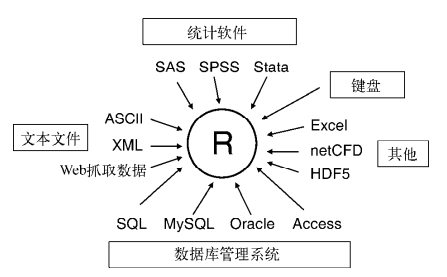
R可从键盘、文本文件、Microsoft Excel和Access、流行的统计软件、特殊格
式的文件、多种关系型数据库管理系统、专业数据库、网站和在线服务中导入数据。
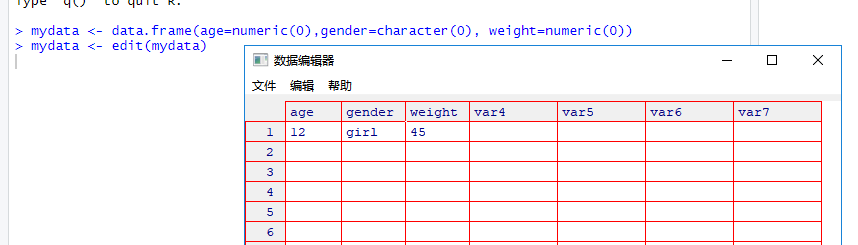
使用键盘了。有两种常见的方式:用R内置的文本编辑器和 直接在代码中嵌入数据。我们首先考虑文本编辑器。 R中的函数edit()会自动调用一个允许手动输入数据的文本编辑器。具体步骤如下: (1) 创建一个空数据框(或矩阵),其中变量名和变量的模式需与理想中的最终数据集一致; (2) 针对这个数据对象调用文本编辑器,输入你的数据,并将结果保存回此数据对象中。 在下例中,你将创建一个名为mydata的数据框,它含有三个变量:age(数值型)、gender (字符型)和weight(数值型)。然后你将调用文本编辑器,键入数据,最后保存结果。
mydata <- data.frame(age=numeric(0),gender=character(0), weight=numeric(0))
mydata <- edit(mydata)
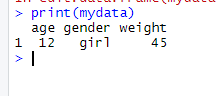
可以用编辑器修改变量名和变量类型(数值型、字符型)。还可以通 过单击未使用列的标题来添加新的变量。编辑器关闭后,结果会保存到之前赋值的对象中(本例 中为mydata)。再次调用mydata <- edit(mydata),就能够编辑已经输入的数据并添加新的 数据。语句mydata <- edit(mydata)的一种简捷的等价写法是fix(mydata)。
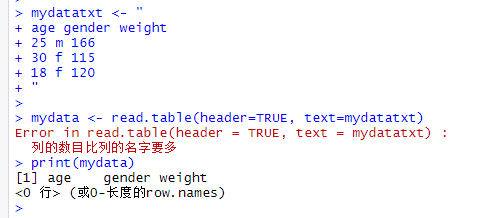
可以直接在你的程序中嵌入数据集。比如说,参见以下代码: mydatatxt <- " age gender weight 25 m 166 30 f 115 18 f 120 " mydata <- read.table(header=TRUE, text=mydatatxt) 一个字符型变量被创建于存储原始数据,然后read.table()函数被用于处理字符串并返回数据框。
从带分隔符的文本文件导入数据 可以使用read.table()从带分隔符的文本文件中导入数据。此函数可读入一个表格格式 的文件并将其保存为一个数据框。表格的每一行分别出现在文件中每一行。其语法如下: mydataframe <- read.table(file, options 其中,file是一个带分隔符的ASCII文本文件,options是控制如何处理数据的选项。


考虑一个名为studentgrades.csv的文本文件,它包含了学生在数学、科学、和社会学习的分数。 文件中每一行表示一个学生,第一行包含了变量名,用逗号分隔。每一个单独的行都包含了学生 8 的信息,它们也是用逗号进行分隔的。文件的前几行如下:
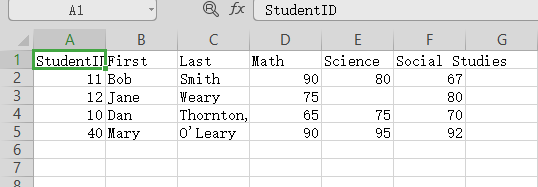
grades <- read.table("F:\R\data\datastudentgrades.csv", header=TRUE,row.names="StudentID", sep=",") # print data frame grades # view data frame structure str(grades)
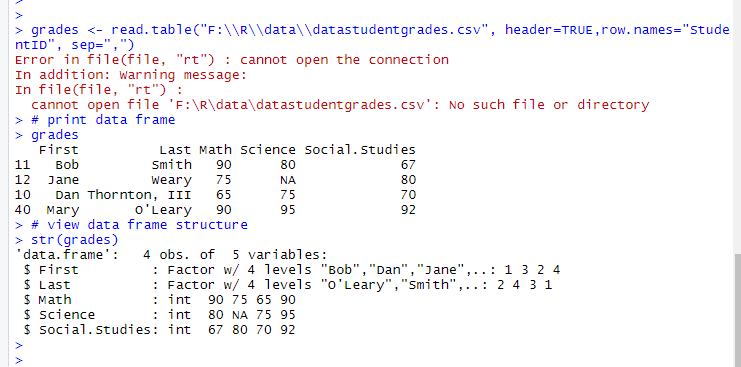
变量名Social Studies被自动地根据R的习惯所重命名。 列StudentID现在是行名,不再有标签,也失去了前置的0。Jane的缺失的科学课成绩被正确地 识别为缺失值。我不得不在Dan的姓周围用引号包围住,从而能够避免Thornton和III之间的空格。 否则,R会在那一行读出七个值而不是六个值。我也在O’Leary左右用引号包围住了,负载R会把 单引号读取为分隔符(而这不是我想要的)。最后,姓和名都被转化成为因子。 默认地,read.table()把字符变量转化为因子,这并不一定都是我们想要的情况。比如说, 很少情况下,我们才会把回答者的评论转化成为因子。你可用多种方法去掉这个行为。加上选项 stringsAsFactors=FALSE对所有的字符变量都去掉这个行为。此外,你可以用colClasses 选项去对每一列都指定一个类(比如说,逻辑型、数值型、字符型或因子型)。
grades <- read.table("F:\R\data\studentgrades.csv", header=TRUE,row.names="StudentID", sep=",", colClasses=c("character", "character", "character","numeric", "numeric", "numeric") ) # print data frame grades # view data frame structure str(grades)

