读请求,如果所读页面不在Cache中,即不在前次预读的页中,则表明文件访问不是顺序访问,系统继续采用同步预读;如果所读页面在Cache中,则表明前次预读命中,操作系统把预读页的大小扩大一倍,此时预读过程是异步的,应用程序可以不等预读完成即可返回,只要后台慢慢读页面即可,这时的预读称为异步预读。
第一种情况是所请求的页面处于预读页面之外,这时系统就要进行同步预读。第二种情况是所请求的页面处于预读的页面中,这时继续进行异步预读;
回写—— 通过暂时将数据存在Cache里,然后统一异步写到磁盘中。(比较容易想到类比mysql的redolog update操作先更新redolog在内存中 此时为脏页,等触发条件再把脏页刷入磁盘)
下面两种情况下,脏页会被写回到磁盘:

也就是说一个条件是空间达到阈值,第二个条件是时间达到阈值
Linux 2.6.32内核之后,放弃了原有的pdflush机制,改成了bdi_writeback机制。bdi_writeback机制主要解决了原有fdflush机制存在的一个问题:在多磁盘的系统中,pdflush管理了所有磁盘的Cache,从而导致一定程度的I/O瓶颈。bdi_writeback机制为每个磁盘都创建了一个线程,专门负责这个磁盘的Page Cache的刷新工作,从而实现了每个磁盘的数据刷新在线程级的分离,提高了I/O性能。
IO调度层
I/O调度层的功能是管理块设备的请求队列。
内核不会一旦接收到I/O请求后,就按照请求的次序发起块I/O请求。为此Linux实现了几种I/O调度算法,算法基本思想就是通过合并和排序I/O请求队列中的请求,以此大大降低所需的磁盘寻道时间,从而提高整体I/O性能。
在许多的开源框架如Kafka、HBase中,都通过追加写的方式来尽可能的将随机I/O转换为顺序I/O,以此来降低寻址时间和旋转延时,从而最大限度的提高IOPS。
常见的I/O调度算法包括Noop调度算法(No Operation)、CFQ(完全公正排队I/O调度算法)、DeadLine(截止时间调度算法)、AS预测调度算法等。

7.磁盘碎片整理
在初始安装操作系统后,文件就会被不断的创建和清除,于是磁盘会产生很多的碎片,在创建一个文件时,它使用的块会散布在整个磁盘上,降低性能。删除文件后,回收磁盘块,可能会造成空穴。
磁盘性能可以通过如下方式恢复:移动文件使它们相互挨着,并把所有的至少是大部分的空闲空间放在一个或多个大的连续区域内。Windows 有一个程序 defrag 就是做这个事儿的。
磁盘碎片整理程序会在让文件系统上很好地运行。Linux 文件系统(特别是 ext2 和 ext3)由于其选择磁盘块的方式,在磁盘碎片整理上一般不会像 Windows 一样困难,因此很少需要手动的磁盘碎片整理。而且,固态硬盘并不受磁盘碎片的影响,事实上,在固态硬盘上做磁盘碎片整理反倒是多此一举,不仅没有提高性能,反而磨损了固态硬盘。所以碎片整理只会缩短固态硬盘的寿命。