fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
fasttext结构
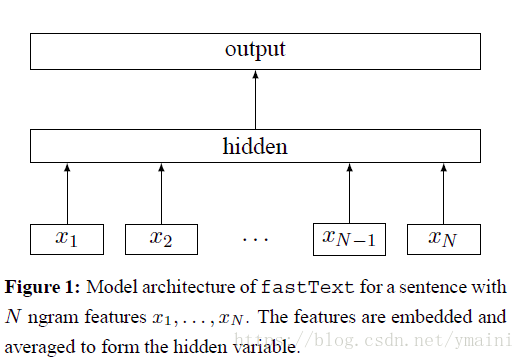
x
- $X_i$: 一个句子的特征,初始值为随机生成(也可以采用预训练的词向量)
- hidden:$X_i$的平均值 x
- output: 样本标签
目标函数

N:样本个数
$y_n$:第n个样本对应的类别
f:损失函数softmaxt
$x_n$:第n个样本的归一化特征
A:权重矩阵(构建词,embedding)
B:权重举证(隐层到输出层)
词向量初始化
一个句子的embedding为[$iw_1,iw_2,....iw_n,ow_1,ow_2,...ow_s$]
$iw_i$:语料中出现的词,排在数组的前面
$ow_i$:n-gram或n-char特征
初始化为随机数, 如果提供预训练的词向量,对应的词采用预训练的词向量
hierarchical Softmax

当语料类别较多时,使用hierarchical Softmax(hs)减轻计算量
hs利用Huffman 树实现,词(生成词向量)或label(分类问题)作为叶子节点
根据词或label的count构建Huffman 树,则叶子到root一定存在一条路径
利用逻辑回归二分类计算loss
n-gram和n-char
asttext方法不同与word2vec方法,引入了两类特征并进行embedding。其中n-gram颗粒度是词与词之间,n-char是单个词之间。两类特征的存储均通过计算hash值的方法实现。
n-gram
示例: who am I? n-gram设置为2
n-gram特征有,who, who am, am, am I, I
n-char
示例: where, n=3, 设置起止符<, >
n-char特征有,<wh, whe, her, ere, er>
FastText词向量与word2vec对比
FastText= word2vec中 cbow + h-softmax的灵活使用
模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是
分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用;
模型的输入层:word2vec的输入层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容;
两者本质的不同,体现在 h-softmax的使用。
Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax 也会生成一系列的向量,但最终都被抛弃,不会使用。
fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)。