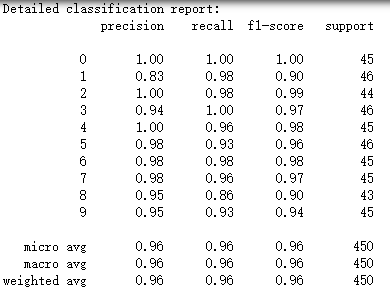
import scipy from sklearn.datasets import load_digits from sklearn.metrics import classification_report from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV,RandomizedSearchCV #模型选择参数优化随机搜索寻优RandomizedSearchCV模型 def test_RandomizedSearchCV(): ''' 测试 RandomizedSearchCV 的用法。使用 LogisticRegression 作为分类器,主要优化 C、multi_class 等参数。其中 C 的分布函数为指数分布 ''' ### 加载数据 digits = load_digits() X_train,X_test,y_train,y_test=train_test_split(digits.data, digits.target,test_size=0.25,random_state=0,stratify=digits.target) #### 参数优化 ###### tuned_parameters ={ 'C': scipy.stats.expon(scale=100), # 指数分布 'multi_class': ['ovr','multinomial']} clf=RandomizedSearchCV(LogisticRegression(penalty='l2',solver='lbfgs',tol=1e-6),tuned_parameters,cv=10,scoring="accuracy",n_iter=100) clf.fit(X_train,y_train) print("Best parameters set found:",clf.best_params_) print("Randomized Grid scores:") # for params, mean_score, scores in clf.fit_params,clf.mean_score,clf.score: # print(" %0.3f (+/-%0.03f) for %s" % (mean_score, scores() * 2, params)) # print(" %0.3f (+/-%0.03f) for %s" % (clf.mean_score,clf.score * 2, clf.fit_params)) print(clf) print("Optimized Score:",clf.score(X_test,y_test)) print("Detailed classification report:") y_true, y_pred = y_test, clf.predict(X_test) print(classification_report(y_true, y_pred)) #调用RandomizedSearchCV() test_RandomizedSearchCV()