用 df.va lue s 读取数据的前提是必须知道学生及科目的位置,非常麻烦 。 而 df.loc
可直接通过行、列标题读取数据,使用起来更为方便 。
使用 df.loc 的语法为:

行标题或列标题若是包含多个项目,则用小括号将项目括起来,项目之间以逗
号分隔,如“( ” 数学 ” , ” 自然 ”) ”;若要包含所有项目,则用冒号“.”表示。
例如读取学生陈聪明的所有成绩:
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('df.loc["陈聪明", :] ->')
print(df.loc["陈聪明", :])

print('df.loc["陈聪明"]["数学"] ->')
print(df.loc["陈聪明"]["数学"])
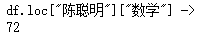
print('df.loc[("陈聪明", "熊小娟") ->')
print(df.loc[("陈聪明", "熊小娟"), :])

print('df.loc[:, "数学"] ->')
print(df.loc[:, "数学"])
print()
print('df.loc[("陈聪明", "熊小娟"), ("数学", "自然")] ->')
print(df.loc[("陈聪明", "熊小娟"), ("数学", "自然")])
print()

读取学生陈聪明到熊小娟的数学科目到社会科目的成绩 :
print('df.loc["陈聪明":"熊小娟", "数学":"社会"] ->')
print(df.loc["陈聪明":"熊小娟", "数学":"社会"])

读取从头到黄美丽的学生 , 及其从数学科目到社会科目 的成绩 :
print('df.loc[:黄美丽, "数学":"社会"] ->')
print(df.loc[:"黄美丽", "数学":"社会"])

读取从陈聪明到最后 的学生 ,他们 的数学科目 到社会科 目 的成绩 :
print('df.loc["陈聪明":, "数学":"社会"] ->')
print(df.loc["陈聪明":, "数学":"社会"])

用 df.iloc 通过行、列位置读取数据
df. iloc 是以行、列位置读取数据的 ,语法为 :
df. iloc 的用法与 df.loc 完全相同,只需要把 “ 标题 ” 改为“位置”即可。例如 ,
读取陈聪明(第 2 位学生〉的所有成绩 :
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('df.iloc[1, :] ->')
print(df.iloc[1, :])

print('df.iloc[1][1] ->')
print(df.iloc[1][1])
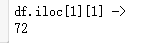
用 df.ix 通过行、列标题或行、列位置读取数据
df.ix 是 df. loc 及 df. iloc 的合体,以行、列标题或行、列位置的方式都可以读取
读取数据,语法为 :
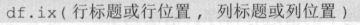
df. i x 的用法与 d f. lo c 完全相同 。 例如 , 读取陈聪明(第 2 位学生〉的数学(第 2
个科目)成绩,通过下列 4 种语法都可以实现 :
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('陈聪明的数学科成绩 ->')
print(df.ix["陈聪明"]["数学"])
print(df.ix["陈聪明"][1])
print(df.ix[1]["数学"])
print(df.ix[1][1])

读取最前面或最后面的几行数据
如果要读取最前面几行数据,可使用 head 方法,语法为:

参数 n 可有可无,表示读取最前面 n 行数据,若省略默认读取 5 行数据 。 例如,
读取最前面 2 个学生成绩(林大明及陈聪明) :
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('最前 2 位学生成绩 ->')
print(df.head(2))

若要读取最后面几行数据, 则使用 tail 方法,语法为 :

print('最后 2 位学生成绩 ->')
print(df.tail(2))
