实验目的
熟悉hbase表格设计的方法
熟悉hbase的javaAPI
通过API理解掌握hbase的数据的逻辑视图
了解MVC的服务端设计方式
实验原理
上次我们已经初步设计了学生选课案例的,具体功能还不完善,但是实现方式都是在已经设计好的表格之上,调用hbase已有的API,本次我们将会实现一个稍微复杂的业务逻辑,类似新浪微博的项目。实际上新浪微博是一个特别庞大的系统,光内存数据库Redis就有几千台集群,每天的访问量和流量几乎是全国最高的网站,这样一个复杂的集群架构也特别复杂,我们只是实现最基本简单的发微博、刷微博、关注等功能。
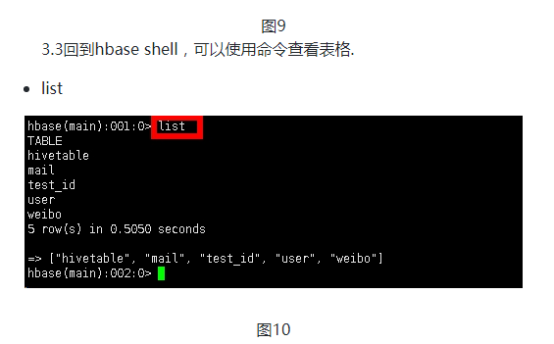
1.表格设计
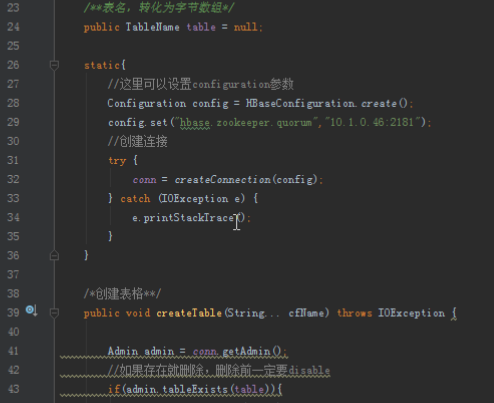
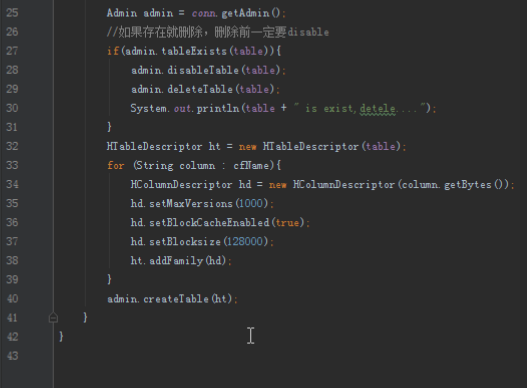
上次我们设计过表格,在大数据的业务中,通过牺牲空间多存副本来加快访问时间是比较常见的一种做法。所以首先我们需要有用户表,用户表的rowkey是用户id,一个列族是用户信息,另两个列族是粉丝和关注。同理还要有微博表,微博表的rowkey是微博id,第一个列族是微博的信息,包括内容、时间、评论等。同时,为了访问方便我们需要另外添加一个收件箱表,收件箱表的rowkey为用户id,列族可以根据业务的需求自己添加,例如添加用户发过的微博,用户收到的微博,用户收到的评论等,这个表只是为了加快访问速度,里面的数据都是别的地方保存过的,我们可以利用hbase的时间版本来记录多个消息。例如每个用户收到的微博,我们可以设置最大时间版本为1000,这样每个用户就能收到最近的一千条消息,这一千条消息都放在一个单元格cell内。
2.业务逻辑实现
表格设计好后就是逻辑实现(大家注意hbase表格的列和列族都可以动态添加,但是rowkey很难修改,所以设计的时候要特别注意rowkey的设计),业务逻辑我们主要实现以下几个:关注、发微博、刷微博、查看粉丝列表。
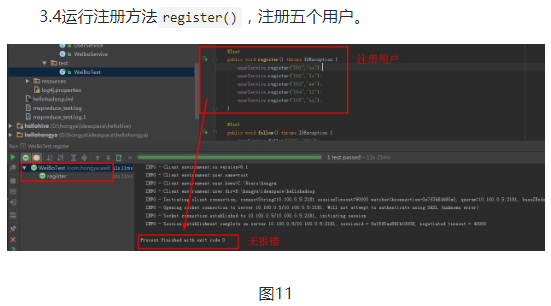
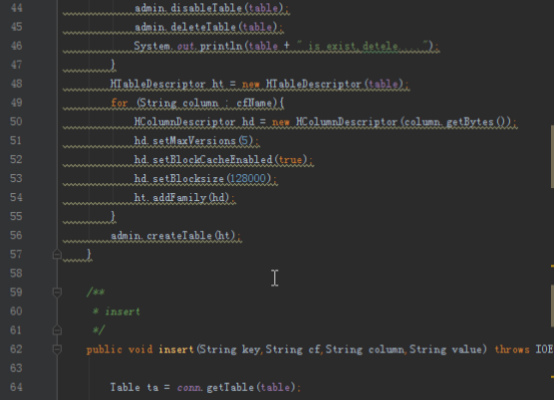
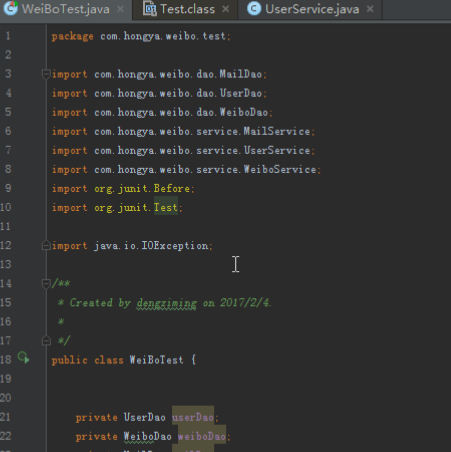
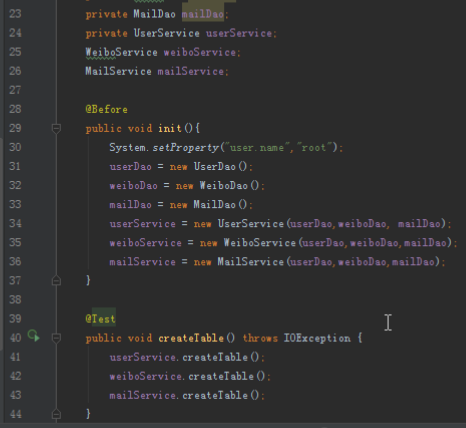
首先是创建三个表格,用户表三个列族:用户信息和粉丝、关注,微博表一个列族:微博信息。收件箱表两个列族:收件和发件。然后创建用户模拟用户注册。
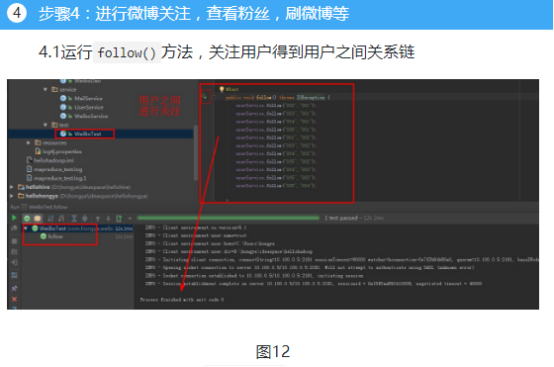
第一,关注。关注的时候,需要在对应的粉丝表和关注表添加记录(实际业务还需要将关注人的微博放进收件箱)。
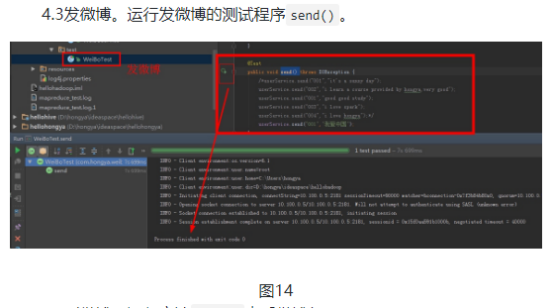
第二,发微博。发微博需要在自己的发件箱和粉丝的收件箱添加记录。
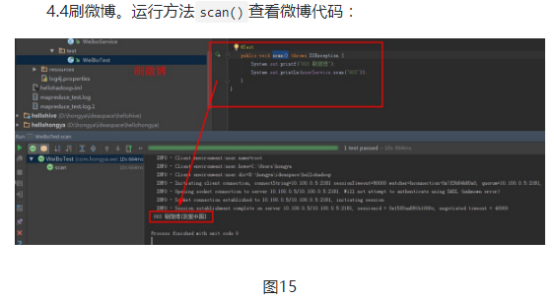
第三,刷微博。刷微博只需要找到收件箱显示。
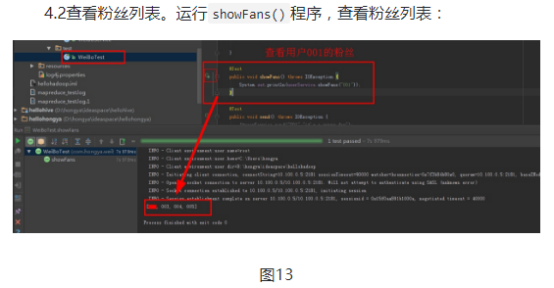
第四,查看粉丝列表。同理,只需要找到对应列族显示。
3.dao层的实现
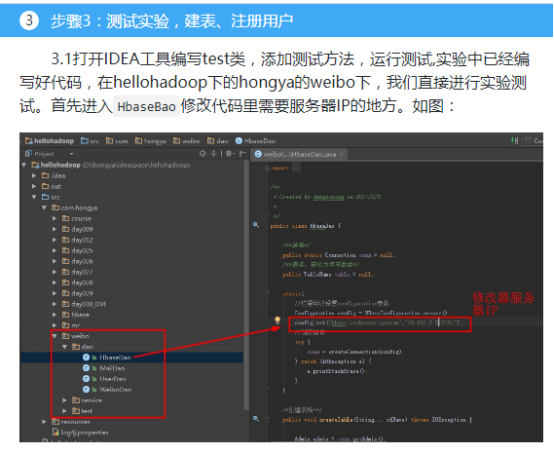
(本次实验的代码放在hellohadoop下的hongya的weibo下,大家可以作为参考)
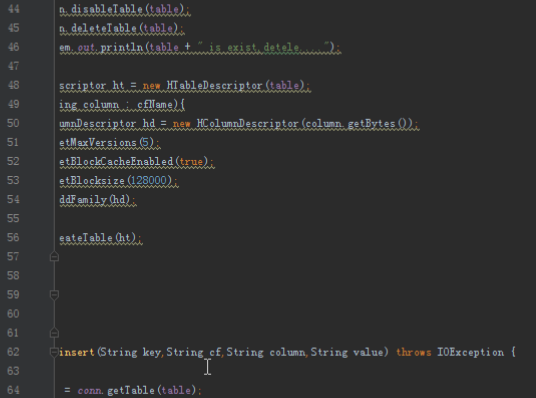
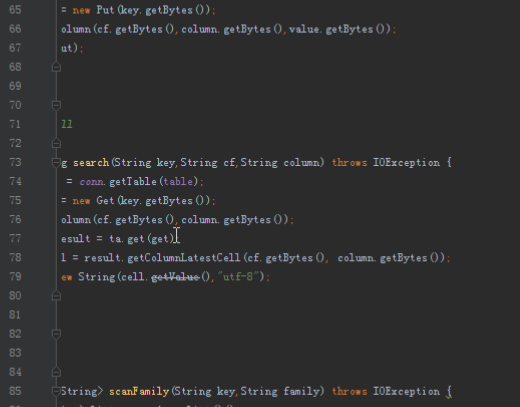
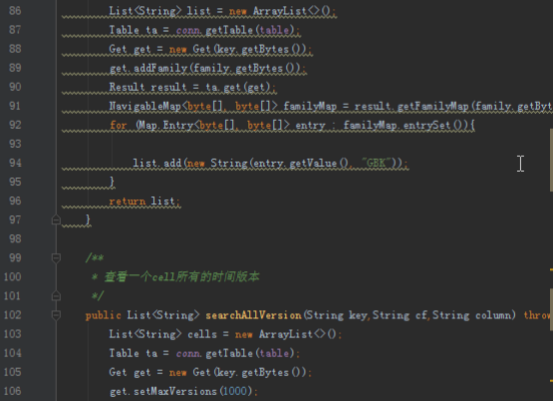
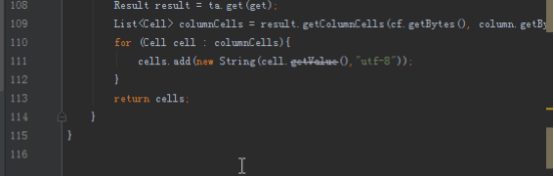
dao层为数据库访问对象,实现方法和上一个项目类似,但是由于新的项目需求比较多而且更复杂,需要添加和修改几个功能。上次的代码中没有访问每个单元格所有的时间版本的方法,由于我们的收件箱需要这个功能,所以需要添加。另外我们创建表格默认时间版本是5,而收件箱和发件箱需要将时间版本修改为1000,所以需要重写方法。查看所有的时间版本的方法为getColumnCells,对应实现如下:
public List<String> searchAllVersion(String key,String cf,String column) {
List<String> cells = new ArrayList<>();
Table ta = conn.getTable(table);
Get get = new Get(key.getBytes());
get.addColumn(cf.getBytes(),column.getBytes());
Result result = ta.get(get);
List<Cell> columnCells = result.getColumnCells(cf.getBytes(), column.getBytes());
for (Cell cell : columnCells){
cells.add(new String(cell.getValueArray(),"utf-8"));
}
return cells;
}
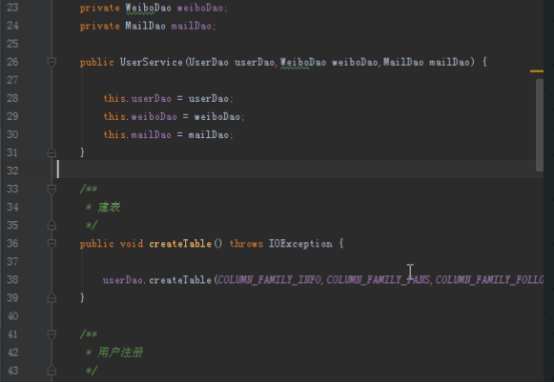
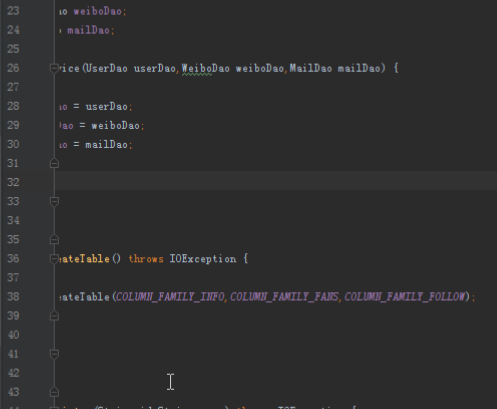
4.service层的实现
由于业务需求较多,所以service也会比较复杂,这和实际生产条件下的代码书写规范也是一样的。每个service的具体方法只需要具体调用dao的逻辑进行组合即可。
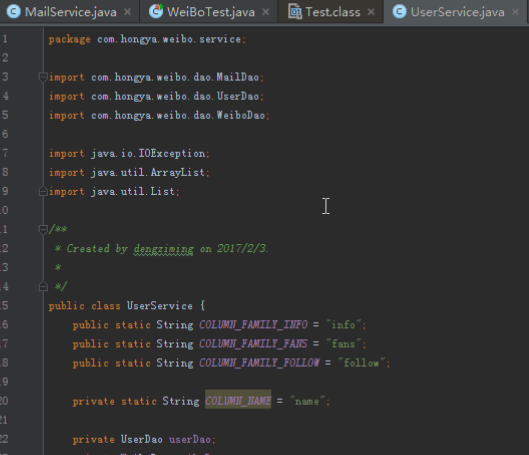
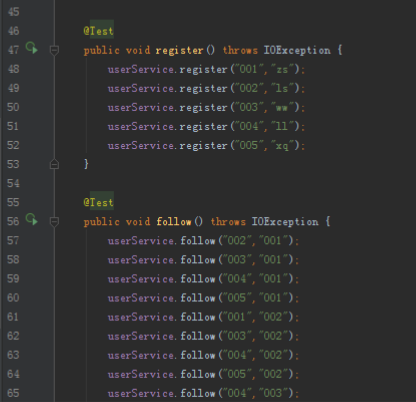
1)用户注册:
public void register(String id,String name) throws IOException {
userDao.insert(id,COLUMN_FAMILY_INFO,COLUMN_NAME,name);
}
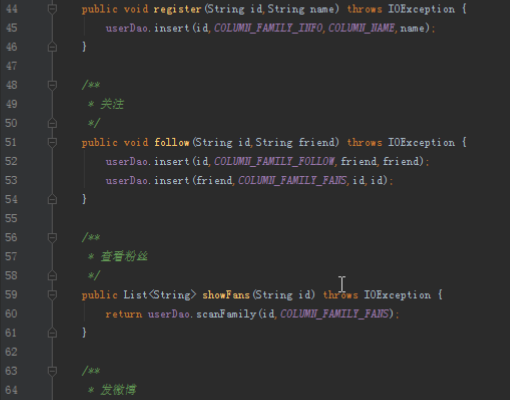
2)关注某个用户,需要在自己的关注列族和对应用户的粉丝列族添加相应记录:
public void follow(String id,String friend) throws IOException {
userDao.insert(id,COLUMN_FAMILY_FOLLOW,friend,friend);
userDao.insert(friend,COLUMN_FAMILY_FANS,id,id);
}
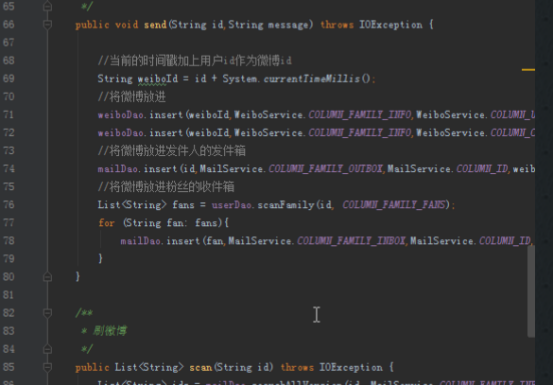
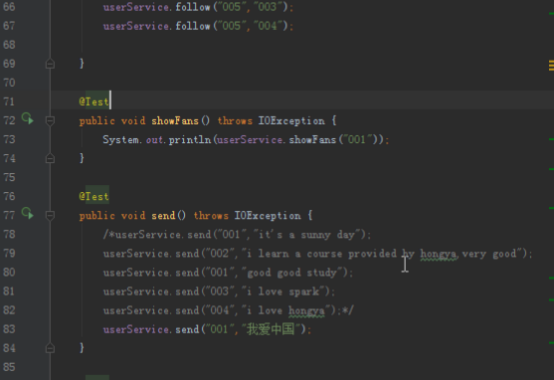
3)发微博需要在自己的发件箱和粉丝的收件箱添加记录,还需要在微博表添加记录:
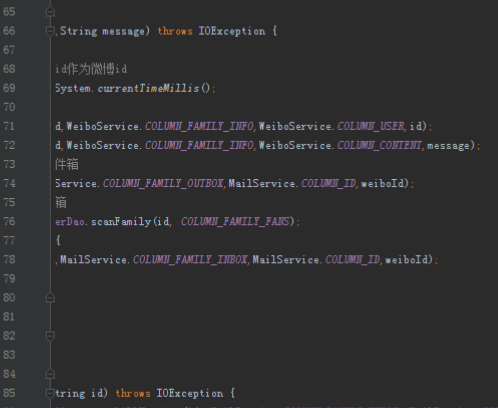
public void send(String id,String message) {
//当前的时间戳加上用户id作为微博id
String weiboId = id + System.currentTimeMillis();
//将微博放进微博表
weiboDao.insert(weiboId,WeiboService.COLUMN_FAMILY_INFO,WeiboService.COLUMN_USER,id);
weiboDao.insert(weiboId,WeiboService.COLUMN_FAMILY_INFO,WeiboService.COLUMN_CONTENT,message);
//将微博放进发件人的发件箱
mailDao.insert(id,MailService.COLUMN_FAMILY_OUTBOX,MailService.COLUMN_ID,weiboId);
//将微博放进粉丝的收件箱
List<String> fans = userDao.scanFamily(id, COLUMN_FAMILY_FANS);
for (String fan: fans){
mailDao.insert(fan,MailService.COLUMN_FAMILY_INBOX,MailService.COLUMN_ID,weiboId);
}
}
4)刷微博就只需要找到收件箱表的微博id,然后在微博表找到对应内容
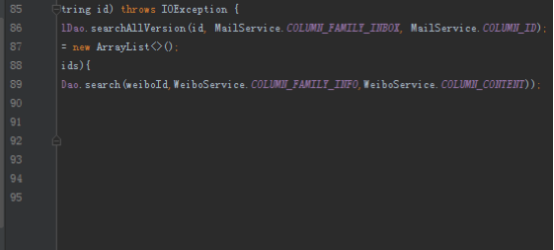
public List<String> scan(String id) {
List<String> ids = mailDao.searchAllVersion(id, MailService.COLUMN_FAMILY_INBOX, MailService.COLUMN_ID);
List<String> messages = new ArrayList<>();
for (String weiboId : ids){
messages.add(weiboDao.search(weiboId,WeiboService.COLUMN_FAMILY_INFO,WeiboService.COLUMN_CONTENT));
}
return messages;
}
实验环境
1.操作系统
服务器:Linux_Centos
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
1.Xshell

Xshell是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。 Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。实验中我们用到XShell5,其新增功能有:
1.有效保护信息安全性;Xshell支持各种安全功能,如SSH1/SSH2协议,密码,和DSA和RSA公开密钥的用户认证方法,并加密所有流量的各种加密算法。重要的是要保持用户的数据安全与内置Xshell安全功能,因为像Telnet和Rlogin这样的传统连接协议很容易让用户的网络流量受到任何有网络知识的人的窃取。Xshell将帮助用户保护数据免受黑客攻击。
2.最好的终端用户体验;终端用户需要经常在任何给定的时间中运用多个终端会话,以及与不同主机比较终端输出或者给不同主机发送同一组命令。Xshell则可以解决这些问题。此外还有方便用户的功能,如标签环境,广泛拆分窗口,同步输入和会话管理,用户可以节省时间做其他的工作。
3.代替不安全的Telnet客户端;Xshell支持VT100,VT220,VT320,Xterm,Linux,Scoansi和ANSI终端仿真和提供各种终端外观选项取代传统的Telnet客户端。
4. Xshell在单一屏幕实现多语言;Xshell中的UTF-8在同类终端软件中是第一个运用的。用Xshell,可以将多种语言显示在一个屏幕上,无需切换不同的语言编码。越来越多的企业需要用到UTF-8格式的数据库和应用程序,有一个支持UTF-8编码终端模拟器的需求在不断增加。Xshell可以帮助用户处理多语言环境。 5. 支持安全连接的TCP/IP应用的X11和任意;在SSH隧道机制中,Xshell支持端口转发功能,无需修改任何程序,它可以使所有的TCP/IP应用程序共享一个安全的连接。
2.Hive

Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。另外一个是Windows注册表文件。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。 Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
3.Hadoop

Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算
4.Hbase

HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase–Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
5.IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
步骤1:实验环境介绍
实验中已经安装了hbase的集群(可能是伪分布式或者完全分布式),基于这个集群进行实验。
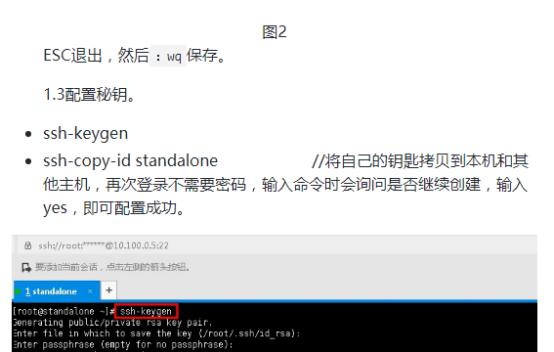
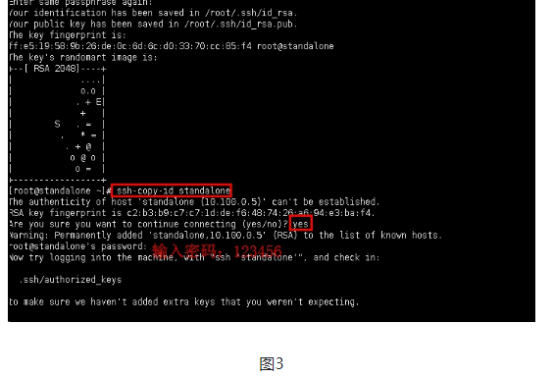
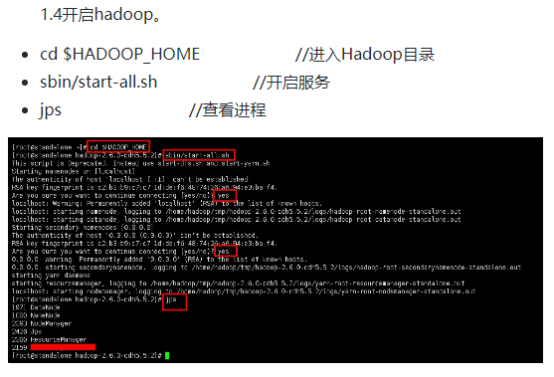
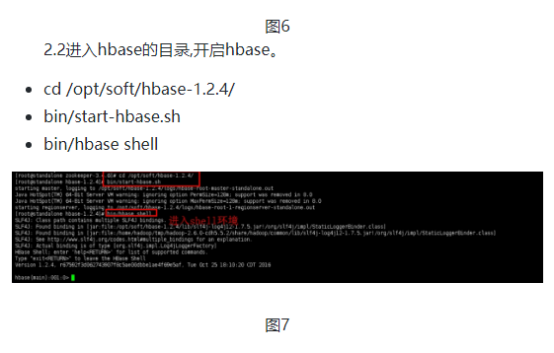
首先打开IDEA,按照以前的方式新建项目,添加jar包依赖,本次实验的代码已经放在hellohadoop的com.hongya的course下,实验中我们以这个代码为例进行学习。然后打开xshell,连上集群后,按照前面的学习内容,依次启动zookeeper、hadoop、hbase。
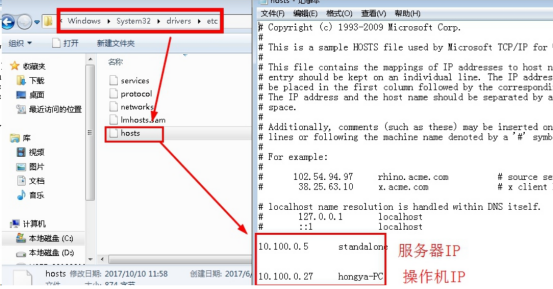
1.1编辑操作机本地hosts文件(C:WindowsSystem32driversetc下)。