import numpy as np data = np.mat([[1,200,105,3,False], [2,165,80,2,False], [3,184.5,120,2,False], [4,116,70.8,1,False], [5,270,150,4,True]]) row = 0 for line in data: row += 1 print(row) print(data.size)

import numpy as np data = np.mat([[1,200,105,3,False], [2,165,80,2,False], [3,184.5,120,2,False], [4,116,70.8,1,False], [5,270,150,4,True]]) print(data[0,3]) print(data[0,4])
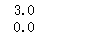
import numpy as np data = np.mat([[1,200,105,3,False], [2,165,80,2,False], [3,184.5,120,2,False], [4,116,70.8,1,False], [5,270,150,4,True]]) print(data) col1 = [] for row in data: print(row) col1.append(row[0,1]) print(col1) print(np.sum(col1)) print(np.mean(col1)) print(np.std(col1)) print(np.var(col1))

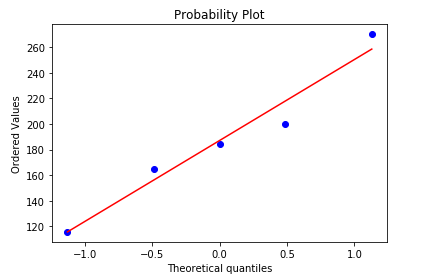
import pylab import numpy as np import scipy.stats as stats data = np.mat([[1,200,105,3,False], [2,165,80,2,False], [3,184.5,120,2,False], [4,116,70.8,1,False], [5,270,150,4,True]]) col1 = [] for row in data: col1.append(row[0,1]) stats.probplot(col1,plot=pylab) pylab.show()
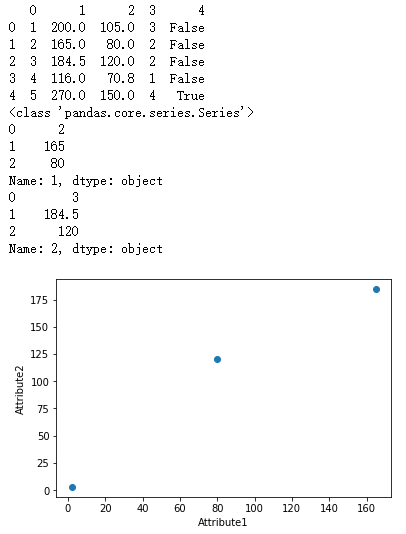
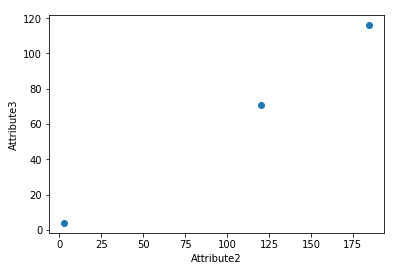
import pandas as pd import matplotlib.pyplot as plot rocksVMines = pd.DataFrame([[1,200,105,3,False], [2,165,80,2,False], [3,184.5,120,2,False], [4,116,70.8,1,False], [5,270,150,4,True]]) print(rocksVMines) dataRow1 = rocksVMines.iloc[1,0:3] dataRow2 = rocksVMines.iloc[2,0:3] print(type(dataRow1)) print(dataRow1) print(dataRow2) plot.scatter(dataRow1, dataRow2) plot.xlabel("Attribute1") plot.ylabel("Attribute2") plot.show() dataRow3 = rocksVMines.iloc[3,0:3] plot.scatter(dataRow2, dataRow3) plot.xlabel("Attribute2") plot.ylabel("Attribute3") plot.show()
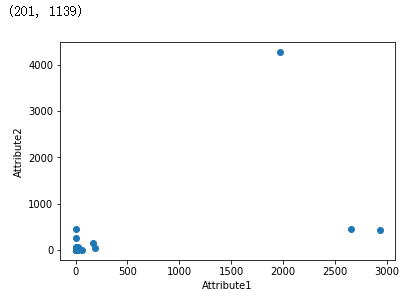
import numpy as np import pandas as pd import matplotlib.pyplot as plot filePath = ("G:\MyLearning\TensorFlow_deep_learn\data\dataTest.csv") dataFile = pd.read_csv(filePath,header=None, prefix="V") print(np.shape(dataFile)) dataRow1 = dataFile.iloc[100,1:300] dataRow2 = dataFile.iloc[101,1:300] plot.scatter(dataRow1, dataRow2) plot.xlabel("Attribute1") plot.ylabel("Attribute2") plot.show()
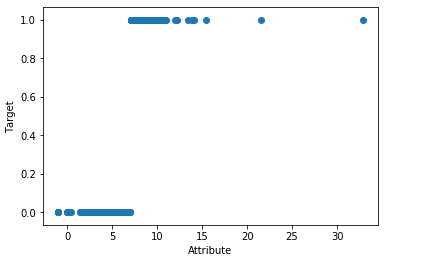
import pandas as pd import matplotlib.pyplot as plot filePath = ("G:\MyLearning\TensorFlow_deep_learn\data\dataTest.csv") dataFile = pd.read_csv(filePath,header=None, prefix="V") target = [] for i in range(200): if dataFile.iat[i,10] >= 7: target.append(1.0) else: target.append(0.0) dataRow = dataFile.iloc[0:200,10] plot.scatter(dataRow, target) plot.xlabel("Attribute") plot.ylabel("Target") plot.show()
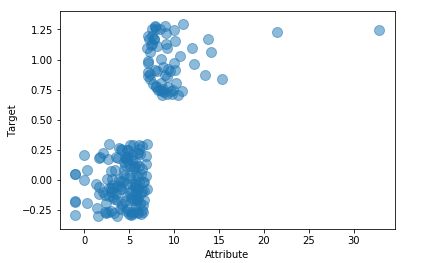
import random as rd import pandas as pd import matplotlib.pyplot as plot filePath = ("G:\MyLearning\TensorFlow_deep_learn\data\dataTest.csv") dataFile = pd.read_csv(filePath,header=None, prefix="V") target = [] for i in range(200): if dataFile.iat[i,10] >= 7: target.append(1.0 + rd.uniform(-0.3, 0.3)) else: target.append(0.0 + rd.uniform(-0.3, 0.3)) dataRow = dataFile.iloc[0:200,10] plot.scatter(dataRow, target, alpha=0.5, s=100) plot.xlabel("Attribute") plot.ylabel("Target") plot.show()
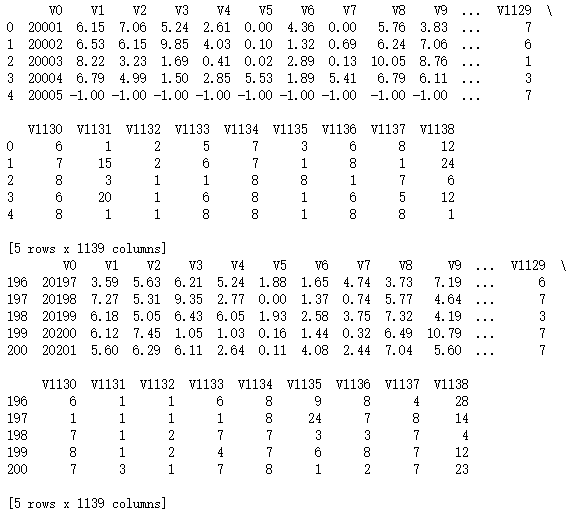
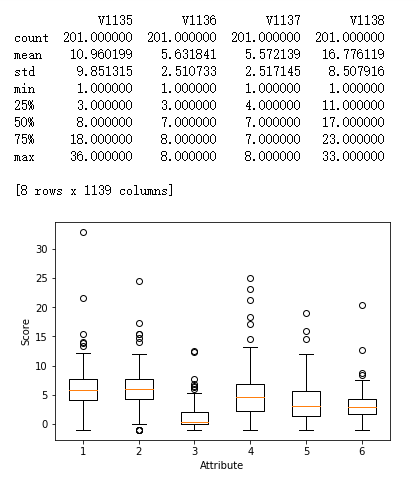
from pylab import * import pandas as pd import matplotlib.pyplot as plot filePath = ("G:\MyLearning\TensorFlow_deep_learn\data\dataTest.csv") dataFile = pd.read_csv(filePath,header=None, prefix="V") print(dataFile.head()) print(dataFile.tail()) summary = dataFile.describe() print(summary) array = dataFile.iloc[:,10:16].values boxplot(array) plot.xlabel("Attribute") plot.ylabel("Score") show()