import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(data.head())
a = data.stack()
print(a)
b = a.unstack()
print(b)

import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(data.head())
df = data.set_index("日期")
print(df.head())

import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
a = pd.pivot_table(data,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.info())

import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
print(data.head())

import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
a = data["价格"].groupby([data["出发地"],data["目的地"]]).mean()
print(a)

import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_route_cnt.csv")
print(data.head())

import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
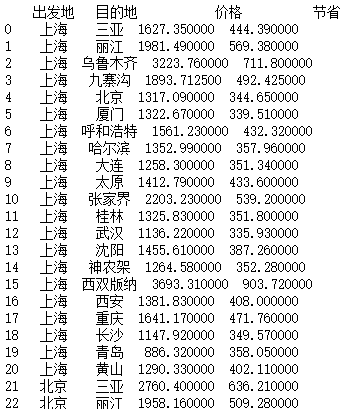
a = data.groupby([data["出发地"],data["目的地"]],as_index=False).mean()
print(a)
import pandas as pd
data = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_route_cnt.csv")
print(data.head())
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
print(data_1.head())
a = data_1.groupby([data_1["出发地"],data_1["目的地"]],as_index=False).mean()
print(a.head())
b = pd.merge(a,data)
print(b.head())

import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
a = pd.pivot_table(data_1,values=["价格"],index=["出发地"],columns=["目的地"])
print(a.head())

import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
a = pd.pivot_table(data_1[data_1["出发地"]=="杭州"],values=["价格"],index=["出发地","目的地"],columns=["去程方式"])
print(a)

import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(data_1.head())
print(data_1.isnull().head())
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.isnull())

import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=0)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=1)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
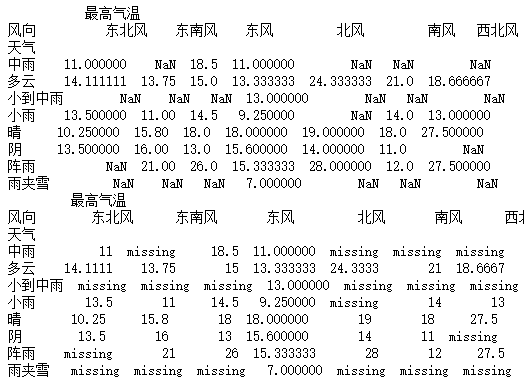
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna("missing")
print(b)
import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="pad")
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="bfill",limit=1)
print(b)

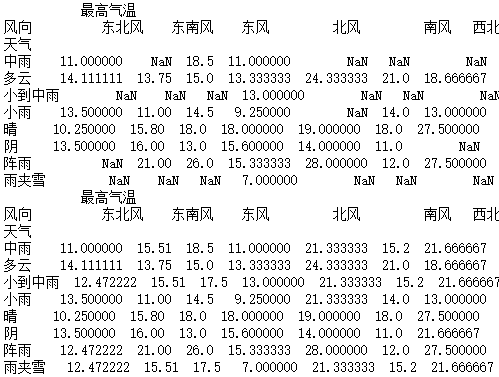
import pandas as pd
data_1 = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(a.mean())
print(b)
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(np.shape(df))
print(df.head())
fig,ax = plt.subplots(1,1,figsize=(8,5))
ax.hist(df["最低气温"],bins=20)
plt.show()
d = df["最低气温"]
zscore = (d-d.mean())/d.std()
df["isOutlier"]=zscore.abs()>3
print(df.head())
a = df["isOutlier"].value_counts()
print(a)


%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\sale_data.csv")
print(np.shape(df))
print(df.head())
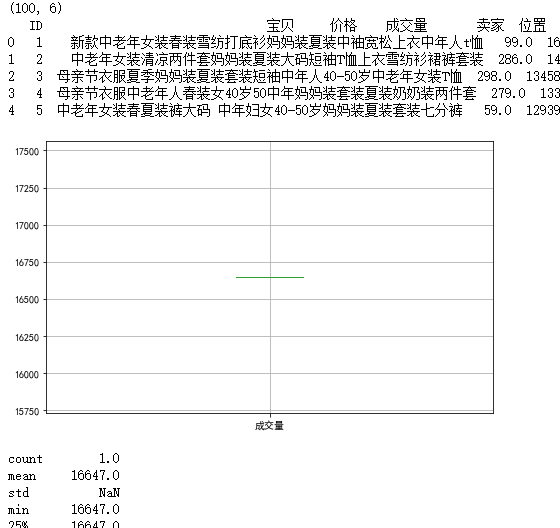
a = df[df["卖家"]=="夏奈凤凰旗舰店"]
fig,ax = plt.subplots(1,1,figsize=(8,5))
a.boxplot(column="成交量",ax=ax)
plt.show()
b = a["成交量"]
print(b.describe())
a["isOutlier"]=d>d.quantile(0.75)
c = a[a["isOutlier"]==True]
print(c)
import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(np.shape(df))
print(df.head())
a = df.duplicated()
print(np.shape(a))
print(a[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.duplicated()
print(b[:5])
import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.duplicated("最高气温")
print(b[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\hz_weather.csv")
print(type(df))
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.drop_duplicates("最高气温")
print(np.shape(b))
print(b.head())

import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
print(df.head())
print(df.info())

import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
a = df.duplicated().value_counts()
print(a)
import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
a = df.drop_duplicates()
b = a.duplicated().value_counts()
print(b)

import numpy as np
import pandas as pd
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
a = df.drop_duplicates()
print(a.describe())

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
print(np.shape(df))
fig,axes = plt.subplots(1,2,figsize=(12,5))
axes[0].hist(df["价格"],bins=20)
df.boxplot(column="价格",ax=axes[1])
plt.show()

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\python3_pachongAndDatareduce\data\pandas data\qunar_free_trip.csv")
d = df["价格"]
zscore = (d-d.mean())/d.std()
print(zscore[0:3])
df["isOutlier"]=zscore.abs()>3.5
print(df["isOutlier"].value_counts())
a = df[df["isOutlier"]==True]
print(a.head())
