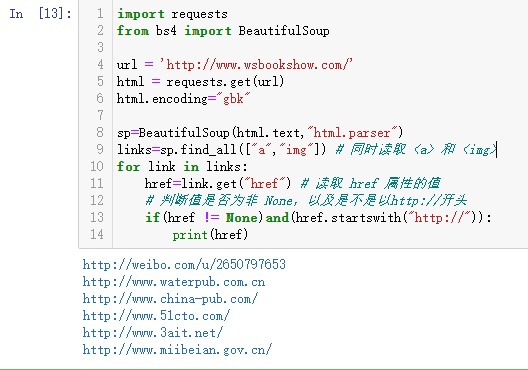
抓取万水书苑网页中所有<a>标签中的超链接井显示。
import requests from bs4 import BeautifulSoup url = 'http://www.wsbookshow.com/' html = requests.get(url) html.encoding="gbk" sp=BeautifulSoup(html.text,"html.parser") links=sp.find_all(["a","img"]) # 同时读取 <a> 和 <img> for link in links: href=link.get("href") # 读取 href 属性的值 # 判断值是否为非 None,以及是不是以http://开头 if(href != None)and(href.startswith("http://")): print(href)