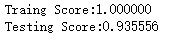
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklearn.model_selection import train_test_split def load_data_classification(): ''' 加载用于分类问题的数据集 ''' # 使用 scikit-learn 自带的 digits 数据集 digits=datasets.load_digits() # 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4 return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习随机森林RandomForestClassifier分类模型 def test_RandomForestClassifier(*data): X_train,X_test,y_train,y_test=data clf=ensemble.RandomForestClassifier() clf.fit(X_train,y_train) print("Traing Score:%f"%clf.score(X_train,y_train)) print("Testing Score:%f"%clf.score(X_test,y_test)) # 获取分类数据 X_train,X_test,y_train,y_test=load_data_classification() # 调用 test_RandomForestClassifier test_RandomForestClassifier(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_num(*data): ''' 测试 RandomForestClassifier 的预测性能随 n_estimators 参数的影响 ''' X_train,X_test,y_train,y_test=data nums=np.arange(1,100,step=2) fig=plt.figure() ax=fig.add_subplot(1,1,1) testing_scores=[] training_scores=[] for num in nums: clf=ensemble.RandomForestClassifier(n_estimators=num) clf.fit(X_train,y_train) training_scores.append(clf.score(X_train,y_train)) testing_scores.append(clf.score(X_test,y_test)) ax.plot(nums,training_scores,label="Training Score") ax.plot(nums,testing_scores,label="Testing Score") ax.set_xlabel("estimator num") ax.set_ylabel("score") ax.legend(loc="lower right") ax.set_ylim(0,1.05) plt.suptitle("RandomForestClassifier") plt.show() # 调用 test_RandomForestClassifier_num test_RandomForestClassifier_num(X_train,X_test,y_train,y_test)

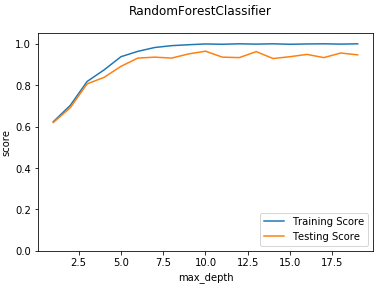
def test_RandomForestClassifier_max_depth(*data): ''' 测试 RandomForestClassifier 的预测性能随 max_depth 参数的影响 ''' X_train,X_test,y_train,y_test=data maxdepths=range(1,20) fig=plt.figure() ax=fig.add_subplot(1,1,1) testing_scores=[] training_scores=[] for max_depth in maxdepths: clf=ensemble.RandomForestClassifier(max_depth=max_depth) clf.fit(X_train,y_train) training_scores.append(clf.score(X_train,y_train)) testing_scores.append(clf.score(X_test,y_test)) ax.plot(maxdepths,training_scores,label="Training Score") ax.plot(maxdepths,testing_scores,label="Testing Score") ax.set_xlabel("max_depth") ax.set_ylabel("score") ax.legend(loc="lower right") ax.set_ylim(0,1.05) plt.suptitle("RandomForestClassifier") plt.show() # 调用 test_RandomForestClassifier_max_depth test_RandomForestClassifier_max_depth(X_train,X_test,y_train,y_test)
def test_RandomForestClassifier_max_features(*data): ''' 测试 RandomForestClassifier 的预测性能随 max_features 参数的影响 ''' X_train,X_test,y_train,y_test=data max_features=np.linspace(0.01,1.0) fig=plt.figure() ax=fig.add_subplot(1,1,1) testing_scores=[] training_scores=[] for max_feature in max_features: clf=ensemble.RandomForestClassifier(max_features=max_feature) clf.fit(X_train,y_train) training_scores.append(clf.score(X_train,y_train)) testing_scores.append(clf.score(X_test,y_test)) ax.plot(max_features,training_scores,label="Training Score") ax.plot(max_features,testing_scores,label="Testing Score") ax.set_xlabel("max_feature") ax.set_ylabel("score") ax.legend(loc="lower right") ax.set_ylim(0,1.05) plt.suptitle("RandomForestClassifier") plt.show() # 调用 test_RandomForestClassifier_max_features test_RandomForestClassifier_max_features(X_train,X_test,y_train,y_test)
