需要识别的数字已经使用图形处理软件,处理成具有相同的色 彩和大小® : 宽髙是32像 素 *32像素的黑白图像。尽管采用文本格式存储图像不能有效地利用内 存空间,但是为了方便理解,我们还是将图像转换为文本格式。


准备数据:将图像转换为测试向量
每个数字大约有200个样本;目录中包含了大约900个测试
数据。我们使用目录比testDigits的数据训练分类器,使用目录把testDigits的数据测试分类器
的效果。两组数据没有覆盖,你可以检查一下这些文件夹的文件是否符合要求。

我们将把一个32*32的二进制图像矩阵转换为1 * 1024的向量

def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i in range(32): lineStr = fr.readline() for j in range(32): returnVect[0,32*i+j] = int(lineStr[j]) return returnVect
returnVect = img2vector("F:\machinelearninginaction\Ch02\trainingDigits\3_48.txt") print(returnVect)
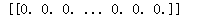
测 试 算 法 : 使 用 尽 近 邻 算 法 识 别 手 写 数 字
import numpy as np def handwritingClassTest(): hwLabels = [] trainingFileList = listdir('F:\machinelearninginaction\Ch02\trainingDigits') #load the training set m = len(trainingFileList) trainingMat = np.zeros((m,1024)) for i in range(m): fileNameStr = trainingFileList[i] fileStr = fileNameStr.split('.')[0] #take off .txt classNumStr = int(fileStr.split('_')[0]) hwLabels.append(classNumStr) trainingMat[i,:] = img2vector('F:\machinelearninginaction\Ch02\trainingDigits\%s' % fileNameStr) testFileList = listdir('F:\machinelearninginaction\Ch02\testDigits') #iterate through the test set mTest = len(testFileList) errorCount = 0.0 for i in range(mTest): fileNameStr = testFileList[i] fileStr = fileNameStr.split('.')[0] #take off .txt classNumStr = int(fileStr.split('_')[0]) vectorUnderTest = img2vector('F:\machinelearninginaction\Ch02\testDigits\%s' % fileNameStr) classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)) if (classifierResult != classNumStr): errorCount += 1.0 print(" the total number of errors is: %d" % errorCount) print(" the total error rate is: %f" % (errorCount/float(mTest))) handwritingClassTest()
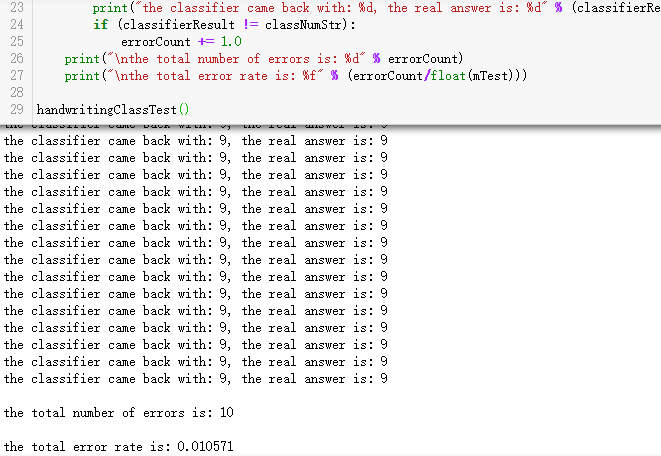
错误率大约是1.6左右,可以说是很不错的准确率了。
小结:
K-近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数
据。A-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外,
由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。
K近邻算法的另一个缺陷是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均
实例样本和典型实例样本具有什么特征。