我们所抓取的网页源代码一般都是 HTML 格式的文件,只要研究明白 HTML 中
的标签( Tag )结构,就很容易进行解析并取得所需数据 。
HTML 网页结构
HTML 网 页是由许多标签( Tag )构成,标签需用 。字符括起来 。 大部分标签
成对出现,与开始标签对应的结束标签前多 一个“/ ” 字符,例如 < html><斤itml>。 少
数标签非成对出现 ,如 <i mg src=’’image. g”〉 。 HTML 网页主要结构如下 :


比较简单的标签如“<title >标题</title >”,只包含标签名称及其内容,并没有属 性;有些较复杂的标签,除标签本身外,还包含了一些属性, 如“<img src="image. jpg” alt=”图片说明” width=200px height=320px>”,其中 的 scr 、 alt 、 width 、 height 都 是 i mg 标签的属性 。
从网页开发界面查看网页源代码 当使用 QQ/ IE/Firefox 浏览器浏览某个网站时,按下 F12 键就会打开网页的开发 界面。我们以 QQ 浏览器为例,第 一 次打开开发界面时会默认停留在开发界面中的 Elements 菜单,此时我们就可以看到该网页的 HTML 源代码 。 以百度搜索网站的首页为例,我们希望从网页中取得该网页的标题名称,那么 我们可以进行如下操作: 在 QQ 浏览器中输入 www.baidu.com ,打开百度网 。 然后我们按 F12 键, 打开网页的开发界面,单击 Elements 菜单,在代码中展开<head>标签。
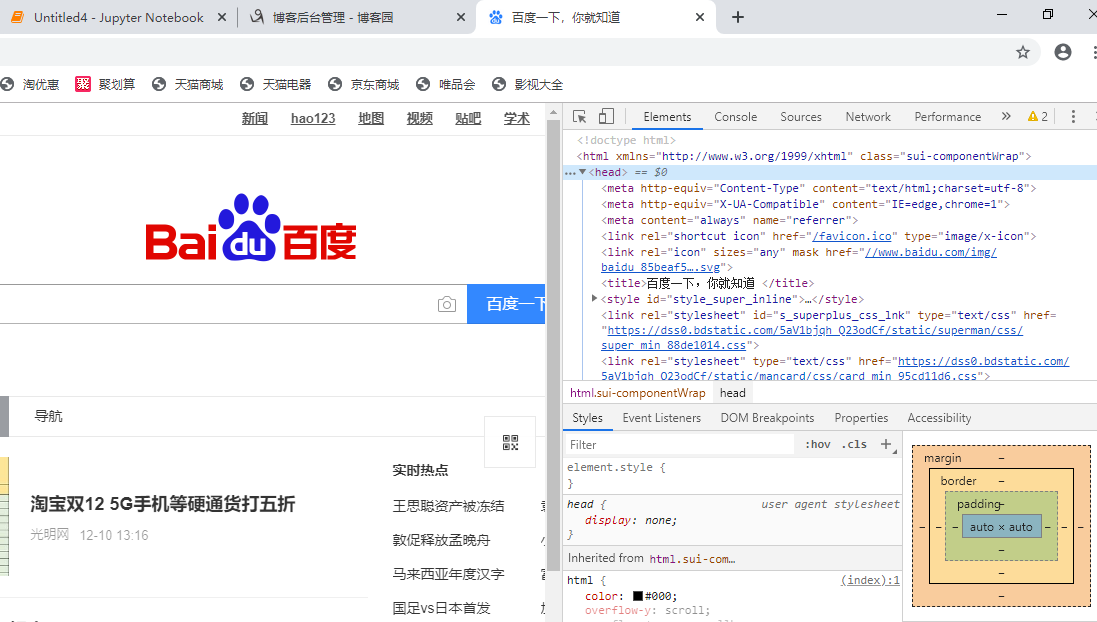
在<head> 标签下,我们可以看到该页面的<title> </title >标签内包含了
我们在页面中看到的“百度一下,你就知道”标题内容。
通过鼠标右键查看源代码

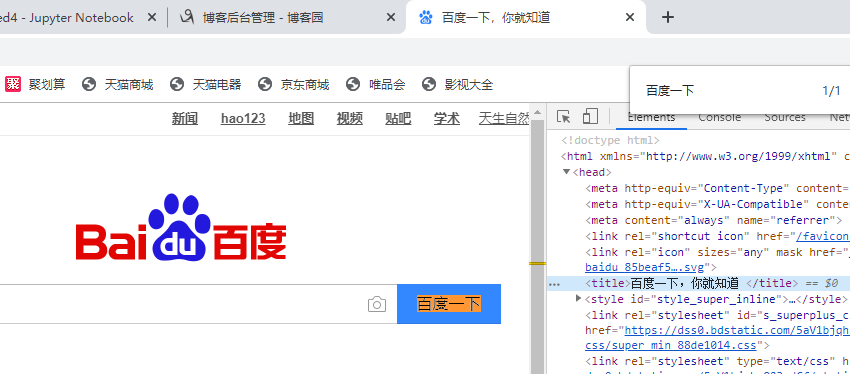
试用 BeautifulSoup 进行网页抓取与解析
如果 需 抓取的数据较复杂,我们可以用 一 个功能更强的网页解析工具
BeautifulSoup 来对特定 的目标进行抓取和分析 。
使用 BeautifulSoup
导入 BeautifulSoup 后,先用 requests 包中的 get 方 法取得网页源码,然后就
可以用 Python 内 建的 html.parser 解析器对源代码进行解析,解析的结果返回到
Beautiful Soup 类对象 S p 中 。语法格式如下 :

例如:创建 BeautifulSoup 类对象 Sp ,解析“htttp://www.baidu.com ”网页源代码 。
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com' html = requests.get(url) sp = BeautifulSoup(html.text, 'html.parser')
BeautifulSoup 的属性和方法
BeautifulSoup 常用的属性和方法如下 : (表中假设己创 建 BeautifulSoup 类的对
象 s p)


select 方法
select 方法通过 css 样式表的方式抓取指定数据 , 它的返回值是列表。
例如 :抓取<title> 的内 容。
datal = sp.select (” title”)
select 方法可以抓取指定的 id ,因为 id 是唯一的 ,所以抓取结果最精确。例如 : 抓取 id 为 rightdown 的网页源代码内 容,注意 id 前必须力口气” 符号。 datal = sp . select (”#rightdown ”)
可以通过 css 类的类名 title 进行搜索。例如 :

还可以使用 tag 标签逐层搜索。例如 :
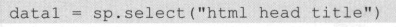
为了方便讲解,我们通过下面例子来说明 。假设 HTML 原始码如下 , 井创 建
Beautiful Soup 对象 sp :
html_doc = """ <html><head><title>页标题</title></head> <p class="title"><b>文件标题</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p>
from bs4 import BeautifulSoup sp = BeautifulSoup(html_doc,'html.parser')
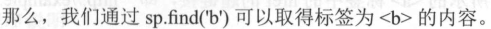
print(sp.find('b')) # 返回值:<b>文件标题</b>


print(sp.find_all('a'))

用 find_all( tag, {属性名称:属性内容})可以抓取所有符合属性规定的 tag 内 容。
注意其中第二个参数是字典型数据。所以 ,上例功能还可通过下面的代码实现:
print(sp.find_all("a", {"class":"sister"}))


data1=sp.find("a", {"href":"http://example.com/elsie"}) print(data1.text) # 返回值:Elsie


data2=sp.find("a", {"id":"link2"}) print(data2.text) # 返回值:Lacie


data3 = sp.select("#link3") print(data3[0].text) # 返回值:Tillie


print(sp.find_all(['title','a']))


data1=sp.find("a", {"id":"link1"}) print(data1.get("href")) #返回值: http://example.com/elsie
