一 .概述
在我们没有使用nio的时候,我们都是通过流来操作io的,我们会使用底层的字节数组进行操作.
但是java对于数组的api没有多少,因此需要我们手工去编写比较多的代码.
在nio之中,提出了真正的缓存区的概念,从本质上讲它依旧还是一个数组,只是一个被封装的对象而已.
在整个nio架构之中,缓冲区是唯一进行数据存储功能的地方,所有的io操作落实到最根本都是使用缓冲区进行操作的.
随着后面的进行,我们会发现缓冲区绝对不是简单的一个数组的封装对象那么简单.
二 . 缓冲区对象
在nio之中,使用Buffer对象来描述缓冲区对象.另外为此提供了一些列的实现对象,为了方便我们的使用,java为我们提供了除boolean之外的8中基本数据类型的实现.
我们看看基本的结构图:
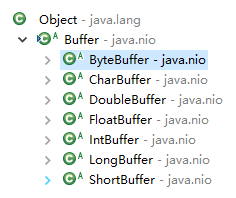
从上面的图中,我们可以看到,我们可以使用的对象有7种.
但是在nio之中,总是优先使用字节进行操作的,因此我们以后的使用过程之中,更多的会去使用ByteBuffer来完成我们的业务操作.
三 .缓冲区的属性
我们现在可以简单的认为缓冲区就是一个数组的封装(在后面我们会发现要比这个复杂很多).
为了描述缓冲区的状态,niio之中为缓冲区提供了4个属性的支持.
我们首先看看源码之中的定义内容:
private int mark = -1; private int position = 0; private int limit; private int capacity;
上面定义的4个成员变量就是描述缓冲区的状态信息.
下面,我们首先介绍一下这四个属性.
[1]capacity: 这个属性表示的就是封装的数组的大小,也就是说,一旦我们创建了缓冲区之后,我们的缓冲区的该属性就不会变化.
看下面简单了例子:
ByteBuffer buffer = ByteBuffer.allocate(1024); System.out.println(buffer.capacity()); //1024
我们创建了一个缓冲区,然后分配的就是一个1024字节的缓冲区,然后我们可以通过capacity属性获取数组的大小.
对于缓冲区的创建,在后面我们会详细的说明.
[2]limit: 表示在读状态或写状态下范围的一个索引值,我们也可以理解为第一个不可使用的位置.
看下面的例子:
ByteBuffer buffer = ByteBuffer.allocate(3); // 创建的缓冲区的状态为写状态 System.out.println("init limit:" + buffer.limit()); // init limit:3 buffer.put("a".getBytes()); buffer.flip(); System.out.println("flip limit " + buffer.limit()); //flip limit 1
在上面的例子之中,我们首先创建了3字节的缓冲区,然后我们打印初始的limit属性,发现是3.然后我们放入了一个字节,然后改变缓冲区的读写状态,再获取limit属性,发现变成了1.
现在,我们可以知道limit属性描述的就是读写状态的限制值.
[3]position: 位置,表示的当前状态下数组的角标值.
我们看下面的例子:
ByteBuffer buffer = ByteBuffer.allocate(2); System.out.println("init position:"+buffer.position()); //init position:0 buffer.put("1".getBytes()); System.out.println("add 1 after position:"+buffer.position()); //add 1 after position:1 buffer.flip(); System.out.println("flip after position:"+buffer.position()); //flip after position:0
从上面的例子之中,可以看到我们position属性表示的就是读写状态下当前的数组的角标的位置,它总是随着读写状态再不断改变.
[4]mark:一个标记状态字,我们可以通过方法返回到之前的标记状态上,我们一般使用的机会不多.
综上所述: 我们可以得到下面的一个结论:
0 <= mark <= position <= limit <= capacity.
其中capacity的属性是不变得,limit在切换读写状态的时候回发生变化,position在读写的时候回发生不断的变化.
四 .创建Buffer对象
我们首先看ByteBuffer的基本结构:
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>
我们发现这类是一个抽象类,也就是说我们无法初始化这个类的实例,一般这样的类都会有一个工厂方法帮助我们创建实例.
实际上这个方法就是allocate()方法.
public static ByteBuffer allocate(int capacity) { if (capacity < 0) throw new IllegalArgumentException(); return new HeapByteBuffer(capacity, capacity); }
我们看到实际上是创建了一个堆buffer对象,我们看看这个对象是什么.
class HeapByteBuffer extends ByteBuffer {
这个类实际上是ByteBuffer的内部类,描述的是堆内存上的ByteBuffer对象.
其实还有另外一个方法,
public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity); }
这个方法,创建了一个直接缓冲区.
现在我们看到了两个概念,一个就是直接缓冲区,另外一个就是非直接缓冲区.
这两者之间的区别涉及到零拷贝的概念,这个在后面会重点去论述.
另外,我们可以使用一个字节数组包装称为一个ByteBuffer对象,看下面的例子:
byte[] data = "heheh".getBytes(); ByteBuffer byteBuffer = ByteBuffer.wrap(data); System.out.println(byteBuffer.capacity()); // 5
这个方法比较简单,我们就不多说了.